29.1.21. Vector ဇယား (Vector table)
29.1.21.1. နံပါတ်စဉ်အလိုအလျောက်တိုးပေးသည့် field ထည့်ခြင်း (Add autoincremental field)
Feature တစ်ခုချင်းစီအတွက် အစီအစဉ်တကျဖြစ်သောတန်ဖိုးတစ်ခုဖြင့် vector layer တစ်ခုထဲသို့ ဂဏန်းဆိုင်ရာ integer (ကိန်းပြည့်) field အသစ်တစ်ခု ပေါင်းထည့်ပေးပါသည်။။
အဆိုပါ field ကို layer ထဲရှိ feature များအတွက် unique ID တစ်ခုအဖြစ် အသုံးပြုနိုင်ပါသည်။ အချက်အလက် (attribute) အသစ်ကို input layer ထဲတွင် ပေါင်းထည့်မည်မဟုတ်ပဲ layer အသစ်တစ်ခု ပေါ်ထွက်လာမည်ဖြစ်သည်။
တိုးလာမည့်ကိန်းစဉ် အတွက် ကနဦးစတင်မည့်တန်ဖိုးကို သတ်မှတ်နိုင်ပါသည်။ အခြားနည်းအနေဖြင့် တိုးလာမည့်ကိန်းစဉ် ကို field များအုပ်စုဖွဲ့ခြင်းပေါ်တွင် အခြေခံနိုင်ပြီး feature များအတွက် sort order (မျိုးတူစုခြင်း အစီအစဉ်) ကိုလည်းသတ်မှတ်နိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Field name (Field အမည်) |
|
[string] Default: ‘AUTO’ |
အလိုအလျောက်တိုးလာမည့် တန်ဖိုးများပါဝင်မည့် field ၏အမည် |
Start values at (အစတန်ဖိုး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number] Default: 0 |
တိုးလာမည့်အရေအတွက်၏ ကနဦးဂဏန်းကို ရွေးချယ်ပါ |
Modulus value (ပကတိတန်ဖိုး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number] Default: 0 |
စိတ်ကြိုက် modulus တန်ဖိုးတစ်ခုကို သတ်မှတ်ခြင်းသည် Field တန်ဖိုးသည် modulus တန်ဖိုးသို့ရောက်သည့်အချိန်တိုင်း အရေအတွက်ကို ပြန်လည်စတင်မည် ဖြစ်သည်။ |
Group values by (တန်ဖိုးများကို အုပ်စုဖွဲ့ခြင်း) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] [list] |
အုပ်စုဖွဲ့မည့် field များကို ရွေးချယ်ပါ - layer တစ်ခုလုံးအတွက် ရေတွက်မှုတစ်ခုတည်းဖြင့် လုပ်ဆောင်ခြင်းအစား အဆိုပါ field များပေါင်းစပ်ခြင်းမှ ရရှိလာသော တန်ဖိုးတစ်ခုချင်းစီအတွက် သီးခြား ရေတွက်မှုတစ်ခုကို လုပ်ဆောင်မည်ဖြစ်သည်။ |
Sort expression (မျိုးတူစုခြင်း expression) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[expression] |
အုပ်စု field များအပေါ်အခြေခံပြီး layer အတွင်းရှိ feature များကို sort (မျိုးတူစု) လုပ်ရန် Expression တစ်ခုကို အသုံးပြုပါ။ |
Sort ascending (မျိုးတူစုခြင်း ငယ်စဉ်ကြီးလိုက်) |
|
[boolean] Default: True |
|
Sort nulls first (Null များကို ဦးစွာ စီပါ) |
|
[boolean] Default: False |
|
Incremented (တိုးလာပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
အလိုအလျောက်တိုးလာသော field ပါဝင်သည့် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Incremented (တိုးလာပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
အလိုအလျောက်တိုးလာသော field ပါဝင်သည့် vector layer |
Python code
Algorithm ID: native:addautoincrementalfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.2. အချက်အလက်ဇယားတွင် field အသစ်တစ်ခုထည့်ခြင်း (Add field to attributes table)
Vector layer တစ်ခုထဲသို့ field အသစ်တစ်ခု ပေါင်းထည့်ပေးပါသည်။
Attribute ၏ အမည်နှင့် ဝိသေသလက္ခဏာများကို parameter (သတ်မှတ်ချက်) များအဖြစ်သတ်မှတ်မည် ဖြစ်ပါသည်။
