29.1.15. Vector ဆန်းစစ်လေ့လာခြင်း (Vector analysis)
29.1.15.1. Filed များ၏ အခြေခံကိန်းဂဏန်းအချက်အလက်များ (Basic statistics for fields)
Vector layer တစ်ခု၏ attribute ဇယားမှ field တစ်ခုအတွက် အခြေခံကိန်းဂဏန်းအချက်အလက်များကို ထုတ်ပေးပါသည်။
ကိန်းဂဏန်း၊ ရက်စွဲ၊ အချိန်နှင့် စာသား field များကို အသုံးပြုနိုင်မည်ဖြစ်သည်။
ရရှိလာသော ကိန်းဂဏန်းအချက်အလက်များသည် field အမျိုးအစားပေါ်တွင်မူတည်မည်ဖြစ်သည်။
ကိန်းဂဏန်းအချက်အလက်များကို HTML ဖိုင်တစ်ခုအနေဖြင့် ထုတ်ပေးပြီး မှတစ်ဆင့်ကြည့်ရှုနိုင်မည်ဖြစ်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input vector (ထည့်သွင်းအသုံးပြုသော vector) |
|
[vector: any] |
ကိန်းဂဏန်းအချက်အလက်များ တွက်ချက်ပေးမည့် vector layer |
Field to calculate statistics on (ကိန်းဂဏန်းအချက်အလက်များ တွက်ချက်ပေးရမည့် Field) |
|
[tablefield: any] |
ကိန်းဂဏန်းအချက်အလက်များ တွက်ချက်မည့် အသုံးပြုနိုင်သည့် ဇယား field တစ်ခုခု |
Statistics (ကိန်းဂဏန်းအချက်အလက်များ) Optional |
|
[html] Default: |
တွက်ချက်ထားသော ကိန်းဂဏန်းအချက်အလက်များအတွက် file အမျိုးအစား သီးခြားသတ်မှတ်ခြင်း။ အောက်ပါတို့ထဲမှ တစ်ခုခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Statistics (ကိန်းဂဏန်းအချက်အလက်များ) |
|
[html] |
တွက်ချက်ထားသော ကိန်းဂဏန်းအချက်အလက်များပါရှိသည့် HTML file |
Count (အရေအတွက်) |
|
[number] |
|
Number of unique values (သီးခြားထင်ရှားသည့် တန်ဖိုးများ၏ အရေအတွက်) |
|
[number] |
|
Number of empty (null) values (ဗလာ (null) တန်ဖိုးများ၏ အရေအတွက်) |
|
[number] |
|
Number of non-empty values (ဗလာမဟုတ်သော တန်ဖိုးများ၏ အရေအတွက်) |
|
[number] |
|
Minimum value (အနည်းဆုံးတန်ဖိုး) |
|
[input နှင့်အတူတူပင်ဖြစ်သည်] |
|
Maximum value (အများဆုံးတန်ဖိုး) |
|
[input နှင့်အတူတူပင်ဖြစ်သည်] |
|
Minimum length (အနည်းဆုံးအလျား) |
|
[number] |
|
Maximum length (အများဆုံးအလျား) |
|
[number] |
|
Mean length (ပျမ်းမျှ အလျား) |
|
[number] |
|
Coefficient of Variation (ပြောင်းလဲမှုပြကိန်း) |
|
[number] |
|
Sum (ပေါင်းလဒ်) |
|
[number] |
|
Mean value (ပျမ်းမျှတန်ဖိုး) |
|
[number] |
|
Standard deviation (စံတိမ်းချက်) |
|
[number] |
|
Range (အပိုင်းအခြား) |
|
[number] |
|
Median (တစ်ဝက်ကိန်း) |
|
[number] |
|
Minority (rarest occurring value) (အနည်းစု (အနည်းဆုံးတွေ့ရသည့်တန်ဖိုးများ)) |
|
[input နှင့်အတူတူပင်ဖြစ်သည်] |
|
Majority (most frequently occurring value) (အများစု (အများဆုံးတွေ့ရသည့်တန်ိဖုးများ)) |
|
[input နှင့်အတူတူပင်ဖြစ်သည်] |
|
First quartile (ဒေတာတစ်ခု၏ ပထမလေးပုံတစ်ပုံ/၂၅ ရာခိုင်နှုန်း) |
|
[number] |
|
Third quartile (ဒေတာတစ်ခု၏ တတိယလေးပုံတစ်ပုံ/၇၅ ရာခိုင်နှုန်း) |
|
[number] |
|
Interquartile Range (IQR) (ဒေတာ၏အလယ်တစ်ဝက်တွင် ပြန့်နှံ့မှု) |
|
[number] |
Python code
Algorithm ID: qgis:basicstatisticsforfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.2. မျဉ်းတစ်လျှောက် အမြင့်ပြောင်းလဲမှုများ တွက်ချက်ခြင်း (Climb along line)
Line ဂျီဩမေတြီများ တစ်လျှောက်ရှိ စုစုပေါင်း အတက် (climb) နှင့် အဆင်း (descent) ကိုတွက်ချက်ပေးပါသည်။ Input layer တွင် အမြင့်တန်ဖိုးများ (Z တန်ဖိုးများ) ရှိရပါမည်။ အကယ်၍ Z တန်ဖိုးများကိုမရနိုင်လျှင် ၎င်းတို့ကို Digital Elevation Model (DEM) layer တစ်ခုမှ ထည့်သွင်းရန် Drape (Raster မှ အမြင့် Z တန်ဖိုးကိုသတ်မှတ်ခြင်း) (Drape(set Z value from raster) ကို အသုံးပြုနိုင်ပါသည်။
Output layer သည် line ဂျီဩမေတြီတစ်ခုစီအတွက် စုစုပေါင်းအတက် (climb)၊ စုစုပေါင်းအဆင်း (descent)၊ အနိမ့်ဆုံး အမြင့် (minelev)နှင့် အမြင့်ဆုံး အမြင့် (maxelev) တို့ပါရှိသော ထပ်ဆောင်း field များပါဝင်သည့် input layer ၏ မိတ္တူတစ်ခုဖြစ်ပါသည်။ Input layer တွင် ထိုပေါင်းထည့်သော field များနှင့် အမည်တူများပါရှိနေပါက နှစ်ခုထပ်နေခြင်းကိုရှောင်ရှားနိုင်ရန် ၎င်းတို့ကို အမည်ပြန်လည်ပေးမည်ဖြစ်သည် (field အမည်များထဲမှ ပထမဆုံး မထပ်သည့်အမည်ကိုရှာပေးမည်ဖြစ်ပြီး field အမည်များကို “name_2”၊ “name_3”၊ အစရှိသည်ဖြင့် ပြောင်းလဲလိုက်မည်ဖြစ်သည်)။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Line layer (မျဉ်း layer) |
|
[vector: line] |
အတက် (climb) ကို တွက်ချက်ရမည့် line layer။ အမြင့် Z တန်ဖိုးများရှိရမည်။ |
Climb layer (Climb တွက်ချက်ထားသည့် layer) |
|
[vector: line] Default: |
Output (မျဉ်း) layer ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Climb layer (Climb တွက်ချက်ထားသည့် layer) |
|
[vector: line] |
Climb တွက်ချက်ခြင်းမှရလာဒ်များဖြင့် attribute အသစ်များပါဝင်သည့် line layer |
Total climb (စုစုပေါင်း အတက်) |
|
[number] |
Input layer ထဲရှိ line ဂျီဩမေတြီအားလုံးအတွက် စုစုပေါင်း အတက် |
Total descent (စုစုပေါင်း အဆင်း) |
|
[number] |
Input layer ထဲရှိ line ဂျီဩမေတြီအားလုံးအတွက် စုစုပေါင်း အဆင်း |
