15.1. သင်ခန်းစာ - Database မိတ်ဆက် (Lesson: Introduction to Databases)
PostgreSQL အသုံးမပြုခင်တွင် ယေဘုယျ database သီအိုရီအကြောင်း လေ့လာကြည့်ပါမည်။ ဥပမာပေးထားသော code များကို ရိုက်ထည့်စရာမလိုပါ၊ ၎င်းတို့သည် သာဓကပုံဖော်ပြသခြင်းအတွက်သာ ဖြစ်ပါသည်။
ဤသင်ခန်းစာအတွက် ရည်မှန်းချက်- အခြေခံ database သဘောတရားများကို နားလည်စေရန်။
15.1.1. Database တစ်ခုဆိုတာဘာလဲ (What is a Database?)
Database တစ်ခုသည် data များဖြင့် ဖွဲ့စည်းထားသော အစုအဖွဲ့တစ်ခုဖြစ်ပြီး ဒစ်ဂျစ်တယ်ပုံစံအနေဖြင့် ရှိပါသည်။ - Wikipedia
Database management system (DBMS) တစ်ခုတွင် database များကိုကိုင်တွယ်လုပ်ဆောင်နိုင်သော software များပါဝင်ပြီး data များသိုလှောင်ခြင်း၊ ရယူသုံးစွဲခြင်း၊ လုံခြုံစိတ်ချရမှု၊ backup နှင့် အခြားလုပ်ဆောင်နိုင်စရာများ ပါဝင်ပါသည်။ - Wikipedia
15.1.2. ဇယားများ (Tables)
Relational database များနှင့် flat file database များတွင် table တစ်ခုသည် ဒေါင်လိုက် column (အမည်များဖြင့်သတ်မှတ်ထားသော) များနှင့် ရေပြင်ညီ row များဖြင့် ဖွဲ့စည်းထားသော data element (တန်ဖိုးများ) များအစု တစ်ခုဖြစ်ပါသည်။ Table တစ်ခုတွင် သီးသန့် column အရေအတွက်ပါရှိပြီး row အရေအတွက် များစွာ ပါရှိနိုင်ပါသည်။ Row တစ်ခုချင်းစီကို သီးခြား column တစ်ခုထဲတွင်ပေါ်နေသော တန်ဖိုးများဖြင့် သတ်မှတ်ထားပါသည်။ - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
SQL database များတွင် table ကို relation ဟုလည်း ခေါ်ပါသည်။
15.1.3. Columns / Fields
Column တစ်ခုသည် သီးခြားအမျိုးအစားတစ်ခု၏ data တန်ဖိုးများအစု တစ်ခုဖြစ်ပါသည်။ Column များသည် row များဖွဲ့စည်းထားသည့်အတိုင်း structure ရှိပါသည်။ Field ဆိုသည့် အသုံးအနှုန်းကို column ဖြင့် အပြန်အလှန်အသုံးပြုပါသည်၊ row တစ်ခုနှင့် column တစ်ခု ဆုံရာတွင် ရှိသော item တစ်ခုကို သီးသန့်ရည်ညွှန်းရန်အတွက် field (သို့မဟုတ် field value) ဟုသုံးစွဲခြင်းသည် ပိုမိုမှန်ကန်သည်ဟု အများစုမှမှတ်ယူထားကြပါသည်။ - Wikipedia
Column တစ်ခု-
| name |
+-------+
| Tim |
| Horst |
Field တစ်ခု-
| Horst |
15.1.4. သိမ်းဆည်းထားမှုများ (Records)
Record တစ်ခုသည် table row တစ်ခုထဲတွင် သိမ်းဆည်းထားသော အချက်အလက်ဖြစ်ပါသည်။ Record တစ်ခုချင်းစီတွင် table ထဲရှိ column တစ်ခုချင်းစီအတွက် field တစ်ခုရှိပါသည်။
2 | Horst | 88 <-- one record
15.1.5. ဒေတာအမျိုးအစားများ (Datatypes)
Datatypes သည် column တစ်ခုထဲတွင် သိမ်းဆည်းနိုင်သော အချက်အလက်အမျိုးအစားကို ကန့်သတ်ပေးပါသည်။ - Tim and Horst
Datatypes အမျိုးအစား များစွာရှိပါသည်။ အသုံးအများဆုံးအရာများမှာ-
String- စာသား data များကို သိမ်းဆည်းရန်Integer- အပြည့်ကိန်းဂဏန်းများကို သိမ်းဆည်းရန်Real- ဒဿမဂဏန်းများကို သိမ်းဆည်းရန်Date- ရက်စွဲများကို သိမ်းဆည်းရန်Boolean- True/False တန်ဖိုးများကို သိမ်းဆည်းရန်
Field တစ်ခုထဲတွင် ဘာမှ မရှိသည့်အရာကို သိမ်းဆည်းရန် database ကိုပြောနိုင်ပါသည်။ Field တစ်ခုထဲတွင် ဘာမှမရှိလျှင် ‘null’ တန်ဖိုး အဖြစ် ဖော်ပြမည်ဖြစ်သည်-
insert into person (age) values (40);
select * from person;
Result:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
အသုံးပြုနိုင်သော datatypes များစွာ ရှိပါသေးသည် - PostgreSQL manual ကို ကြည့်ပါ!