Attribute အသစ်ကို input layer ထဲတွင် ပေါင်းထည့်မည်မဟုတ်ပဲ layer အသစ်တစ်ခု ပေါ်ထွက်လာမည်ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော layer |
Field name (Field အမည်) |
|
[string] |
Field အသစ်၏ အမည် |
Field type (Field အမျိုးအစား) |
|
[enumeration] Default: 0 |
Field အသစ်၏ အမျိုးအစား။ အောက်ပါတို့ထဲမှ ရွေးချယ်နိုင်ပါသည်-
|
Field length (Field အရှည်) |
|
[number] Default: 10 |
Field ၏ အရှည် |
Field precision (Field ၏တိကျမှု) |
|
[number] Default: 0 |
Field ၏ တိကျမှု ။ float field အမျိုးအစားများတွင် အသုံးဝင်ပါသည်။ |
Field alias (Field ၏ အမည်ပွား)
Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Field အတွက် အမည်ပွား (alias) အဖြစ်အသုံးပြုမည့် အမည်တစ်ခုကို သတ်မှတ်ပါ။ Format အမျိုးအစားများအားလုံးတွင် အသုံးမပြုနိုင်ပါ။ |
Field comment (Field မှတ်ချက်)
Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Field ကို ဖော်ပြသော မှတ်ချက်တစ်ခုကို သိမ်းဆည်းမည်ဖြစ်သည်။ Format အမျိုးအစားများအားလုံးတွင် အသုံးမပြုနိုင်ပါ။ |
Added (ပေါင်းထည့်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Added (ပေါင်းထည့်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Field အသစ် ပေါင်းထည့်ထားသော vector layer |
Python code
Algorithm ID: native:addfieldtoattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.3. ထပ်တူမရှိအညွှန်းကိန်း field ထည့်ခြင်း (Add unique value index field)
Vector layer တစ်ခုနှင့် attribute တစ်ခု ယူပြီး ဂဏန်းဆိုင်ရာ field အသစ်တစ်ခု ပေါင်းထည့်ပေးပါသည်။
အဆိုပါ field ထဲရှိ တန်ဖိုးများသည် သတ်မှတ်ထားသော attribute ထဲရှိ တန်ဖိုးများနှင့် သက်ဆိုင်နေမည် ဖြစ်ပါသည်။ ထို့ကြောင့် attribute တန်ဖိုးတူညီသည့် feature များသည် ဂဏန်းဆိုင်ရာ field အသစ်ထဲတွင် တန်ဖိုးများ တူညီနေပါလိမ့်မည်။
ထိုအချက်သည် သတ်မှတ်ထားသော attribute နှင့် ကိန်းဂဏန်းညီမျှမည်ဖြစ်ပြီး၊ တူညီသောအတန်းအစားများကို သတ်မှတ်မည်ဖြစ်သည်။
Attribute အသစ်ကို input layer ထဲတွင် ပေါင်းထည့်မည်မဟုတ်ပဲ layer အသစ်တစ်ခု ပေါ်ထွက်လာမည်ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော layer |
Class field (အတန်းအစား field) |
|
[tablefield: any] |
ဤ field တွင် တန်ဖိုးများတူညီသည့် feature များသည် တူညီသည့် အညွှန်းကိန်း (index) များရရှိမည် ဖြစ်သည်။ |
Output field name (ရလာဒ် field အမည်) |
|
[string] Default: ‘NUM_FIELD’ |
အညွှန်းကိန်း (index) များပါရှိသည့် field အသစ်၏ အမည် |
Layer with index field (Index field ပါဝင်သော layer) |
|
[vector: any] Default: |
အညွှန်းကိန်း (index) များပါရှိသည့် ဂဏန်းဆိုင်ရာ field များပါဝင်သော vector layer ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Class summary (အတန်းအစား အကျဉ်းချုပ်) |
|
[table] Default: |