Minimum elevation (အနိမ့်ဆုံး အမြင့်) |
|
[number] |
Layer ထဲရှိ ဂျီဩမေတြီ များအတွက် အနိမ့်ဆုံး အမြင့် |
Maximum elevation (အမြင့်ဆုံး အမြင့်) |
|
[number] |
Layer ထဲရှိ ဂျီဩမေတြီ များအတွက် အမြင့်ဆုံး အမြင့် |
Python code
Algorithm ID: qgis:climbalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.3. Polygon အတွင်းရှိ point များကိုရေတွက်ခြင်း (Count points in polygon)
Point layer တစ်ခုနှင့် polygon layer တစ်ခုကိုယူပြီး polygon layer ၏ polygon တစ်ခုချင်းစီထဲရှိသော point များ၏အရေအတွက်ကို ရေတွက်ပေးပါသည်။
Input polygon layer နှင့် တူညီသော အကြောင်းအရာရှိပြီး polygon တစ်ခုစီနှင့်သက်ဆိုင်သော point အရေအတွက်များကိုပြသပေးသည့် field တစ်ခုပါရှိသော polygon layer အသစ် တစ်ခုကိုထုတ်ပေးမည်ဖြစ်ပါသည်။
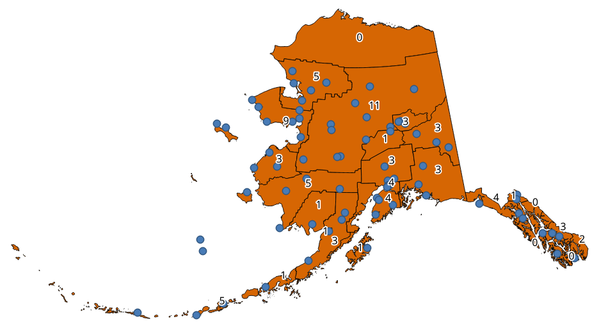
Fig. 29.31 Polygon များထဲရှိ အညွှန်းများသည် point အရေအတွက်ကိုပြပေးသည်။
Point တစ်ခုစီတွင် အလေးပေးတန်ဖိုးများ (weight) ကိုသတ်မှတ်ရန် weight field တစ်ခုကိုအသုံးပြုနိုင်သည်။ တနည်းအားဖြင့် ကွဲပြားထင်ရှားသော အတန်းအစား (unique class) field တစ်ခုကိုလည်းသတ်မှတ်ထားနိုင်သည်။ အကယ်၍ option နှစ်ခုစလုံးကိုအသုံးပြုထားလျှင် point များရေတွက်ရာ၌ unique class field ထက် weight field ကိုဦးစားပေးအသုံးပြုမည်ဖြစ်သည်။
 ကိုအမှန်ခြစ်ပေးထားခြင်းဖြင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ရွေးချယ်ခွင့်ကိုအသုံးပြုနိုင်သည်။
ကိုအမှန်ခြစ်ပေးထားခြင်းဖြင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ရွေးချယ်ခွင့်ကိုအသုံးပြုနိုင်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Polygons |
|
[vector: polygon] |
၎င်းတို့ထဲပါဝင်သော point အရေအတွက်နှင့်ဆက်စပ်သော feature များပါရှိသည့် polygon layer |
Points |
|
[vector: point] |
ရေတွက်ရမည့် feature များပါဝင်သည့် point layer |
Weight field (အလေးပေးမှု field) Optional |
|
[tablefield: any] |
Point layer မှ field တစ်ခု။ ရရှိလာသောအရေတွက်သည် polygon အတွင်းရှိ point များအားလုံး၏ weight field စုစုပေါင်း ဖြစ်လိမ့်မည်။ အကယ်၍ weight field သည် ကိန်းဂဏန်းတန်ဖိုးမဟုတ်ပါက အရေအတွက်သည် |
Class field (အတန်းအစား field) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] |
ရွေးချယ်ထားသော attribute အပေါ် အခြေခံ၍ point များကို အတန်းအစားခွဲခြားမည်ဖြစ်ပြီး အကယ်၍ attribute တန်ဖိုးအတူတူရှိသည့် point များစွာသည် polygon အတွင်း ရှိနေပါက ၎င်းတို့ထဲမှ တစ်ခုကိုသာ ရေတွက်မည်ဖြစ်သည်။ ထို့ကြောင့် polygon တစ်ခုအတွင်းရှိ point များ၏ နောက်ဆုံး အရေအတွက်သည် ၎င်း polygon ထဲတွင်တွေ့ရသော အမျိုးမျိုးသော အတန်းအစားများ၏ အရေအတွက်ပင်ဖြစ်သည်။ |
Count field name (အရေအတွက် field အနည်) |
|
[string] Default: ‘NUMPOINTS’ |
Point များ၏ အရေအတွက်ကို သိမ်းဆည်းမည့် field ၏အမည် |
Count (အရေအတွက်) |
|
[vector: polygon] Default: |
Output layer ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Count (အရေအတွက်) |
|
[vector: polygon] |
Point များအရေအတွက်ကိုပြသသော column အသစ်ဖြင့် attribute ဇယား ပါရှိသည့် ရလာဒ် layer |
Python code
Algorithm ID: native:countpointsinpolygon
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.4. DBSCAN ဖြင့်စုဖွဲ့ခြင်း (DBSCAN clustering)
DBSCAN (Density-based spatial clustering of applications with noise) algorithm အား နှစ်ဘက်မြင် (2D) လုပ်ဆောင်မှုပေါ်အခြေခံ၍ point feature များကို cluster (စုဖွဲ့) ပြုလုပ်ပေးပါသည်။
ဤ algorithm တွင် parameter နှစ်ခု ဖြစ်သော အငယ်ဆုံး စုဖွဲ့မှု အရွယ်အစား (minimum cluster size) နှင့် စုဖွဲ့ထားသော point များကြား ခွင့်ပြုနိုင်မည့် အများဆုံးအကွာအဝေး အားသတ်မှတ် ထားရှိရန်လိုအပ်သည်။
See also
ST-DBSCAN ဖြင့် စုဖွဲ့ခြင်း (ST-DBSCAN clustering) ၊ K-means နည်းလမ်းဖြင့် စုဖွဲ့ခြင်း (K-means clustering)
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: point] |
ဆန်းစစ်လေ့လာမည့် Layer |
Minimum cluster size (အငယ်ဆုံး စုဖွဲ့မှု အရွယ်အစား) |
|
[number] Default: 5 |
Cluster တစ်ခု စုဖွဲ့ရာတွင် လိုအပ်သော အနည်းဆုံး feature များ၏အရေအတွက် |
Maximum distance between clustered points (စုဖွဲ့ထားသော point များကြား အများဆုံးအကွာအဝေး) |
|
[number] Default: 1.0 |
ယခုသတ်မှတ်မည့်အကွာအဝေးကို ကျော်လွန်၍ feature နှစ်ခုသည် တူညီသော cluster (eps) နှင့်သက်ဆိုင်မှုမရှိစေနိုင်ပါ။ |
Clusters (အစုအဖွဲ့များ) |
|
[vector: point] Default: |
စုဖွဲ့ခြင်းရလာဒ်အတွက် vector layer သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Treat border points as noise (DBSCAN*) (အနားသတ်ဘောင်များပေါ်ရှိ point များကို noise အဖြစ်စဉ်းစားခြင်း) Optional |
|
[boolean] Default: False |
အမှန်ခြစ်ပေးထားပါက cluster တစ်ခု၏ အနားသတ်ဘောင်များပေါ်ရှိ point များကို စုဖွဲ့ခြင်းမလုပ်ထားသော point များအဖြစ်သတ်မှတ်မည်ဖြစ်ပြီး cluster တစ်ခု၏အတွင်းရှိ point များကိုသာလျှင် စုဖွဲ့ထားသည်များအဖြစ် သတ်မှတ်မည်ဖြစ်သည်။ |