15.1.6. လိပ်စာ Database တစ်ခုကို Model လုပ်ခြင်း (Modelling an Address Database)
Database တစ်ခု၏တည်ဆောက်ပုံကို မြင်တွေ့နိုင်ရန် ရိုးရှင်းသော case study တစ်ခုလုပ်ကြည့်ပါမည်။ လိပ်စာ database တစ်ခုကို ဖန်တီးလိုခြင်းဖြစ်သည်။
မိမိကိုယ်တိုင် ကြိုးစားကြည့်ပါ (Try Yourself:) ★☆☆
Database ထဲတွင် သိမ်းဆည်းလိုသည့် ရိုးရိုးလိပ်စာတစ်ခုတွင် ပါဝင်သော အချက်အလက်များကို ချရေးပါ။
အဖြေ
လိပ်စာဇယားအတွက် အောက်ပါ property များကို သိမ်းဆည်းလိုခြင်းဖြစ်ပါသည်:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
လိပ်စာတစ်ခုကို ကိုယ်စားပြုရန် ဇယားကို ဖန်တီးသောအခါ အဆိုပါ property တစ်ခုချင်းစီကို ကိုယ်စားပြုမည့် column များကို ဖန်တီးရမည်ဖြစ်ပြီး ၎င်းတို့ကို SQL နှင့်လိုက်လျောညီထွေဖြစ်သော အတိုကောက်အမည် များပေးရမည်ဖြစ်သည်:
house_number
street_name
suburb
city
postcode
country
လိပ်စာဖွဲ့စည်းပုံ (Address Structure)
လိပ်စာတစ်ခုကို ဖော်ပြသည့် property များသည် column များဖြစ်ကြပါသည်။ Column တစ်ခုချင်းစီတွင် သိမ်းဆည်းထားသော အချက်အလက်အမျိုးအစားသည် ၎င်း၏ datatype ဖြစ်သည်။ နောက်လာမည့်အပိုင်းတွင် လိပ်စာဇယားကို ပိုမိုကောင်းမွန်အောင် လုပ်ဆောင်ရန် ခွဲခြမ်းစိတ်ဖြာ ကြည့်ပါမည်။
15.1.7. Database သီအိုရီ (Database Theory)
Database တစ်ခုဖန်တီးခြင်း လုပ်ငန်းစဉ်တွင် real world model တစ်ခုဖန်တီးခြင်း၊ real world သဘောတရားများကိုရယူခြင်းနှင့် ၎င်းတို့ကို database ထဲတွင် entity များအဖြစ် ကိုယ်စားပြုဖော်ပြခြင်းများ ပါဝင်ပါသည်။
15.1.8. ပုံမှန်ဖြစ်စေခြင်း (Normalisation)
Database တစ်ခုထဲရှိ အဓိက idea များထဲမှ တစ်ခုသည် data များပုံတူပွားနေခြင်း (data duplication) / မလိုအပ်ပဲပိုလျှံနေခြင်း (redundancy) ကို ရှောင်ရှားရန်ဖြစ်ပါသည်။ Database တစ်ခုမှ redundancy များဖယ်ရှာခြင်းလုပ်ငန်းစဉ်ကို Normalisation ဟုခေါ်ဆိုပါသည်။
Normalization သည် data ၏ခိုင်မာမှုကို ဆုံးရှုံးစေနိုင်သည့် မလိုလားအပ်သော characteristics များမပါဝင်စေပဲ query လုပ်ဆောင်ခြင်းအတွက် သင့်တော်သော database structure တစ်ခုကိုရရှိစေသည့် စနစ်ကျသောနည်းလမ်းတစ်ခုဖြစ်ပါသည်။ - Wikipedia
Normalisation ပုံစံ အမျိုးမျိုးရှိပါသည်။
ရိုးရှင်းသော ဥပမာတစ်ခုကို ကြည့်ပါမည်-
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
သင့်တွင် လမ်းနာမည် သို့မဟုတ် မြို့နာမည် အတူတူဖြစ်သော သူငယ်ချင်းများရှိသည်ဆိုကြပါစို့။ ထို data ကို ပုံတူပွားသည့်အချိန်တိုင်း သိမ်းဆည်းရန် နေရာယူပါသည်။ ပိုဆိုးသည်မှာ မြို့နာမည်ကို ပြောင်းလဲလိုက်ပါက database ကို update လုပ်ရန် အလုပ်များစွာ လုပ်ရတော့မည်ဖြစ်သည်။