သက်ဆိုင်ရာ unique တန်ဖိုးကို ဖော်ပြသော အတန်းအစား field ၏အကျဉ်းချုပ်ပါဝင်ရန် table (ဇယား) ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Layer with index field (Index field ပါဝင်သော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
အညွှန်းကိန်း (index) များပါဝင်သည့် ဂဏန်းဆိုင်ရာ field များပါဝင်သော vector layer ။ |
Class summary (အတန်းအစား အကျဉ်းချုပ်) |
|
[table] |
သက်ဆိုင်ရာ unique တန်ဖိုးကို ဖော်ပြသော အတန်းအစား field ၏အကျဉ်းချုပ်ပါဝင်သည့် table (ဇယား)။ |
Python code
Algorithm ID: native:adduniquevalueindexfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.4. X/Y field များ ထည့်ခြင်း (Add X/Y fields to layer)
Point layer တစ်ခုထဲသို့ X နှင့် Y (သို့မဟုတ် လတ္တီကျု/ လောင်ဂျီကျု) field များကို ပေါင်းထည့်ပေးပါသည်။ X/Y field များကို layer ထဲသို့ထည့်ရာတွင် မတူညီသော CRS တစ်ခုဖြင့် တွက်ချက်နိုင်ပါသည် (ဥပမာ- projected CRS တစ်ခုသုံးထားသော layer တစ်ခုအတွက် လတ္တီကျု/လောင်ဂျီကျု field များဖန်တီးခြင်း)။
 သည် Point feature များ၏ features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း ကို လုပ်ဆောင်နိုင်ပါသည်။
သည် Point feature များ၏ features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း ကို လုပ်ဆောင်နိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: point] |
ထည့်သွင်းအသုံးပြုသော layer |
Coordinate system (ကိုဩဒိနိတ်စနစ်) |
|
[crs] Default: “EPSG:4326” |
ထုတ်ထားသော x နှင့် y field များအတွက် အသုံးပြုရန် ကိုဩဒိနိတ်ရည်ညွှန်းစနစ် (CRS) |
Field prefix (Field ၏ ရှေ့ဆက်စာလုံး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Input layer ထဲရှိ field များနှင့် အမည်တူနေမှုများကို ရှောင်ရှားရန် field အသစ်၏အမည်များတွင် ပေါင်းထည့်မည့် prefix (ရှေ့ဆက်စာလုံး)။ |
Added fields (ပေါင်းထည့်ထားသော field များ) |
|
[vector: point] Default: |
Output layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Added fields (ပေါင်းထည့်ထားသော field များ) |
|
[vector: point] |
Output layer - input layer နှင့် တစ်ထပ်တည်းတူညီသော်လည်း output layer တွင် |
Python code
Algorithm ID: native:addxyfieldstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.5. အဆင့်မြင့် Python field ဂဏန်းတွက်စက် (Advanced Python field calculator)
Feature တစ်ခုချင်းစီတွင် expression တစ်ခုအသုံးပြုခြင်းမှ ရရှိလာသော တန်ဖိုးများပါဝင်သည့် အချက်အလက်အသစ်တစ်ခုကို vector layer တစ်ခုထဲသို့ ပေါင်းထည့်ပေးပါသည်။
Expression ကို Python function တစ်ခုအဖြစ် သတ်မှတ်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Result field name (ရလာဒ် field အမည်) |
|
[string] Default: ‘NewField’ |
Field အသစ်၏ အမည် |
Field type |
|
[enumeration] Default: 0 |
Field အသစ်အမျိုးအစား။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
Field length (Field အရှည်) |
|
[number] Default: 10 |
Field ၏ အရှည် |
Field precision (Field ၏တိကျမှု) |
|
[number] Default: 3 |
Field ၏ တိကျမှု။ Float field အမျိုးအစားများတွင် အသုံးဝင်ပါသည်။ |
