17.23. နောက်ထပ် သွယ်ဝိုက်တွက်ချက်ခြင်းနည်းများ (More interpolation)
Note
ဤသင်ခန်းစာတွင် interpolation algorithm များကိုအသုံးပြုထားသော အခြားလက်တွေ့လုပ်ငန်းတစ်ခုကို ပြသပေးမည်ဖြစ်ပါသည်။
Interpolation သည် အသုံးများသော နည်းတစ်ခုဖြစ်ပြီး QGIS processing framework အသုံးပြုကာ လုပ်ဆောင်နိုင်သော နည်းစနစ်များစွာကို သရုပ်ဖော်ပြသရာတွင်အသုံးပြုနိုင်ပါသည်။ ယခင်က မိတ်ဆက်ပေးထားပြီးသော interpolation algorithm အချို့ကို မတူညီသောနည်းလမ်းဖြင့် ဤသင်ခန်းစာတွင် အသုံးပြုသွားပါမည်။
ဤသင်ခန်းစာအတွက် data တွင် elevation data များပါဝင်သော point layer တစ်ခုပါဝင်ပါသည်။ ယခင်သင်ခန်းစာတွင်လုပ်ဆောင်ခဲ့သည့်နည်းအတိုင်း ထို point data များကို interpolate ပြုလုပ်ပါမည်၊ သို့သော် ဤတစ်ကြိမ်တွင် interpolation လုပ်ငန်းစဉ်၏ အရည်အသွေးကို ဆန်းစစ်ရန်အတွက် မူရင်း data ၏ တစ်စိတ်တစ်ပိုင်းကို သိမ်းထားပါမည်။
ပထမဦးစွာ point layer ကို raster အဖြစ်သို့ပြောင်းလဲရမည်ဖြစ်ပြီး ရလာဒ် no–data cell များကို ဖြည့်ရပါမည်၊ သို့သော် layer ထဲရှိ point တစ်စိတ်တစ်ပိုင်းကိုသာ အသုံးပြုပါမည်။ Point များ၏ ၁၀ ရာခိုင်နှုန်းကို နောက်ပိုင်းတွင်စစ်ဆေးမှုတစ်ခုပြုလုပ်ရန်အတွက် သိမ်းထားပါမည်၊ ထို့ကြောင့် interpolation အတွက် ၉၀ ရာခိုင်နှုန်းရှိရန်သာ လိုအပ်ပါသည်။ ထိုသို့လုပ်ဆောင်ရန် ယခင်သင်ခန်းစာတွင်အသုံးပြုခဲ့သော Split shapes layer randomly algorithm ကိုအသုံးပြုနိုင်ပါသည်၊ သို့သော် intermediate layer အသစ်တစ်ခုဖန်တီးရန်မလိုအပ်သည့် ပိုကောင်းသောနည်းတစ်ခုရှိပါသည်။ Interpolation အတွက် အသုံးပြုလိုသော point များ (၉၀ %) ကိုသာ select လုပ်ပြီးနောက် algorithm ကို run နိုင်ပါသည်။ Rasterize algorithm သည် select ပြုလုပ်ထားသော point များကိုသာ အသုံးပြုမည်ဖြစ်ပြီး ကျန် point များကို လျစ်လျူရှုထားမည်ဖြစ်ပါသည်။ Select ပြုလုပ်ခြင်းကို Random selection algorithm အသုံးပြုပြီး လုပ်ဆောင်နိုင်ပါသည်။ ထို algorithm ကို အောက်ပါ parameter များဖြင့် run ပါ။