15.1.9. မိမိကိုယ်တိုင်ကြိုးစားကြည့်ပါ - (Try Yourself:) ★☆☆
အထက်ဖော်ပြပါ people table တွင် ပုံတူပွားနေသည်များကို လျှော့ချရန်နှင့် data structure ကို normalize ပြုလုပ်ရန် table ကို ဒီဇိုင်းပြန်ဆွဲပါ။
Database normalisation အကြောင်း ဤ တွင် ပိုမိုဖတ်ရှုနိုင်ပါသည်။
အဖြေ
people table နှင့်ပတ်သက်၍ အဓိကပြဿနာသည် လူတစ်ဦး၏ လိပ်စာတစ်ခုလုံးပါနေသည့် လိပ်စာ field တစ်ခုရှိနေခြင်းဖြစ်သည်။ address table တွင် လိပ်စာတစ်ခုကို property များစွာဖြင့် ဖွဲ့စည်းထားခြင်းဖြစ်သည် (အမည်၊ အိမ်နံပါတ်၊ လမ်းအမည်၊ အစရှိသဖြင့် သီးခြားစီရှိနေခြင်းဖြစ်သည်)။ အဆိုပါ property များအားလုံးကို field တစ်ခုထဲတွင် သိမ်းထားသည့်အတွက် data ကို update လုပ်ခြင်းနှင့် query လုပ်ရာတွင် များစွာအခက်အခဲဖြစ်စေပါသည်။ ထို့ကြောင့် ထိုလိပ်စာ field ကို property များစွာအဖြစ်သို့ ခွဲထုတ်ရန် လိုအပ်ပါသည်။ ထိုသို့ခွဲထုတ်ခြင်းဖြင့် အောက်ပါ structure အတိုင်း table တစ်ခုကို ရရှိပါလိမ့်မည်:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
နောက်လာမည့်အပိုင်းတွင် database structure တိုးတက်ကောင်းမွန်စေရန်အတွက် အသုံးပြုမည့် Foreign Key relationship များအကြောင်းကို လေ့လာရမည်ဖြစ်သည်။
15.1.10. အညွှန်းကိန်းများ (Indexes)
Database index တစ်ခုဆိုသည်မှာ database table တစ်ခုတွင် data များရယူခြင်းကို မြန်ဆန်စေသည့် data structure တစ်ခုဖြစ်ပါသည်။ - Wikipedia
သင်သည် textbook စာအုပ်တစ်ခုကို ဖတ်ရှုနေပြီး သဘောတရားတစ်ခု၏ရှင်းလင်းချက်ကို ရှာဖွေနေသည် ဆိုကြပါစို့၊ textbook တွင်လည်း index ကရှိမနေပါ။ ထိုအခါမျိုးတွင် သင်လိုချင်သော အချက်အလက်ကိုရှာတွေ့ရန် စာအုပ်အစမှနေပြီး စာအုပ်တစ်ခုလုံးကို ဖတ်ပြီး ရှာဖွေရပါလိမ့်မည်။ စာအုပ်တစ်အုပ်၏ index သည် သင့်တော်သောအချက်အလက်များရှိသည့် စာမျက်နှာကို မြန်ဆန်စွာ ရှာဖွေရောက်ရှိစေနိုင်ပါသည်-
create index person_name_idx on people (name);
Now searches on name will be faster:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. ကိန်းစဉ်များ (Sequences)
Sequence တစ်ခုသည် သီးသန့်ဖြစ်သော ဂဏန်းထုတ်ပေးသည့်အရာဖြစ်သည်။ ၎င်းကို ပုံမှန်အားဖြင့် table တစ်ခုထဲရှိ column တစ်ခုအတွက် သီးသန့်ဖြစ်သော identifier တစ်ခုဖန်တီးရာတွင် အသုံးပြုပါသည်။