Global expression Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Calculator သည် input layer ၏ feature များအားလုံးကို ထပ်ခါထပ်ခါ စတင်ဆောင်ရွက်ခြင်း မပြုမီတွင် Global expression အခန်းတွင်ရှိသော ကုဒ်ကို တစ်ကြိမ်သာလျှင် အလုပ်လုပ်ဆောင်စေမည်ဖြစ်သည်။ ထို့ကြောင့် လိုအပ်သည့် module များ ထည့်သွင်းရန် သို့မဟုတ် နောက်ပိုင်းတွက်ချက်ခြင်းများတွင် အသုံးပြုမည့် variable များကို တွက်ချက်ရန် ဤအရာသည် မှန်ကန်သည့် နေရာတစ်ခုဖြစ်ပါသည်။ |
Formula |
|
[string] |
အကဲဖြတ်ရန် Python formula ။ ဥပမာ - ထည့်သွင်းထားသည့် polygon layer တစ်ခု၏ ဧရိယာကို တွက်ချက်ရန် အောက်ပါအတိုင်းထည့်သွင်းနိုင်သည်- value = $geom.area()
|
Calculated (တွက်ချက်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
တွက်ချက်ထားသော field အသစ်ပါဝင်သည့် vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Calculated (တွက်ချက်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
တွက်ချက်ထားသော field အသစ်ပါဝင်သည့် vector layer |
Python code
Algorithm ID: qgis:advancedpythonfieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.6. Field (များ) ကို ချန်ထားခြင်း (Drop field(s) )
Vector layer တစ်ခုယူပြီး ရွေးချယ်ထားသည့် column များမပါဝင်သည့် တူညီသော feature များရှိသော layer အသစ်တစ်ခုကို ထုတ်ပေးပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Field (များ) ကို ဖြုတ်ချန် (drop) ထားမည့် input vector layer |
Fields to drop (ဖြုတ်ချန်မည့် field များ) |
|
[tablefield: any] [list] |
ဖြုတ်ချန် (drop) လုပ်ရန် field များ |
Remaining fields (ကျန်ရှိနေသော field များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ကျန်ရှိနေသော field များပါဝင်သည့် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Remaining fields (ကျန်ရှိနေသော field များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ကျန်ရှိနေသော field များပါဝင်သည့် vector layer |
Python code
Algorithm ID: native:deletecolumn
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.7. HStore Field ကို ခွဲထုတ်ခြင်း (Explode HStore Field)
Input layer ၏ မိတ္တူပွားတစ်ခု ဖန်တီးပေးပြီး HStore field ထဲရှိ unique key တိုင်းအတွက် field အသစ်တစ်ခုကို ပေါင်းထည့်ပေးပါသည်။
မျှော်မှန်းသော field စာရင်းသည် comma ဖြင့်ပိုင်းခြားထားသော စာရင်းတစ်ခုဖြစ်ပါသည်။ အဆိုပါ စာရင်းကို သတ်မှတ်ထားပြီးဖြစ်လျှင် ထို field များကိုသာလျှင် ပေါင်းထည့်သွားမည်ဖြစ်ပြီး HStore field သည် update ဖြစ်သွားမည်ဖြစ်သည်။ Default အားဖြင့် unique key များအားလုံးကို ပေါင်းထည့်မည်ဖြစ်သည်။
PostgreSQL HStore သည် တစ်ခုသာပါသော key-value store တစ်ခုဖြစ်ပြီး PostgreSQL နှင့် GDAL (other_tags field ပါသော OSM file တစ်ခုကို ဖတ်သောအခါ) ထဲတွင်အသုံးပြုပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
HStore field |
|
[tablefield: any] |
ဖြုတ်ချန် (Drop) လုပ်ရန် field များ |