Cluster field name (Cluster field ၏အမည်) |
|
[string] Default: ‘CLUSTER_ID’ |
သက်ဆိုင်ရာ cluster နံပါတ်ကို သိမ်းဆည်းထားပေးမည့် field ၏အမည် |
Cluster size field name (Cluster အရွယ်အစားအတွက် field ၏အမည်) |
|
[string] Default: ‘CLUSTER_SIZE’ |
တူညီသော cluster ထဲရှိ feature များ၏အရေအတွက်ပါရှိသော field ၏အမည် |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Clusters (အစုအဖွဲ့များ) |
|
[vector: point] |
မူရင်း feature များအပြင် ၎င်းတို့ သက်ဆိုင်သော cluster field တစ်ခု ပါရှိသော vector layer |
Number of clusters (Cluster များ၏အရေအတွက်) |
|
[number] |
တွေ့ရှိရသော cluster များအရေအတွက် |
Python code
Algorithm ID: native:dbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.5. အကွာအဝေး မက်ထရစ် (Distance matrix)
Point feature များအတွက် တူညီသော layer ထဲရှိ သို့မဟုတ် အခြား layer ထဲရှိ ၎င်း point feature များနှင့်အနီးဆုံး feature များသို့ အကွာအဝေးကို တွက်ချက်ပေးပါသည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input point layer (ထည့်သွင်းအသုံးပြုသော point layer) |
|
[vector: point] |
အကွာအဝေး မက်ထရစ် အားတွက်ချက်ရန်အတွက် point layer (point များ မှ ) |
Input unique ID field (ထည့်သွင်းအသုံးပြုသော သိသာထူးခြားသည့် ID field) |
|
[tablefield: any] |
Input layer ၏ feature များကို သီးသန့်ခွဲခြားသတ်မှတ်ရန် အသုံးပြုသည့် field ။ ၎င်းကို output attribute ဇယားတွင် အသုံးပြုမည်ဖြစ်သည်။ |
Target point layer (ဦးတည်သော point layer) |
|
[vector: point] |
ရှာဖွေရမည့် အနီးဆုံး အမှတ် (များ) ပါဝင်သော အမှတ် layer (အမှတ်များ သို့ ) |
Target unique ID field (ဦးတည်သော သိသာထူးခြားသည့် ID field) |
|
[tablefield: any] |
ဦးတည်ရာ (Target) layer ၏ feature များကို သီးခြားခွဲခြားသတ်မှတ်ရန် အသုံးပြုမည့် Field ။ ၎င်းကို output attribute ဇယားတွင် အသုံးပြုသည်ဖြစ်သည်။ |
Output matrix type (ရလာဒ် မက်ထရစ်အမျိုးအစား) |
|
[enumeration] Default: 0 |
အကွာအဝေးကိုတွက်ချက်ရန် နည်းလမ်းအမျိုးမျိုးမှာ-
|
Use only the nearest (k) target points (အနီးဆုံး (k) ဦးတည်ရာ point များကိုသာ အသုံးပြုပါ) |
|
[number] Default: 0 |
Target layer (0) ထဲရှိ point များအားလုံးသို့ အကွာအဝေးကို တွက်ချက်ရန် ရွေးချယ်နိုင်သလို အနီးစပ်ဆုံး feature များ၏ အရေအတွက် (k) သို့ ကန့်သတ်ရန် ရွေးချယ်နိုင်ပါသည်။ |
Distance matrix (အကွာအဝေး မက်ထရစ်) |
|
[vector: point] Default: |
Output vector layer ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Distance matrix (အကွာအဝေး မက်ထရစ်) |
|
[vector: point] |
Input feature တစ်ခုစီအတွက် အကွာအဝေး တွက်ချက်မှုများ ပါဝင်သော point (သို့မဟုတ် “Linear (N * k x 3)” အတွက် MultiPoint) vector layer ။ ၎င်း၏ feature များနှင့် attribute ဇယားသည် ရွေးချယ်ထားသော output မက်ထရစ်အမျိုးအစားပေါ်တွင်မူတည်ပါသည်။ |
Python code
Algorithm ID: qgis:distancematrix
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.6. ဗဟိုချက် သို့အကွာအဝေး (မျဉ်းမှ ဗဟိုချက် ဆီသို့) (Distance to nearest hub (line to hub))
Input layer တစ်ခု၏ feature တစ်ခုစီနှင့် ဦးတည်ရာ layer ထဲရှိ အနီးဆုံး feature သို့ ချိတ်ဆက်သည့် မျဉ်းများကို ဖန်တီးပေးပါသည်။ အကွာအဝေးများကို feature တစ်ခုစီ၏ center ပေါ်တွင်အခြေခံ၍ တွက်ချက်သည်။
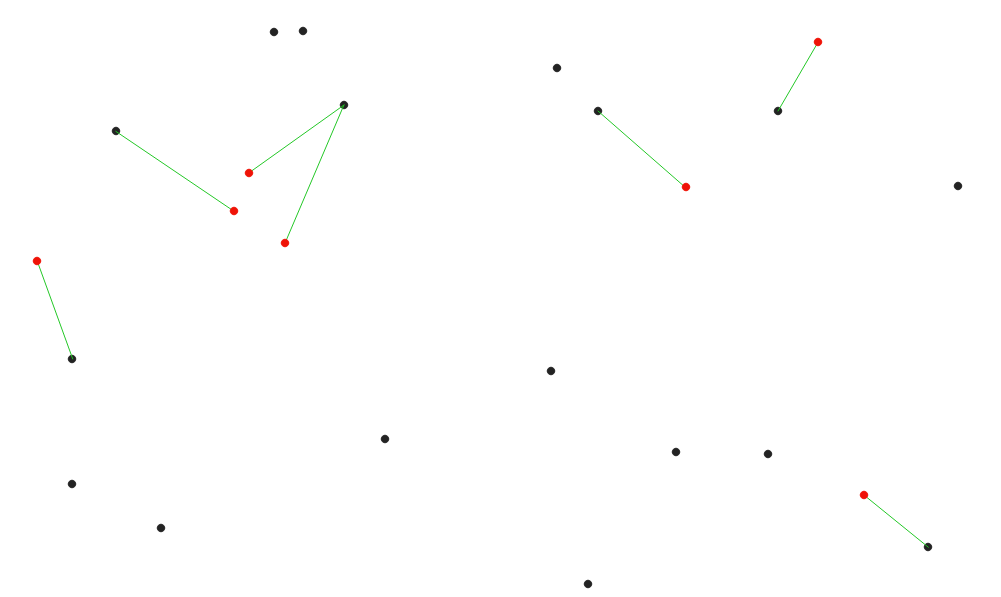
Fig. 29.32 အနီရောင် input feature များအတွက် အနီးဆုံးသော hub ကိုပြသပေးသည်။
See also
ဗဟိုချက် သို့အကွာအဝေး (အမှတ်များ) (Distance to nearest hub (points)) ၊ နီးစပ်မှုဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (Join attributes by nearest)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Source points layer (ရင်းမြစ် point များ layer) |
|
[vector: any] |
အနီးဆုံး feature အားရှာဖွေရာတွင်သုံးသည့် vector layer |
Destination hubs layer (ဦးတည်ရာ ဗဟိုချက် layer) |
|
[vector: any] |
ရှာဖွေရမည့် feature များပါဝင်နေသော vector layer |
Hub layer name attribute (Hub layer အမည် attribute) |
|
[tablefield: any] |
ဦးတည်ရာ layer ရှိ feature များကို သီးခြားခွဲခြားသတ်မှတ်ရန် အသုံးပြုသည့် Field ။ ၎င်းကို output attribute ဇယားတွင် အသုံးပြုမည်ဖြစ်သည်။ |
Measurement unit (အတိုင်းအတာ ယူနစ်များ) |
|
[enumeration] Default: 0 |
အနီးဆုံး feature နှင့် အကွာအဝေးအား ဖော်ပြရာ၌ သုံးသော ယူနစ်များ-
|
Hub distance (Hub အကွာအဝေး) |
|
[vector: line] Default: |
ကိုက်ညီသော point များကို ချိတ်ဆက်နေသော output line vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Hub distance (Hub အကွာအဝေး) |
|
[vector: line] |
Input feature များ၏ attribute များ ၊ ၎င်းတို့နှင့် အနီးဆုံး feature များ၏ identifier (ဖော်ထုတ်ပေးသည့်အရာ) နှင့် တွက်ချက်ထားသော အကွာအဝေးများ ပါဝင်သည့် line vector layer |