ဤဥပမာတွင် id သည် sequence တစ်ခုဖြစ်ပါသည် - table ထဲသို့ record တစ်ခုထည့်သွင်းသည့်အချိန်တိုင်း ဂဏန်တန်ဖိုးတိုးသွားမည်ဖြစ်သည်-
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Entity Relationship Diagramming
Normalize ပြုလုပ်ထားသော database တစ်ခုထဲတွင် relation (table) များစွာ ရှိပါသည်။ Entity-relationship diagram (ER Diagram) ကို relation များအကြား မှီခိုနေမှု (dependency) ကို ဒီဇိုင်းပြုလုပ်ရာတွင် အသုံးပြုပါသည်။ သင်ခန်းစာထဲတွင် အစောပိုင်းက normalize မလုပ်ထားသော people table ကိုကြည့်ပါ-
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
လမ်းတစ်လမ်းထဲတွင် နေထိုင်သော တစ်ဦးချင်းစီအတွက် လမ်းနာမည်ကို ထပ်ခါထပ်ခါမရေးတော့ပဲ table နှစ်ခုအဖြစ်သို့ ပိုင်းခြားပေးနိုင်ပါသည်-
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
ထို့နောက်-
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
Table နှစ်ခုကို streets.id နှင့် people.streets_id ‘keys’ များကိုအသုံးပြုပြီး ချိတ်ဆက်ပေးနိုင်ပါသည်။
ထို table နှစ်ခုအတွက် ER Diagram တစ်ခုရေးဆွဲပါက အောက်ပါပုံစံဖြစ်ပါလိမ့်မည်-

ER Diagram သည် ‘one to many’ relationship ကိုဖော်ပြရာတွင် ကူညီပေးပါသည်။ ဤဥပမာတွင် မြားသင်္ကေတသည် လမ်းတစ်လမ်းထဲတွင် လူများစွာ နေထိုင်နိုင်သည်ကို ပြသခြင်းဖြစ်ပါသည်။
မိမိကိုယ်တိုင်ကြိုးစားကြည့်ပါ - (Try Yourself:) ★★☆
people model တွင် normalisation ပြဿနာအချို့ ရှိနေပါသေးသည်၊ ၎င်းကို နောက်ထပ် normalise ပြုလုပ်နိုင်သလား ကြိုးစားကြည့်ပြီး သင်စဉ်းစားထားသည်များကို ER Diagram ဖြင့်ပြသပါ။
အဖြေ
လက်ရှိတွင် people table သည် အောက်ပါပုံစံအတိုင်းဖြစ်ပါသည်:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
street_id column သည် people object နှင့် streets table ထဲရှိ ဆက်စပ် street object အကြား ‘one to many’ relationship တစ်ခုကိုကိုယ်စားပြုပါသည်။
Table ကို နောက်ထပ် normalise ပြုလုပ်မည့် နည်းတစ်နည်းသည် name field ကို first_name နှင့် last_name အဖြစ် ပိုင်းခြားရန်ဖြစ်သည်:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
Town သို့မဟုတ် city name နှင့် country အတွက် သီးခြား table များကိုလည်း ဖန်တီးပေးနိုင်ပြီး ၎င်းတို့ကို people table နှင့် ‘one to many’ relationship နည်းဖြင့် ချိတ်ဆက်ပေးနိုင်ပါသည်:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
၎င်းကို ဖော်ပြပေးမည့် ER Diagram သည် အောက်ပါပုံစံအတိုင်း ဖြစ်ပါလိမ့်မည်-