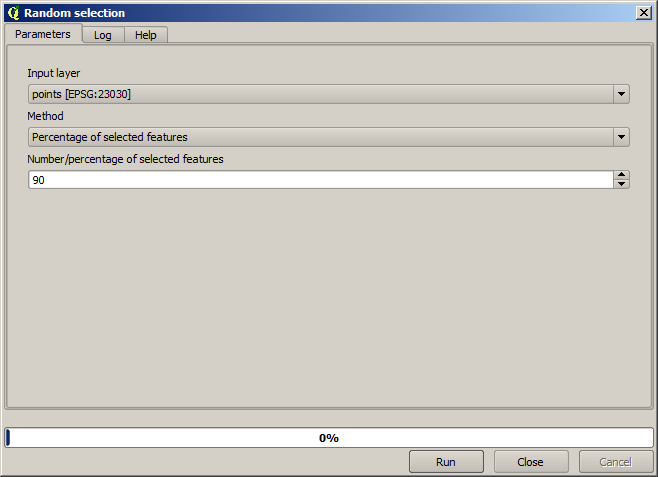
Algorithm သည် raster ပြောင်းလဲမည့် layer ထဲရှိ point များ၏ ၉၀ ရာခိုင်နှုန်းကို select လုပ်ပေးပါလိမ့်မည်။

Select ပြုလုပ်ခြင်းသည် ကျပန်းဖြစ်ပါသည်၊ ထို့ကြောင့် သင်လုပ်ဆောင်သည့် selection သည် အထက်တွင်ပြထားသောပုံနှင့် ကွဲပြားနိုင်ပါသည်။
ယခုအခါ ပထမဦးဆုံး raster layer ကိုရရှိရန် Rasterize algorithm ကို run ပါ၊ ထို့နောက် no–data cell များကို ဖြည့်ရန် Close gaps algorithm ကို run ပါ [Cell resolution: 100 မီတာ]။

Interpolation ၏ အရည်အသွေးကို စစ်ဆေးရန် select မပြုလုပ်ထားသော point များကို အသုံးပြုနိုင်ပြီဖြစ်ပါသည်။ ဤအဆင့်တွင် elevation တန်ဖိုးအမှန် (point layer ထဲရှိ တန်ဖိုး) နှင့် interpolate လုပ်ဆောင်ထားသော elevation တန်ဖိုး (interpolate လုပ်ထားသော raster layer ထဲရှိ တန်ဖိုး) များကို သိရှိပြီဖြစ်ပါသည်။ အဆိုပါ တန်ဖိုးများအကြား ခြားနားချက်ကို တွက်ချက်ခြင်းဖြင့် နှိုင်းယှဉ်ကြည့်နိုင်ပါသည်။
Select မပြုလုပ်ထားသော point များကိုအသုံးပြုမည်ဖြစ်သောကြောင့် ပထမဦးစွာ ယခင်ပြုလုပ်ထားသော selection ကို ပြောင်းပြန်လုပ်လိုက်ပါမည်။

Point များတွင်ပါဝင်သောတန်ဖိုးများသည် မူရင်းတန်ဖိုးများဖြစ်ပြီး interpolate ပြုလုပ်ထားသောတန်ဖိုးများမဟုတ်ပါ။ ၎င်းတန်ဖိုးများကို field အသစ်တစ်ခုထဲတွင် ထည့်သွင်းရန် Add raster values to points algorithm ကိုအသုံးပြုနိုင်ပါသည်။
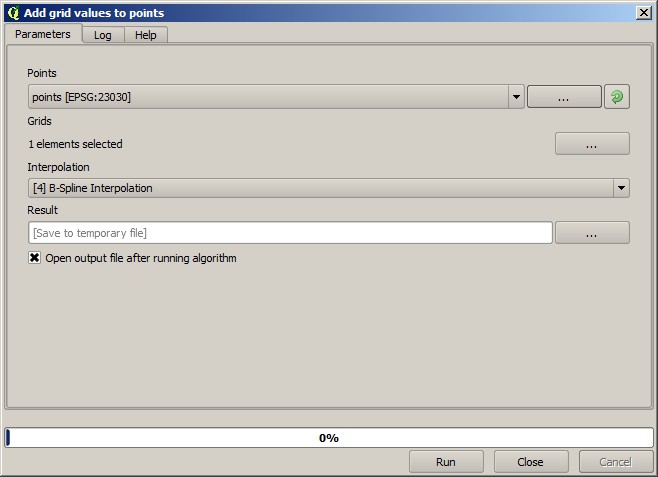