Python code
Algorithm ID: qgis:distancetonearesthublinetohub
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.7. ဗဟိုချက် သို့အကွာအဝေး (အမှတ်များ) (Distance to nearest hub (points))
Input feature များ၏ center (အလယ်ဗဟို) အပြင် အနီးဆုံး feature ၏ identifier (၎င်း၏ အလယ်ဗဟိုပေါ်တွင်အခြေခံသော) နှင့် point များကြား အကွာအဝေး တို့ပါဝင်သော field နှစ်ခုကို ကိုယ်စားပြုဖော်ပြပေးသည့် point layer တစ်ခုကို ဖန်တီးပေးပါသည်။
See also
ဗဟိုချက် သို့အကွာအဝေး (မျဉ်းမှ ဗဟိုချက် ဆီသို့) (Distance to nearest hub (line to hub)) ၊ နီးစပ်မှုဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (Join attributes by nearest)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Source points layer (ရင်းမြစ် point များ layer) |
|
[vector: any] |
အနီးဆုံး feature အားရှာဖွေရာတွင်သုံးသည့် vector layer |
Destination hubs layer (ဦးတည်ရာ ဗဟိုချက်များ layer) |
|
[vector: any] |
ရှာဖွေရမည့် feature များပါဝင်နေသော vector layer |
Hub layer name attribute (Hub layer အမည် attribute) |
|
[tablefield: any] |
ဦးတည်ရာ layer ရှိ feature များကို သီးခြားခွဲခြားသတ်မှတ်ရန် အသုံးပြုသည့် Field ။ ၎င်းကို ouput attribute ဇယားတွင် အသုံးပြုမည်ဖြစ်သည်။ |
Measurement unit (အတိုင်းအတာ ယူနစ်များ) |
|
[enumeration] Default: 0 |
အနီးဆုံး feature သို့ အကွာအဝေးအားဖော်ပြရာ၌ သုံးသော ယူနစ်များ-
|
Hub distance (Hub အကွာအဝေး) |
|
[vector: point] Default: |
အနီးဆုံး hub ပါဝင်သည့် output point vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Hub distance (Hub အကွာအဝေး) |
|
[vector: point] |
ရင်းမြစ် feature ၏အလယ်ဗဟို ၊ ၎င်းတို့၏ attribute များ၊ အနီးဆုံး feature ၏ identifier နှင့် တွက်ချက်ထားသော အကွာအဝေး တို့ကိုကိုယ်စားပြုသော point vector layer |
Python code
Algorithm ID: qgis:distancetonearesthubpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.8. မျဉ်းများဖြင့်ဆက်ခြင်း (ဗဟိုချက်မျဉ်းများ) (Join by lines (hub lines))
Spoke (ဗဟိုချက်နှင့် ချိတ်ဆက်မည့်) layer ပေါ်ရှိ point များမှ Hub (ဗဟိုချက်) layer ထဲရှိ ကိုက်ညီသော point များသို့ line များချိတ်ဆက်ခြင်းဖြင့် hub နှင့် spoke သရုပ်ပြပုံများကို ဖန်တီးပေးပါသည်။
Point တစ်ခုစီအတွက် မည်သည့် hub နှင့်ချိတ်ဆက်မည်ကို ဆုံးဖြတ်ခြင်းသည် hub point များအပေါ်ရှိ Hub ID field နှင့် spoke point များအပေါ်ရှိ Spoke ID field တို့အကြား match (ကိုက်ညီမှု) တစ်ခုအပေါ်တွင်အခြေခံပါသည်။
အကယ်၍ input layer များသည် point layer များမဟုတ်လျှင် ဂျီဩမေတြီများ၏ မျက်နှာပြင်ပေါ်ရှိ point တစ်ခုအား ချိတ်ဆက်ခြင်းတည်နေရာ အဖြစ် အသုံးပြုမည်ဖြစ်သည်။
Optional အနေဖြင့် ellipsoid တစ်ခု၏ မျက်နှာပြင်ပေါ်ရှိ အတိုဆုံးလမ်းကြောင်းကိုကိုယ်စားပြုသည့် geodesic မျဉ်းများကိုလည်းဖန်တီးနိုင်သည်။ Geodesic mode ကိုအသုံးပြုသောအခါ line များကို ပိုမိုကောင်းမွန်စွာ ပုံဖော်ပြသနိုင်စေသည့် antimeridian (± 180 ဒီဂရီ လောင်ဂျီကျု) ၌ ဖန်တီးထားသော line များကို ပိုင်းခြား (split) နိုင်သည်။ ထို့အပြင် vertex များအကြား အကွာအဝေးကိုလည်း သတ်မှတ်နိုင်သည်။ ပို၍သေးငယ်သော အကွာအဝေးသည် ပို၍သိပ်သည်းပြီး ပိုမိုတိကျသော line များကိုဖြစ်ပေါ်စေသည်။
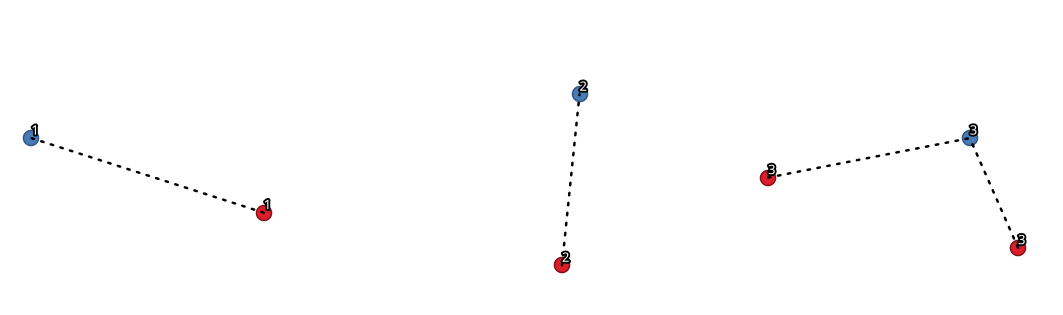
Fig. 29.33 ဘုံတူညီသော field / attribute ပေါ်တွင် အခြေခံ၍ point များကိုချိတ်ဆက်ခြင်း
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Hub layer (ဗဟိုချက် layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော layer |
Hub ID field |
|
[tablefield: any] |
ချိတ်ဆက်ရန် ID ပါရှိသော hub layer ၏ Field |
Hub layer fields to copy (leave empty to copy all fields) (မိတ္တူကူးယူရမည့် Hub layer field များ (field အားလုံးကို မိတ္တူကူးရန် empty အဖြစ်ထားရှိပါ)) Optional |
|
[tablefield: any] [list] |
မိတ္တူကူးယူရမည့် hub layer ၏ Field (များ) ။ မည်သည့် field (များ) ကိုမှ ရွေးချယ်မထားလျှင် field များအားလုံးကို ယူ၍အသုံးပြုမည်ဖြစ်သည်။ |
Spoke layer (ဗဟိုချက်နှင့်ချိတ်ဆက်မည့် layer) |
|
[vector: any] |
ထပ်ဆောင်း spoke point layer |
Spoke ID field |
|
[tablefield: any] |
ချိတ်ဆက်ရန် ID ပါရှိသော spoke layer ၏ field |
Spoke layer fields to copy (leave empty to copy all fields) (မိတ္တူကူးယူရမည့် Spoke layer field များ (field အားလုံးကို မိတ္တူကူးရန် empty အဖြစ်ထားရှိပါ)) Optional |
|
[tablefield: any] [list] |
မိတ္တူကူးယူရမည့် spoke layer ၏ Field (များ) ။ မည်သည့် field (များ) ကိုမှ ရွေးချယ်မထားလျှင် field များအားလုံးကို ယူ၍အသုံးပြုမည်ဖြစ်သည်။ |
Create geodesic lines (Geodesic မျဉ်းများကို ဖန်တီးခြင်း) |
|
[boolean] Default: False |
Geodesic မျဉ်းများကိုဖန်တီးပါ (ellipsoid တစ်ခု၏ မျက်နှာပြင်ပေါ်ရှိ အတိုဆုံး လမ်းကြောင်း) |
Hub lines (Hub မျဉ်းများ) |
|
[vector: line] Default: |