Expected list of fields separated by a comma (Comma ဖြင့်ပိုင်းခြားထားသော မျှော်မှန်း field များစာရင်း) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] Default: ‘’ |
ထုတ်ယူရန် field များ၏ Comma ဖြင့်ပိုင်းခြားထားသောစာရင်းကို။ အဆိုပါ key များကို ဖယ်ရှားခြင်းအားဖြင့် HStore field ကို update လုပ်မည် ဖြစ်သည်။ |
Exploded |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Exploded |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Output vector layer |
Python code
Algorithm ID: native:explodehstorefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.8. Binary field ကို ထုတ်ယူခြင်း (Extract binary field)
Binary field တစ်ခုမှ ပါဝင်သည့်အကြောင်းအရာများကို ထုတ်ယူပေးပါသည်။ ၎င်းတို့ကို သီးခြားဖိုင်များတွင် သိမ်းဆည်းမည်ဖြစ်သည်။ ဖိုင်အမည်များကို ရင်းမြစ်ဇယားထဲရှိ အချက်အလက်မှ ယူထားသော တန်ဖိုးများကိုအသုံးပြုခြင်း သို့မဟုတ် ပိုမိုရှုပ်ထွေးသော expression တစ်ခုအပေါ် အခြေခံ၍ ထုတ်ယူသတ်မှတ်နိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Binary ဒေတာပါဝင်သည့် input vector layer |
Binary field |
|
[tablefield: any] |
Binary ဒေတာပါဝင်သည့် field |
File name |
|
[expression] |
Output ဖိုင်တစ်ခုချင်းစီကို အမည်ပေးရန် Field သို့မဟုတ် expression အခြေခံသော စာသား |
Destination folder (သိမ်းဆည်းမည့် folder) |
|
[folder] Default: |
Output ဖိုင်များကို သိမ်းဆည်းရန် Folder ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Folder |
|
[folder] |
Output ဖိုင်များပါဝင်သည့် folder |
Python code
Algorithm ID: native:extractbinary
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.9. Field တွက်ချက်ရာ (Field calculator)
Field calculator (စေခိုင်းချက်များ (Expressions) တွင်ကြည့်ပါ) ကိုဖွင့်ပါ။ ပံ့ပိုးပေးထားသည့် expression များနှင့် function များကို အသုံးပြုနိုင်ပါသည်။
Expression ရလာဒ်များဖြင့် layer အသစ်တစ်ခုကို ဖန်တီးပါမည်။
Model design ပြုလုပ်ရာနေရာ (The model designer) ထဲတွင် field calculator ကို အသုံးပြုသောအခါ အလွန်အသုံးဝင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
တွက်ချက်ရန် layer |
Output field name (ရလာဒ် field ၏အမည်) |
|
[string] |
ရလာဒ်များအတွက် field ၏အမည် |
Output field type (ရလာဒ် field အမျိုးအစား) |
|
[enumeration] Default: 0 |
Field အမျိုးအစား။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
Output field width (ရလာဒ် field အကျယ်) |
|
[number] Default: 10 |
ရလာဒ် field ၏ အရှည် (အနည်းဆုံး 0) |
Field precision (Field ၏တိကျမှု) |
|
[number] Default: 3 |
ရလာဒ် field ၏ တိကျမှု (အနည်းဆုံး 0 ၊ အများဆုံး 15) |
Create new field (Field အသစ်ဖန်တီးခြင်း) |
|
[boolean] Default: True |
ရလာဒ် field သည် field အသစ်တစ်ခု ဖြစ်သင့်/မဖြစ်သင့် ဆုံးဖြတ်ပါသည် |
Formula |
|
[expression] |
ရလာဒ်များ တွက်ချက်ရန်အတွက် အသုံးပြုမည့် formula |
Output file |
|
[vector: any] Default: |