Select ပြုလုပ်မည့် raster layer (algorithm သည် raster များစွာကို လုပ်ဆောင်နိုင်ပါသည်၊ သို့သော် တစ်ခုသာ လိုအပ်ပါသည်) သည် interpolation မှ ရလာဒ် layer ဖြစ်ပါသည်။ Layer ကို interpolate ဟုအမည်ပြောင်းထားပြီး ထို layer နာမည်ကို ထည့်သွင်းရမည့် field နာမည်အတွက် အသုံးပြုမည်ဖြစ်ပါသည်။
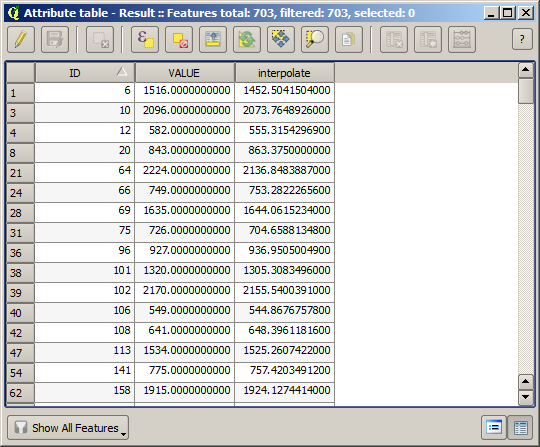
ယခုအခါ တန်ဖိုးနှစ်ခုစလုံးပါရှိသော vector layer တစ်ခုကို ရရှိပြီဖြစ်ပါသည်။ Interpolation အတွက် အသုံးမပြုခဲ့သော point ၁၀ ရာခိုင်နှုန်းပါ ပါဝင်ပါသည်။
ခြားနားချက်ကို စစ်ဆေးရန်အတွက် Field calculator algorithm ကိုဖွင့်ပြီး အောက်ပါ parameter များဖြင့် run ပါ။
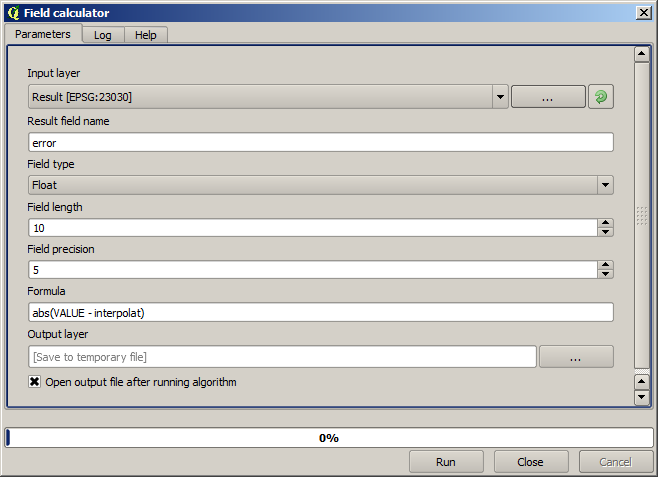
Raster layer မှ တန်ဖိုးများပါဝင်သော field နာမည်သည် အခြားနာမည်တစ်ခုဖြစ်နေပါက အထက်ဖော်ပြပါ formula တွင် လိုက်လျောညီထွေ ပြင်ပေးသင့်ပါသည်။ Algorithm ကို run ပါက interpolation အတွက်အသုံးမပြုခဲ့သော point များသာပါရှိသော layer အသစ်တစ်ခုကို ရရှိပါလိမ့်မည်၊ ၎င်းတို့တစ်ခုချင်းစီတွင် elevation တန်ဖိုးများ နှစ်ခုအကြား ခြားနားချက်ပါဝင်မည်ဖြစ်ပါသည်။
ခြားနားချက်တန်ဖိုးဖြင့် layer ကို ဖော်ပြခြင်းသည် မည်သည့်နေရာများတွင် ကွာဟချက် အကြီးမားဆုံးဖြစ်နေသည်ကို သိရှိနိုင်ပါသည်။
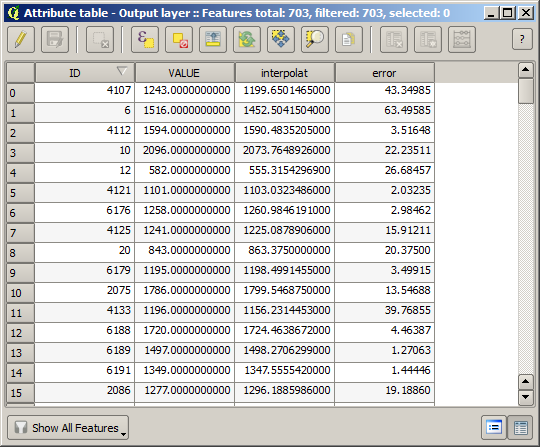
ထို layer ကို interpolate ပြုလုပ်ခြင်းသည် interpolate ပြုလုပ်ထားသောဧရိယာ၏ point များအားလုံးရှိ ခန့်မှန်းအမှား (estimated error) များပါဝင်သော raster layer တစ်ခုကို ရရှိစေပါသည်။
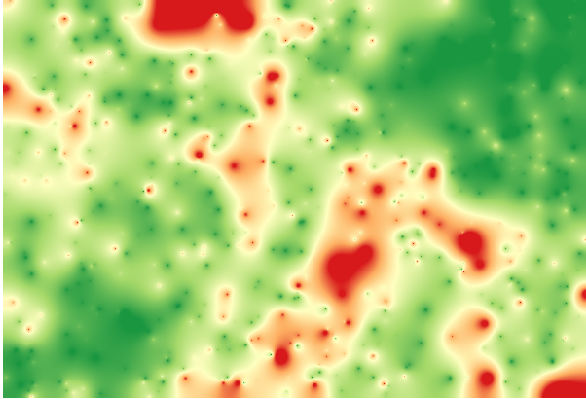
ထိုကဲ့သို့သော အချက်အလက် (မူရင်း point တန်ဖိုးများနှင့် interpolate ပြုလုပ်ထားသောတန်ဖိုးများ ခြားနားချက်) ကို ဖြင့်လည်း တိုက်ရိုက်တွက်ထုတ်နိုင်ပါသည်။
ဤသင်ခန်းစာ၏အစတွင် ပြုလုပ်ခဲ့သော random selection algorithm ကို run သောအခါ ကျပန်းဖြစ်သောကြောင့် သင်ရရှိသော ရလာဒ်များသည် ယခုဖော်ပြပါရလာဒ်များနှင့် ကွဲပြားနိုင်ပါသည်။