Output hub line vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Distance between vertices (geodesic lines only) (Vertex များအကြား အကွာအဝေး (geodesic မျဉ်းများသာ)) |
|
[number] Default: 1000.0 (ကီလိုမီတာ) |
ဆက်တိုက်ဖြစ်နေသော vertex များအကြား အကွာအဝေး (ကီလိုမီတာများဖြင့်)။ ပို၍သေးငယ်သော အကွာအဝေးသည် ပို၍သိပ်သည်းပြီး ပိုမိုတိကျသော line များကိုဖြစ်ပေါ်စေသည်။ |
Split lines at antimeridian (±180 degrees longitude) (မျဉ်းများကို antimeridian (±180 ဒီဂရီ လောင်ဂျီကျု) ၌ ပိုင်းခြားခြင်း) |
|
[boolean] Default: False |
Line များကို ±180 ဒီဂရီ လောင်ဂျီကျုတွင် ပိုင်းခြားပါသည် (line များကို ပုံဖော်ပြသရာတွင် ပိုမိုကောင်းမွန်စေရန်)။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Hub lines (Hub မျဉ်းများ) |
|
[vector: line] |
Input layer များထဲရှိ ကိုက်ညီသည့် point များကိုချိတ်ဆက်ပေးသော ရလာဒ် line layer |
Python code
Algorithm ID: native:hublines
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.9. K-means နည်းလမ်းဖြင့် စုဖွဲ့ခြင်း (K-means clustering)
Input feature တစ်ခုချင်းစီအတွက် 2D (နှစ်ဘက်မြင်) အကွာအဝေး အခြေခံသော k-means cluster နံပါတ်ကို တွက်ချက်ပေးပါသည်။
K-means clustering ၏ ရည်ရွယ်ချက်သည် feature များကို k cluster များအဖြစ် ပိုင်းခြား၍ feature တစ်ခုစီသည် အနီးစပ်ဆုံးပျမ်းမျှရှိသော cluster နှင့် သက်ဆိုင်မည်ဖြစ်သည်။ Mean (ပျမ်းမျှ) point အား စုဖွဲ့ထားသော feature အားလုံး၏ အလယ်မှတ်ဖြင့် ကိုယ်စားပြုသည်။
Input ဂျီဩမေတြီများသည် line များ သို့မဟုတ် polygon များဖြစ်ပါက စုဖွဲ့ခြင်း (clustering) ကို feature ၏ အလယ်ဗဟိုအပေါ်တွင် အခြေခံ၍ပြုလုပ်မည်ဖြစ်သည်။
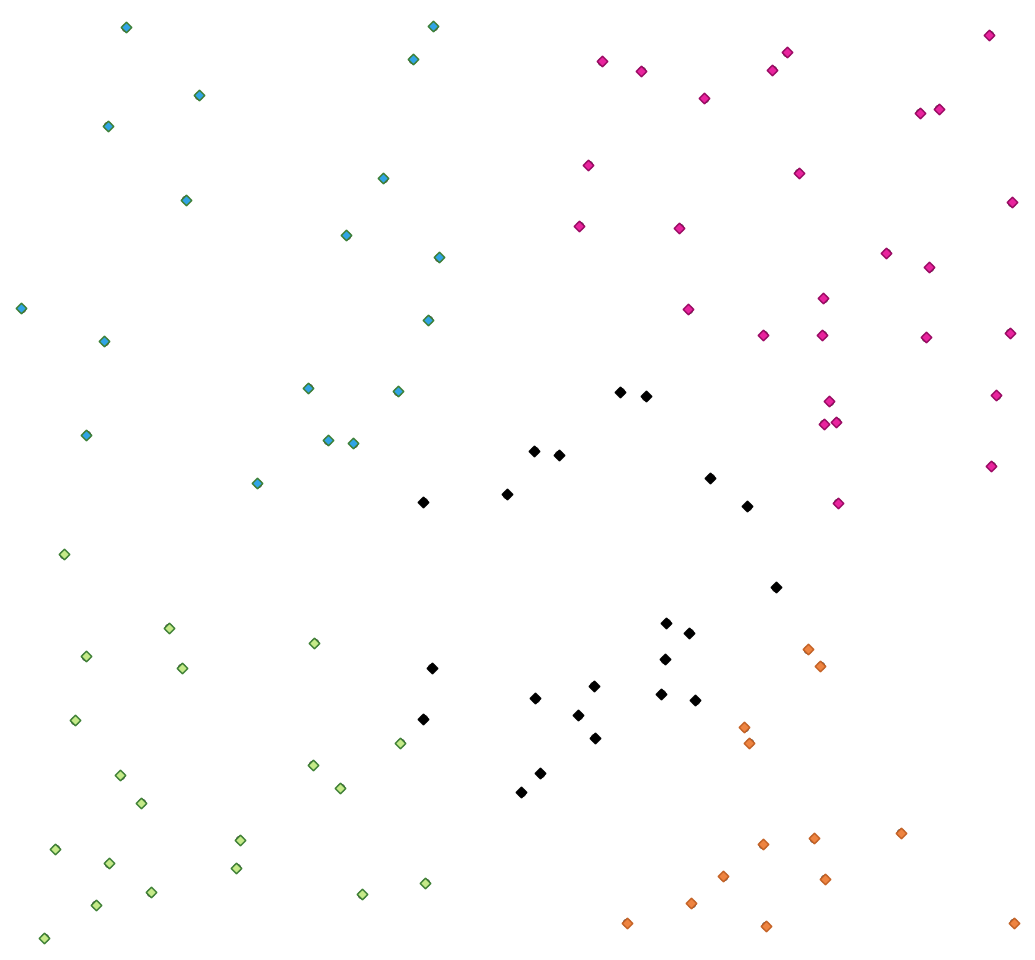
Fig. 29.34 အတန်းအစား ၅ မျိုးရှိသော point အစုအဖွဲ့များ
See also
DBSCAN ဖြင့်စုဖွဲ့ခြင်း (DBSCAN clustering) ၊ ST-DBSCAN ဖြင့် စုဖွဲ့ခြင်း (ST-DBSCAN clustering)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
လေ့လာဆန်းစစ်ရမည့် Layer |
Number of clusters (Cluster များ၏အရေအတွက်) |
|
[number] Default: 5 |
Feature များဖြင့် ဖန်တီးရမည့် cluster များ၏အရေအတွက် |
Clusters (အစုအဖွဲ့များ) |
|
[vector: any] Default: |
ဖန်တီးလိုက်သော cluster များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Cluster field name (Cluster field ၏အမည်) |
|
[string] Default: ‘CLUSTER_ID’ |
သက်ဆိုင်ရာ အစုအဖွဲ့နံပါတ်ကို သိမ်းဆည်းထားပေးမည့် field ၏အမည် |
Cluster size field name (Cluster အရွယ်အစား field ၏အမည်) |
|
[string] Default: ‘CLUSTER_SIZE’ |
တူညီသော cluster အတွင်း feature များ၏ အရေအတွက်ပါရှိသော field ၏အမည် |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Clusters (အစုအဖွဲ့များ) |
|
[vector: any] |
မူရင်း feature များအပြင် ၎င်းတို့နှင့် သက်ဆိုင်သော cluster နှင့် cluster ထဲရှိ ၎င်းတို့၏အရေအတွက်ကို သတ်မှတ်ဖော်ပြထားသော field များပါရှိသည့် vector layer |
Python code
Algorithm ID: native:kmeansclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.10. သီးခြားကွဲပြားနေသောတန်ဖိုးများကို စာရင်းပြုခြင်း (List unique values)
Attribute ဇယား field တစ်ခု၏ သီးခြားကွဲပြားနေသောတန်ဖိုးများကို စာရင်းပြုစုပေး၍ ၎င်းတို့၏အရေအတွက်ကိုဖော်ပြပေးပါသည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
လေ့လာဆန်းစစ်မည့် Layer |
Target field(s) (ဦးတည်ရာ field (များ)) |
|
[tablefield: any] |
လေ့လာဆန်းစစ်မည့် Field |
Unique values (သီးခြားကွဲပြားသည့် တန်ဖိုးများ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[table] Default: |
သီးခြားကွဲပြားသည့် တန်ဖိုးများကိုပြသထားသည့် အကျဉ်းချုပ်ဇယား layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
HTML report (HTML အစီရင်ခံစာ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[html] Default: |
ထဲရှိ သီးခြားကွဲပြားသည့် တန်ဖိုးများ၏ HTML အစီရင်ခံစာ ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Unique values (သီးခြားကွဲပြားသည့် တန်ဖိုးများ) |
|
[table] |
သီးခြားကွဲပြားသည့် တန်ဖိုးများကိုပြသထားသည့် အကျဉ်းချုပ်ဇယား layer |
HTML report (HTML အစီရင်ခံစာ) |
|
[html] |
သီးခြားကွဲပြားသည့် တန်ဖိုးများ၏ HTML အစီရင်ခံစာ ။ မှတစ်ဆင့် ဖွင့်နိုင်သည်။ |
Total unique values (သီးခြားကွဲပြားသည့် တန်ဖိုးများစုစုပေါင်း) |
|
[number] |
Input field ထဲရှိ သီးခြားကွဲပြားသည့် တန်ဖိုးများ၏ အရေအတွက် |
Unique values concatenated (သီးခြားကွဲပြားသည့် တန်ဖိုးများ ပေါင်းစပ်ထားသော) |
|
[string] |
Input field ထဲတွင်တွေ့ရှိရသော သီးခြားကွဲပြားသည့် တန်ဖိုးများကို comma ဖြင့်ပိုင်းခြားပေးထားသည့်စာရင်းပါရှိသော စာသား (string) တစ်ခု |
Python code
Algorithm ID: qgis:listuniquevalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.11. ပျှမ်းမျှကိုဩဒိနိတ် (Mean coordinate)