Output layer ၏ သီးခြားသတ်မှတ်ချက်။
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Calculated (တွက်ချက်ထားပြီးသော) |
|
[vector: any] |
တွက်ချက်ထားသော နယ်ပယ်တန်ဖိုးများပါဝင်သော ရလဒ် layer |
Python code
Algorithm ID: native:fieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.10. Field များပြန်လည်ပြုပြင်ခြင်း (Refactor fields)
Vector layer တစ်ခုထဲရှိ attribute ဇယား၏ တည်ဆောက်ပုံကို ပြင်ဆင်ခြင်းများပြုလုပ်နိုင်ပါသည်။
Field mapping တစ်ခုကို အသုံးပြုခြင်းဖြင့် field များကို ၎င်းတို့၏ အမျိုးအစားနှင့် အမည်ထဲတွင် ပြင်ဆင်သတ်မှတ်နိုင်ပါသည်။
မူလ layer အား ပြင်ဆင်ပြောင်းလဲသွားမည် မဟုတ်ပါ။ Layer အသစ်တစ်ခု ထွက်ပေါ်လာမည်ဖြစ်ပြီး၊ ထိုထဲတွင် ထောက်ပံ့ပေးထားသည့် field mapping အရ ပြင်ဆင်ထားသော attribute ဇယားတစ်ခု ပါဝင်မည်ဖြစ်ပါသည်။
Note
Field များတွင် constraints ဖြင့် template layer တစ်ခုအသုံးပြုသောအခါ သတင်းအချက်အလက်ကို နောက်ခံအရောင်နှင့် tooltip တစ်ခုဖြင့် widget ထဲတွင် ဖော်ပြပေးမည်ဖြစ်ပါသည်။ အဆိုပါသတင်းအချက်အလက်ကို configure ပြုလုပ်နေစဉ်အတွင်း အရိပ်အမြွက်အဖြစ် မှတ်ယူရမည်။ Output layer တစ်ခုတွင် အကန့်အသတ် (constraints) ကို ထည့်သွင်းမည်မဟုတ်ပဲ ၎င်းတို့ကို algorithm ဖြင့် စစ်ဆေးခြင်း သို့မဟုတ် တွန်းအားပေးခြင်း ပြုလုပ်မည် မဟုတ်ပါ။
Refactor fields algorithm သည် အောက်ပါတို့ကို လုပ်ဆောင်ခွင့်ပြုပေးမည်ဖြစ်သည်-
Field ၏ အမည်နှင့် အမျိုးအစားများကို ပြောင်းလဲခြင်း
Field များကို ပေါင်းထည့်ခြင်းနှင့် ဖယ်ရှားခြင်း
Field များကို ပြန်လည်စီစဉ်ခြင်း
Expression များအပေါ် အခြေခံ၍ field အသစ်များကို တွက်ချက်ခြင်း
အခြား layer မှ field စာရင်းကို ထည့်သွင်းခြင်း
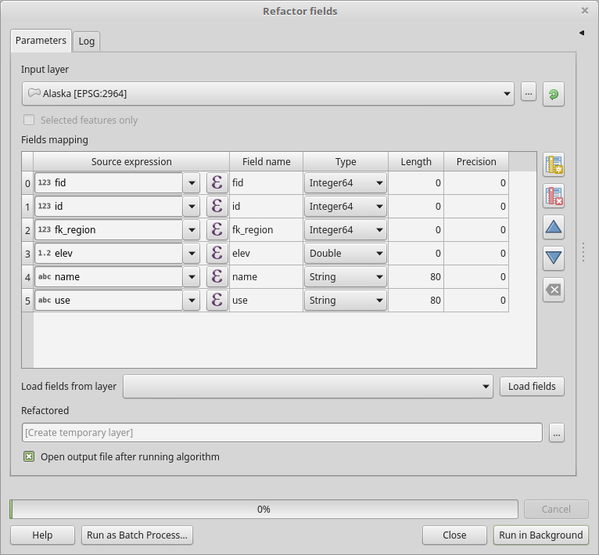
Fig. 29.125 Refactor fields dialog
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
မွမ်းမံပြင်ဆင်ရန် layer |
Fields mapping |
|
[list] |
အဓိပ္ပါယ်ဖွင့်ဆိုချက်များပါဝင်သော output field များ၏ စာရင်း။ ချိတ်တွဲထားသော ဇယားသည် ရင်းမြစ် layer ၏ field များအားလုံးကို စာရင်းပြုစုထားမည်ဖြစ်ပြီး ၎င်းတို့ကို ပြင်ဆင်တည်းဖြတ်ခြင်းများ ပြုလုပ်နိုင်ပါသည်-
ပြန်လည်အသုံးပြုလိုသည့် field တစ်ခုချင်းစီအတွက် အောက်ပါ ရွေးချယ်စရာ (option) များကို ဖြည့်ရန်လိုအပ်ပါသည်-
|
Refactored (ပြန်လည်ပြုပြင်ထားသော) |
|
[vector: any] Default: |
Output layer ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |





ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Refactored (ပြန်လည်ပြုပြင်ထားသော) |
|
[vector: any] |
ပြန်လည်ပြုပြင်ထားသော field များပါဝင်သည့် output layer |
Python code
Algorithm ID: native:refactorfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.11. Field အမည်ပြောင်းခြင်း (Rename field)
Vector layer တစ်ခုမှ လက်ရှိရှိနေသော field တစ်ခုကို အမည်ပြောင်းပေးပါသည်။
မူလ layer ကို ပြင်ဆင်ပြောင်းလဲမည် မဟုတ်ပါ။ အမည်ပြောင်းထားသော နယ်ပယ်များပါဝင်သည့် attribute ဇယားပါဝင်သော layer အသစ်တစ်ခု ထုတ်ပေးမည် ဖြစ်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Field to rename (အမည်ပြောင်းရန် field) |