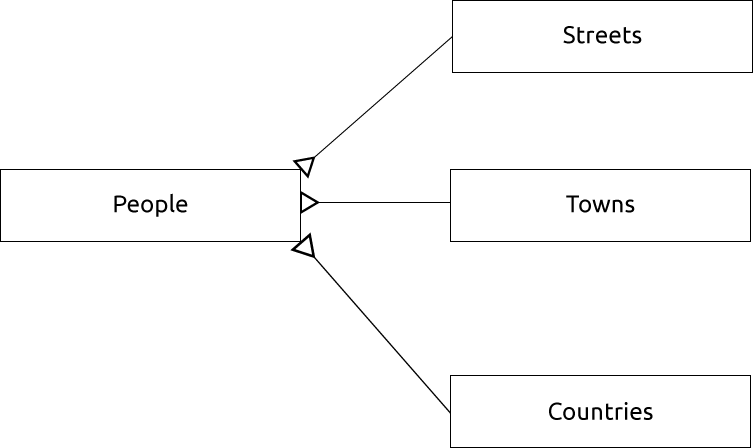
15.1.13. Constraints, Primary Keys and Foreign Keys
Relation တစ်ခုထဲရှိ data နှင့် modeller ၏ view ကိုက်ညီစေရန် database constraint တစ်ခုကို အသုံးပြုပါသည်။ ဥပမာ- postal code ပေါ်ရှိ constraint တစ်ခုသည် ဂဏန်းများကို 1000 နှင့် 9999 အကြားတွင်သာ ကျရောက်စေပါသည်။
Primary key သည် record ကို unique ဖြစ်စေနိုင်သည့် တစ်ခု သို့မဟုတ် တစ်ခုထက်ပိုသော field value များဖြစ်သည်။ များသောအားဖြင့် primary key ကို id ဟုခေါ်ပြီး sequence တစ်ခုဖြစ်ပါသည်။
အခြား table ရှိ unique record တစ်ခုကို ရည်ညွှန်းရန် Foreign key ကို အသုံးပြုပါသည် (အခြား table ၏ primary key ကိုအသုံးပြုလျှက်)။
ER Diagramming တွင် table များအကြား ချိတ်ဆက်မှုသည် Primary key များနှင့် ချိတ်ဆက်နေသော Foreign key များပေါ်တွင် အခြေခံပါသည်။
ဥပမာကိုကြည့်လျှင် table အဓိပ္ပါယ်ဖွင့်ဆိုချက်တွင် street column သည် foreign key တစ်ခုဖြစ်ပြီး strees table ပေါ်ရှိ primary key ကို အကိုးအကားပြုထားပါသည်-
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transactions
Database တစ်ခုထဲတွင် data များထည့်သွင်းခြင်း၊ ပြောင်းလဲခြင်း သို့မဟုတ် ဖျက်ပစ်ခြင်းများ ပြုလုပ်သောအခါ database သည် ကောင်းမွန်သောအခြေအနေတွင် ကျန်ရှိနေစေရန် အရေးကြီးပါသည်။ Database အများစုတွင် transaction support ဟုခေါ်သော feature တစ်ခုပါရှိပါသည်။ Database တွင် ပြောင်းလဲမှုလုပ်ဆောင်ပြီး စီစဉ်ထားသလိုဖြစ်မလာပါက မူလအခြေအနေသို့ပြန်သွားနိုင်သော rollback position တစ်ခုကို Transaction များမှ ဖန်တီးပေးစေနိုင်ပါသည်။
သင့်တွင် ငွေကြေးစနစ်တစ်ခုရှိသည်ဟု ယူဆကြည့်ပါ။ သင်သည် အကောင့် တစ်ခုမှ ငွေများကို နောက်ထပ်အကောင့်တစ်ခုသို့ လွှဲပြောင်းရန်လိုအပ်ပါသည်။ လုပ်ငန်းစဉ်အဆင့်များမှာ အောက်ပါအတိုင်းဖြစ်ပါသည်-
Joe ထံမှ R20 နှုတ်ယူလိုက်ပြီး
Anne ထံသို့ R20 ထည့်သွင်းပေးမည်
လုပ်ဆောင်နေစဉ်အတွက် တစ်ခုခုအမှားအယွင်းဖြစ်ခဲ့ပါက (ဥပမာ- ပါဝါပြတ်တောက်မှု) transaction သည် roll back (နောက်ပြန်သွား) ဖြစ်ပါလိမ့်မည်။
15.1.15. နိဂုံးချုပ် (In Conclusion)
Database များသည် ရိုးရှင်းသော code structure များကိုအသုံးပြုပြီး ဖွဲ့စည်းပုံရှိသောနည်းလမ်းဖြင့် data များကို စီမံခန့်ခွဲစေနိုင်ပါသည်။
15.1.16. နောက်ထပ်ဘာအကြောင်းအရာလဲ (What’s Next?)
ယခုအခါ သီအိုရီအရ database များ၏ အလုပ်လုပ်ပုံကို သိရှိခဲ့ရပြီးဖြစ်သည်။ သီအိုရီကို အကောင်အထည်ဖော်ရန် database အသစ်တစ်ခုကို ဖန်တီးကြည့်ကြပါမည်။