Input layer တစ်ခုထဲရှိ ဂျီဩမေတြီအများအပြား၏ အလယ်မှတ် ပါရှိသော point layer တစ်ခုကို တွက်ချက်ပေးပါသည်။
ဂျီဩမေတြီအများအပြား၏ အလယ်မှတ် အားတွက်ချက်နေချိန်တွင် feature တစ်ခုစီပေါ်တွင် အသုံးပြုနိုင်မည့် weight (အလေးပေးမှု) များပါဝင်သော attribute တစ်ခုအားသတ်မှတ်နိုင်သည်။
အကယ်၍ attribute တစ်ခုအား parameter ထဲတွင် ရွေးချယ်ထားလျှင် feature များကို ဤ field ထဲရှိ တန်ဖိုးများအတိုင်း အုပ်စုဖွဲ့မည်ဖြစ်သည်။ Layer တစ်ခုလုံး၏ အလယ်မှတ်အား point တစ်ခုတည်းဖြင့်ပြသမည့်အစား output layer တွင် အမျိုးအစားတစ်ခုစီရှိ feature များအတွက် အလယ်မှတ်တစ်ခုစီပါဝင်လာမည်ဖြစ်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Weight field (အလေးပေးမှု field) Optional |
|
[tablefield: numeric] |
Weighted (အလေးပေးထားသော) mean ကို လုပ်ဆောင်လိုလျှင် အသုံးပြုရမည့် field |
Unique ID field (သီးခြားကွဲပြားသည့် ID field) |
|
[tablefield: numeric] |
ပျမ်းမျှတန်ဖိုးများတွက်ချက်မည့် သီးခြားကွဲပြားသည့် field |
Mean coordinates (ပျမ်းမျှ ကိုဩဒိနိတ်များ) |
|
[vector: point] Default: |
ရလာဒ်အတွက် layer (point vector) ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Mean coordinates (ပျမ်းမျှ ကိုဩဒိနိတ်များ) |
|
[vector: point] |
ရလာဒ်ရရှိလာသော point (များ) layer |
Python code
Algorithm ID: native:meancoordinates
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
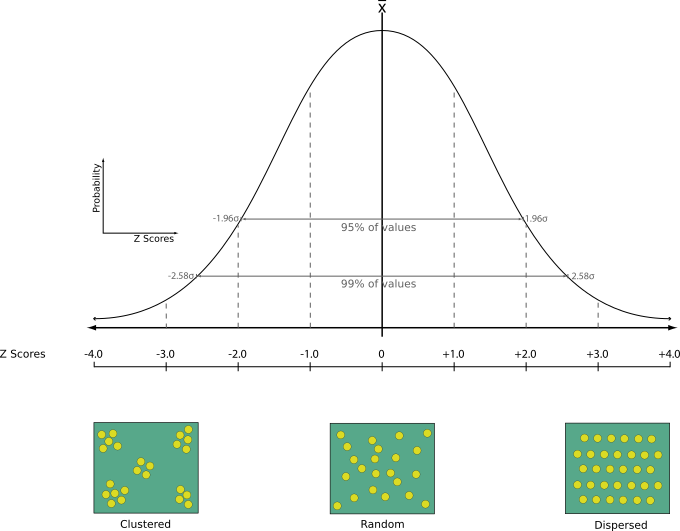
29.1.15.12. အနီးဆုံးအရာကိုလေ့လာဆန်းစစ်မှု (Nearest neighbour analysis)
Point layer တစ်ခုအတွက် Nearest neighbour လေ့လာဆန်းစစ်ခြင်းကို ဆောင်ရွက်ပေးပါသည်။ Output သည် data များအား မည်ကဲ့သို့ ဖြန့်ကျက်ထားသည်ကို ဖော်ပြပေးပါသည် (စုဖွဲ့ထားခြင်း သို့မဟုတ် ကျပန်းဖြန့်ကျက်ခြင်း)
Output အား တွက်ချက်ထားသော စာရင်းအင်းအချက်အလက်ဆိုင်ရာ တန်ဖိုးများပါဝင်သော HTML file တစ်ခုအဖြစ်ထုတ်ပေးမည်ဖြစ်သည်-
တွေ့ရှိရသော ပျမ်းမျှအကွာအဝေး
မျှော်မှန်းထားသော ပျမ်းမျှအကွာအဝေး
Nearest neighbour အညွှန်း
Point များ၏အရေအတွက်
Z-Score : Z-Score အား normal distribution (ပုံမှန်ဖြန့်ကျက်ခြင်း) နှင့်နှိုင်းယှဉ်ခြင်းသည် data များအား မည်သို့ဖြန့်ကျက်ထားကြောင်း ဖော်ပြပေးပါသည်။ Z-Score တန်ဖိုးနိမ့်ခြင်းသည် data များ ကျပန်းဖြန့်ကျက်ခြင်းမဟုတ်ကြောင်း ဆိုလိုပြီး Z-Score တန်ဖိုးမြင့်ခြင်းသည် data များ ကျပန်းဖြန့်ကျက်ခြင်းဖြစ်ကြောင်း ဆိုလိုပါသည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: point] |
ကိန်းဂဏန်းအချက်အလက်များကို တွက်ချက်မည့် point vector layer |
Nearest neighbour (အနီးစပ်ဆုံး အနီးအနား) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[html] Default: |
တွက်ချက်ထားသော ကိန်းဂဏန်းအချက်အလက်များအတွက် HTML file ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Nearest neighbour (အနီးစပ်ဆုံး အနီးအနား) |
|
[html] |
တွက်ချက်ထားသော ကိန်းဂဏန်းအချက်အလက်များပါဝင်သည့် HTML file |
Observed mean distance (တွေ့ရှိရသော ပျမ်းမျှအကွာအဝေး) |
|
[number] |
တွေ့ရှိရသော ပျမ်းမျှအကွာအဝေး |
Expected mean distance (မျှော်မှန်းထားသော ပျမ်းမျှအကွာအဝေး) |
|
[number] |
မျှော်မှန်းထားသော ပျမ်းမျှအကွာအဝေး |
Nearest neighbour index (အနီးစပ်ဆုံး အနီးအနား အညွှန်းကိန်း) |
|
[number] |
အနီးစပ်ဆုံး အနီးအနား အညွှန်းကိန်း |
Number of points (Point များ၏အရေအတွက်) |
|
[number] |
Point များ၏အရေအတွက် |
Z-Score |
|
[number] |
Z-Score |
Python code
Algorithm ID: native:nearestneighbouranalysis
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.13. ထပ်နေမှုကို ဆန်းစစ်ခြင်း (Overlap analysis)
Input layer တစ်ခုမှ feature များကို overlay layer များ၏ရွေးချယ်မှုတစ်ခုထဲမှ feature များမှ ထပ်နေသော ဧရိယာနှင့် ရာခိုင်နှုန်းကို တွက်ချက်ပေးပါသည်။
ရွေးချယ်ထားသော overlay layer များ၏တစ်ခုချင်းစီမှ ထပ်နေသော input feature ၏ စုစုပေါင်းဧရိယာ နှင့် ရာခိုင်နှုန်း ကိုဖော်ပြသော attribute အသစ်များကို output layer ထဲသို့ ပေါင်းထည့်ပေးမည်ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော layer |
Overlap layers (ထပ်နေသော layer များ) |
|
[vector: any] [list] |
Overlay layer များ |
Overlap |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Grid size (Grid အရွယ်အစား) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number] Default: Not set |
Grid အရွယ်အစားကိုသတ်မှတ်ပေးထားလျှင် input ဂျီဩမေတြီများကို သတ်မှတ်ထားသော grid တစ်ခုပေါ်တွင် snap (ဆွဲကပ်) ပေးမည်ဖြစ်ပြီး ရရှိလာသော vertex များကို ထိုတူညီသော grid ပေါ်တွင် တွက်ချက်မည်ဖြစ်သည်။ ဤလုပ်ဆောင်ချက်အတွက် GEOS 3.9.0 သို့မဟုတ် ပိုမြင့်သော ဗားရှင်းကိုလိုအပ်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Overlap |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသော layer တစ်ခုစီမှ ထပ်နေသော input feature ၏ overlap (မြေပုံယူနစ်များနှင့် ရာခိုင်နှုန်းဖြင့်) ကို ပြသသည့် ထပ်ဆောင်း field များပါဝင်သော output layer။ |