|
[tablefield: any] |
ပြောင်းလဲမည့် field |
New field name (Field အမည်အသစ်) |
|
[string] |
Field အမည် အသစ် |
Renamed (အမည်ပြောင်းထားပြီးသော) |
|
[vector: input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output layer ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Renamed (အမည်ပြောင်းထားပြီးသော) |
|
[vector: input နှင့်အတူတူဖြစ်ပါသည်] |
အမည်ပြောင်းလဲထားသည့် field ပါဝင်သည့် output layer |
Python code
Algorithm ID: qgis:renametablefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.12. Field များကို ဆက်လက်ထိန်းသိမ်းထားခြင်း (Retain fields)
Vector layer အသစ်တစ်ခုယူပြီး ရွေးချယ်ထားသည့် field များသာ ဆက်လက်ထိန်းသိမ်းထားရှိသော layer အသစ်တစ်ခု ထုတ်ပေးပါသည်။ အခြား field များအားလုံးကို ဖြုတ်ချန် (drop) လိုက်မည် ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Fields to retain (ဆက်လက်ထိန်းသိမ်းထားရှိမည့် field များ) |
|
[tablefield: any] [list] |
Layer ထဲတွင် ဆက်လက်ထားရှိမည့် field များစာရင်း |
Retained fields (ဆက်လက်ထိန်းသိမ်းထားရှိသော field များ) |
|
[vector: input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output layer ၏ သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Retained fields (ဆက်လက်ထိန်းသိမ်းထားရှိသော field များ) |
|
[vector: input နှင့်အတူတူဖြစ်ပါသည်] |
ဆက်လက်ထိန်းသိမ်းထားသည့် field များပါဝင်သည့် output layer |
Python code
Algorithm ID: native:retainfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.21.13. စာသားမှ ဒဿမဂဏန်းသို့ (Text to float)
Vector layer တစ်ခုထဲရှိ ပေးထားသည့် attribute တစ်ခု၏ အမျိုးအစားကို မွမ်းမံပြင်ဆင်ပေးပါသည်၊ ဂဏန်းဆိုင်ရာ (numeric) string များပါဝင်သည့် စာသား attribute တစ်ခုကို ဂဏန်းဆိုင်ရာ (numeric) attribute တစ်ခုအဖြစ်သို့ ပြောင်းလဲပေးခြင်းဖြစ်ပါသည် (ဥပမာ၊ ‘1’ မှ 1.0)။
Algorithm သည် vector layer အသစ်တစ်ခုကို ဖန်တီးမည်ဖြစ်သောကြောင့် မူလ layer ကို မွမ်းမံပြင်ဆင်မည်မဟုတ်ပါ။
ပြောင်းလဲမှုသည် မဖြစ်နိုင်ပါက ရွေးချယ်ထားသည့် column တွင် NULL တန်ဖိုးများ ရှိနေပါလိမ့်မည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Text attribute to convert to float (Float သို့ပြောင်းလဲရန် စာသား attribute) |
|
[tablefield: string] |
Float field တစ်ခုအဖြစ်သို့ပြောင်းလဲရန် input layer အတွက် စာသား (string) field |
Float from text (စာသားမှ Float သို့) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Float from text (စာသားမှ Float သို့) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
စာသား (string) field မှ float (ဒဿမဂဏန်း) field တစ်ခုသို့ ပြောင်းလဲထားသည်များပါဝင်သော output vector layer |
Python code
Algorithm ID: qgis:texttofloat
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။