Python code
Algorithm ID: native:calculatevectoroverlaps
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.14. Feature များအကြားရှိ အတိုဆုံးမျဉ်း (Shortest line between features)
ရင်းမြစ် layer နှင့် ဦးတည်ရာ layer အကြား အတိုဆုံး line layer တစ်ခုကို ဖန်တီးပေးပါသည်။ Default အားဖြင့် ဉီးတည်ရာ layer ၏ ပထမ အနီးဆုံး feature ကိုသာထည့်သွင်းစဉ်းစားမည်ဖြစ်သည်။ n-nearest neighboring feature များ၏ အရေအတွက်ကို သတ်မှတ်နိုင်သည်။ အကယ်၍ အများဆုံးအကွာအဝေးကိုသတ်မှတ်ထားလျှင် ဤအကွာအဝေးထက် နီးသော feature များကိုသာစဉ်းစားမည်ဖြစ်သည်။
Output feature များတွင် ရင်းမြစ် layer မှ attribute များအားလုံး၊ n-nearest feature မှ attribute များအားလုံးနှင့် ထပ်ဆောင်းထည့်သွင်းထားသော အကွာအဝေးဖော်ပြသည့် field တို့ ပါဝင်မည်ဖြစ်သည်။
Important
ဤ algorithm သည် အကွာအဝေး တွက်ချက်ရာတွင် Cartesian တွက်ချက်နည်းကိုသာ အသုံးပြုပြီး feature proximity (အနီးအဝေး) ကိုဆုံးဖြတ်သောအခါ geodetic (ကမ္ဘာ၏အရွယ်အစားနှင့်ဆိုင်သော) သို့မဟုတ် ellipsoid (ဘဲဥပုံစက်လုံးနှင့်ဆိုင်သော) ဂုဏ်သတ္တိများကို ထည့်သွင်းစဉ်းစားမည်မဟုတ်ပါ။ အတိုင်းအတာများနှင့် output ကိုဩဒိနိတ်စနစ်ကို ရင်းမြစ် layer ၏ ကိုဩဒိနိတ်စနစ်ပေါ်တွင် အခြေခံထားသည်။
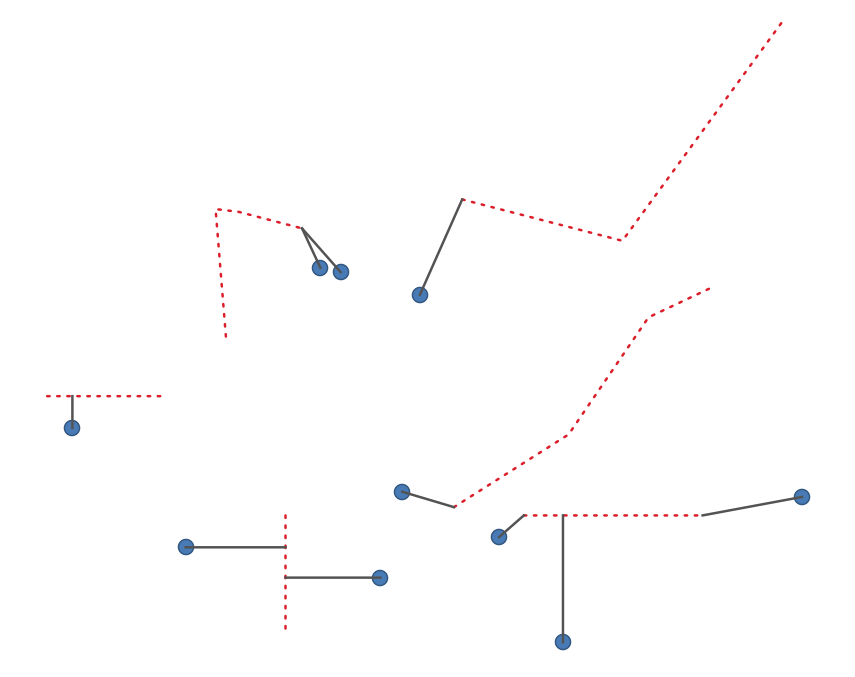
Fig. 29.35 Point feature များမှ line များသို့ အတိုဆုံးမျဉ်း
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Source layer (ရင်းမြစ် layer) |
|
[vector: any] |
အနီးစပ်ဆုံး အနီးအနား (nearest neighbor) များကိုရှာဖွေပေးမည့် မူရင်း layer |
Destination layer (ဦးတည်ရာ layer) |
|
[vector: any] |
အနီးစပ်ဆုံး အနီးအနား (nearest neighbor) များကိုရှာဖွေရမည့် ဦးတည်ရာ Layer |
Method (နည်းလမ်း) |
|
[enumeration] Default: 0 |
အတိုဆုံးအကွာအဝေးအားတွက်ချက်သည့် နည်းလမ်း။ ဖြစ်နိုင်ချေရှိသော တန်ဖိုးများမှာ-
|
Maximum number of neighbors (အများဆုံး အနီးအနားများအရေအတွက်) |
|
[number] Default: 1 |
ရှာဖွေရမည့် အများဆုံး အနီးအနားများအရေအတွက် |
Maximum distance (အများဆုံးအကွာအဝေး) Optional |
|
[number] |
ဤ အကွာအဝေးထက်ပိုနီးသည့် ဦးတည်ရာ feature များကိုသာ ထည့်သွင်းစဉ်းစားမည်ဖြစ်သည်။ |
Shortest lines (အတိုဆုံးမျဉ်းများ) |
|
[vector: line] Default: |
Output vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်သည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Output layer |
|
[vector: line] |
ရင်းမြစ် feature များအား ဦးတည်ရာ layer ထဲရှိ ၎င်းတို့နှင့် အနီးစပ်ဆုံး အနီးအနား (nearest neighbor) များနှင့် ချိတ်ဆက်ထားသော line vector layer ။ ၎င်းတွင် ရင်းမြစ် feature များနှင့် ဦးတည်ရာ feature များ နှစ်ခုစလုံးအတွက် attribute များအားလုံးနှင့် တွက်ချက်ထားသော အကွာအဝေးပါဝင်ပါသည်။ |
Python code
Algorithm ID: native:shortestline
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.15. ST-DBSCAN ဖြင့် စုဖွဲ့ခြင်း (ST-DBSCAN clustering)
Point feature များကို ST-DBSCAN (spatiotemporal Density-based clustering of applications with noise) algorithm ၏ 2D (နှစ်ဘက်မြင်) ဆောင်ရွက်ခြင်းကို အခြေခံ၍ စုဖွဲ့ပေးပါသည်။
See also
DBSCAN ဖြင့်စုဖွဲ့ခြင်း (DBSCAN clustering) ၊ K-means နည်းလမ်းဖြင့် စုဖွဲ့ခြင်း (K-means clustering)
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: point] |
လေ့လာဆန်းစစ်မည့် Layer |
Date/time field (ရက်စွဲ/အချိန် field) |
|
[tablefield: date] |
အချိန်ဆိုင်ရာ အချက်အလက်များ ပါဝင်သော field |
Minimum cluster size (အငယ်ဆုံး အစုအဖွဲ့ အရွယ်အစား) |
|
[number] Default: 5 |
Cluster တစ်စုဖန်တီးရန် လိုအပ်သည့် အနည်းဆုံး feature အရေအတွက် |
Maximum distance between clustered points (စုဖွဲ့ထားသော point များအကြား အများဆုံး အကွာအဝေး) |
|
[number] Default: 1.0 |
ယခုသတ်မှတ်မည့် အကွာအဝေးကို ကျော်လွန်၍ feature နှစ်ခုသည် တူညီသော cluster (eps) နှင့်သက်ဆိုင်မှုမရှိစေနိုင်ပါ။ |
Maximum time duration between clustered points (စုဖွဲ့ထားသော point များအကြား အများဆုံးကြာချိန်ကာလ) |
|
[number] Default: 0.0 (days) |
ယခုသတ်မှတ်မည့် ကြာချိန်ကို ကျော်လွန်၍ feature နှစ်ခုသည် တူညီသော cluster (eps) နှင့်သက်ဆိုင်မှုမရှိစေနိုင်ပါ။ ရရှိနိုင်သော အချိန်ယူနစ်များမှာ မီလီစက္ကန့်များ၊ စက္ကန့်များ၊ မိနစ်များ၊ နာရီများ၊ ရက်များနှင့် ရက်သတ္တပတ်များ။ |
Clusters (အစုအဖွဲ့များ) |
|
[vector: point] Default: |
စုဖွဲ့ခြင်း၏ ရလာဒ်များအတွက် vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Treat border points as noise (DBSCAN*) (အနားသတ်ဘောင်များပေါ်ရှိ point များကို noise အဖြစ်စဉ်းစားခြင်း) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[boolean] Default: False |
အမှန်ခြစ်ပေးထားပါက cluster တစ်ခု၏ အနားသတ်ဘောင်များပေါ်ရှိ point များကို စုဖွဲ့ခြင်းမလုပ်ထားသော point များအဖြစ်သတ်မှတ်မည်ဖြစ်ပြီး cluster တစ်ခု၏အတွင်းရှိ point များကိုသာလျှင် စုဖွဲ့ထားသည်များအဖြစ် သတ်မှတ်မည်ဖြစ်သည်။ |
Cluster field name (Cluster field ၏အမည်) |
|
[string] Default: ‘CLUSTER_ID’ |
သက်ဆိုင်ရာ cluster နံပါတ်ကို သိမ်းဆည်းထားပေးမည့် field ၏အမည် |
Cluster size field name (Cluster အရွယ်အစားအတွက် field ၏အမည်) |
|
[string] Default: ‘CLUSTER_SIZE’ |
တူညီသော cluster ထဲရှိ feature များ၏အရေအတွက်ပါရှိသော field ၏အမည် |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Clusters (အစုအဖွဲ့များ) |
|
[vector: point] |
မူရင်း feature များအပြင် ၎င်းတို့ သက်ဆိုင်သော cluster field တစ်ခု ပါရှိသော vector layer |
Number of clusters (Cluster များ၏အရေအတွက်) |
|
[number] |
တွေ့ရှိရသော cluster များ၏အရေအတွက် |
Python code
Algorithm ID: native:stdbscanclustering
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.16. အမျိုးအစားဆိုင်ရာ ကိန်းဂဏန်းအချက်အလက်များ (Statistics by categories)
Parent class (မူရင်းအတန်းအစား) တစ်ခုပေါ်တွင်မူတည်သော field တစ်ခု၏ ကိန်းဂဏန်းအချက်အလက်များကို တွက်ချက်ပေးပါသည်။ Parent class သည် အခြား field များမှ တန်ဖိုးများ စုပေါင်းထားမှု တစ်ခုဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input vector layer (ထည့်သွင်းအသုံးပြုသော vector layer) |
|
[vector: any] |
သီးခြားကွဲပြားသည့် အတန်းအစားများနှင့် တန်ဖိုးများပါဝင်သော input vector layer |
Field to calculate statistics on (if empty, only count is calculated) (ကိန်းဂဏန်းအချက်အလက်များတွက်ချက်မည့် Field (ဗလာဖြစ်နေလျှင် အရေအတွက်ကိုသာတွက်ချက်မည်)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] |
ဗလာဖြစ်နေလျှင် အရေအတွက်ကိုသာ တွက်ချက်မည်ဖြစ်သည်။ |
Field(s) with categories (အမျိုးအစားများပါဝင်သော field များ) |
|
[vector: any] [list] |
အမျိုးအစားများကို သတ်မှတ်ပေးသည့် field များ |
Statistics by category (အမျိုးအစားအရ ကိန်းဂဏန်းအချက်အလက်များ) |
|
[table] Default: |
ထွက်ရှိလာသော ကိန်းဂဏန်းအချက်အလက်များအတွက် output ဇယားကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Statistics by category (အမျိုးအစားအရ ကိန်းဂဏန်းအချက်အလက်များ) |
|
[table] |
ကိန်းဂဏန်းအချက်အလက်များပါဝင်သော ဇယား |
လေ့လာဆန်းစစ်ခြင်းခံရသည့် field အမျိုးအစားပေါ်တွင်မူတည်၍ အုပ်စုဖွဲ့ထားသော တန်ဖိုးတစ်ခုစီအတွက် အောက်ပါ ကိန်းဂဏန်းအချက်အလက်များကို ပြန်ထုတ်ပေးပါသည်-
ကိန်းဂဏန်းအချက်အလက်များ |
စာသား |
ကိန်းဂဏန်း |
ရက်စွဲ |
|---|---|---|---|
အရေအတွက် ( |
|
|
|
သီးခြားကွဲပြားသည့်တန်ဖိုးများ ( |
|
|
|
ဗလာ (null) တန်ဖိုးများ ( |
|
|
|
ဗလာမဟုတ်သော တန်ဖိုးများ ( |
|
|
|
အနည်းဆုံးတန်ဖိုး ( |
|
|
|
အများဆုံးတန်ဖိုး( |
|
|
|
အပိုင်းအခြား ( |
|
||
ပေါင်းလဒ် ( |
|
||
ပျှမ်းမျှတန်ဖိုး ( |
|
||
တဝက်ကိန်းတန်ဖိုး ( |
|
||
စံတိမ်းချက် ( |
|
||
ပြောင်းလဲမှုပြကိန်း ( |
|
||
အနည်းစု (အနည်းဆုံးတွေ့ရှိရသည့်တန်ဖိုး - |
|
||
အများစု (အများဆုံးတွေ့ရှိရသည့်တန်ဖိုး - |
|
||
First Quartile ( |
|
||
Third Quartile ( |
|
||
Inter Quartile Range ( |
|
||
အနည်းဆုံးအလျား ( |
|
||
ပျမ်းမျှ အလျား ( |
|
||
အများဆုံးအလျား ( |
|
Python code
Algorithm ID: qgis:statisticsbycategories
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.15.17. မျဉ်းအလျားများပေါင်းခြင်း (Sum line lengths)
Polygon layer တစ်ခု နှင့် line layer တစ်ခုကိုယူ၍ line များ၏စုစုပေါင်းအလျားနှင့် polygon တစ်ခုစီကိုဖြတ်သွားသည့် line များ၏ စုစုပေါင်းအရေအတွက်ကို တိုင်းတာပေးပါသည်။
ရလာဒ် layer တွင် input layer အတိုင်း တူညီသော feature များရှိမည်ဖြစ်ပြီး polygon တစ်ခုစီကိုဖြတ်သွားသည့် line များ၏ အလျားနှင့် အရေအတွက်များပါဝင်သော ထပ်ဆောင်း attribute နှစ်ခုပါဝင်မည်ဖြစ်သည်။
တွင်အမှန်ခြစ်ပေးခြင်းဖြင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ကိုအသုံးပြုနိုင်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Lines |
|
[vector: line] |
ထည့်သွင်းအသုံးပြုသော vector line layer |
Polygons |
|
[vector: polygon] |
Polygon vector layer |
Lines length field name (မျဉ်းများ၏ အလျား field အမည်) |
|
[string] Default: ‘LENGTH’ |
မျဉ်းများ၏ အလျားကိုပြသော field ၏အမည် |
Lines count field name (မျဉ်းများ၏ အရေအတွက် field အမည်) |
|
[string] Default: ‘COUNT’ |
မျဉ်းများ၏ အရေအတွက်ကိုပြသော field ၏အမည် |
Line length (မျဉ်းအလျား) |
|
[vector: polygon] Default: |
တွက်ထုတ်ထားသည့် ကိန်းဂဏန်းအချက်အလက်များပါရှိသည့် output polygon layer သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Line length (မျဉ်းအလျား) |
|
[vector: polygon] |
မျဉ်းများ၏ အလျားနှင့် မျဉ်းအရေအတွက်ပါဝင်သော field များပါရှိသည့် polygon output layer |
Python code
Algorithm ID: native:sumlinelengths
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။