29.1.20. Vector တွင်ရွေးချယ်ခြင်း (Vector selection)
29.1.20.1. Attribute ဖြင့်ထုတ်ယူခြင်း (Extract by attribute)
Input layer တစ်ခုမှ vector layer နှစ်ခု ကိုဖန်တီးပေးပါသည် - ပထမတစ်ခုတွင် ကိုက်ညီမှုရှိသော feature များသာပါဝင်ပြီး ဒုတိယတစ်ခုတွင် ကိုက်ညီမှုမရှိသော feature များအားလုံးပါဝင်ပါသည်။
ရလာဒ်ထုတ်ပေးသည့် layer တွင် feature များထည့်သွင်းခြင်းအတွက် စံသတ်မှတ်ချက်သည် input layer မှ attribute တစ်ခု၏ တန်ဖိုးများအပေါ် အခြေခံပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Feature များ ထုတ်ယူရန် Layer။ |
Selection attribute (ရွေးချယ်မှု အချက်အလက်) |
|
[tablefield: any] |
Layer ၏ filter (စစ်ထုတ်) သော field |
Operator (+ - * / စသည့်သင်္ကေတ) |
|
[enumeration] Default: 0 |
အမျိုးမျိုးသော operator (သင်္ချာဆိုင်ရာ သို့မဟုတ် လော့ဂျစ်ဆိုင်ရာလုပ်ဆောင်ချက်များကို ကိုယ်စားပြုသည့်အရာ) များကို အသုံးပြုနိုင်ပါသည်-
|
Value (တန်ဖိုး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
အကဲဖြတ်ရန် တန်ဖိုး |
Extracted (attribute) (ထုတ်ယူထားသော (အချက်အလက်)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ကိုက်ညီမှုရှိသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Extracted (non-matching) (ထုတ်ယူထားသော (ကိုက်ညီမှုမရှိသော)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ကိုက်ညီမှုမရှိသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extracted (attribute) (ထုတ်ယူထားသော (အချက်အလက်)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer မှ ကိုက်ညီမှုရှိသော feature များပါဝင်သည့် vector layer |
Extracted (non-matching) (ထုတ်ယူထားသော (ကိုက်ညီမှုမရှိသော)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer မှ ကိုက်ညီမှုမရှိသော feature များပါဝင်သည့် vector layer |
Python code
Algorithm ID: qgis:extractbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.2. Expression ဖြင့် ထုတ်ယူခြင်း (Extract by expression)
Input layer တစ်ခုမှ vector layer နှစ်ခု ကိုဖန်တီးပေးပါသည် - ပထမတစ်ခုတွင် ကိုက်ညီမှုရှိသော feature များသာပါဝင်ပြီး ဒုတိယတစ်ခုတွင် ကိုက်ညီမှုမရှိသော feature များအားလုံးပါဝင်ပါသည်။
ရလာဒ်ထုတ်ပေးသည့် layer တွင် feature များထည့်သွင်းခြင်းအတွက် စံသတ်မှတ်ချက်သည် QGIS expression တစ်ခုအပေါ် အခြေခံပါသည်။ Expression အကြောင်းကို ပိုမိုသိရှိရန်အတွက် စေခိုင်းချက်များ (Expressions) တွင်ကြည့်ပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Expression |
|
[expression] |
Vector layer ကို စစ်ထုတ် (filter) ရန် expression |
Matching features (ကိုက်ညီမှုရှိသော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ကိုက်ညီမှုရှိသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Non-matching (ကိုက်ညီမှုမရှိသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ကိုက်ညီမှုမရှိသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Matching features (ကိုက်ညီမှုရှိသော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer မှ ကိုက်ညီမှုရှိသော feature များပါဝင်သည့် vector layer |
Non-matching (ကိုက်ညီမှုမရှိသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer မှ ကိုက်ညီမှုမရှိသော feature များပါဝင်သည့် vector layer |
Python code
Algorithm ID: qgis:extractbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.3. တည်နေရာဖြင့် ထုတ်ယူခြင်း (Extract by location)
Input layer တစ်ခုမှ ကိုက်ညီမှုရှိသော feature များသာ ပါဝင်သော vector layer အသစ်တစ်ခု ဖန်တီးပေးပါသည်။
ရလာဒ် layer တွင် feature များထည့်သွင်းခြင်းအတွက် စံသတ်မှတ်ချက်သည် feature တစ်ခုချင်းစီနှင့် ထပ်ဆောင်း layer တစ်ခုထဲရှိ feature များအကြားရှိ တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relationship) အပေါ်တွင် အခြေခံပါသည်။
See also
တည်နေရာဖြင့် ရွေးချယ်ခြင်း (Select by location) ၊ အကွာအဝေးအတွင်းထုတ်ယူခြင်း (Extract within distance)
တည်နေရာဆိုင်ရာ ဆက်နွယ်မှုများကို လေ့လာခြင်း (Exploring spatial relations)
Geometric predicate ဆိုသည်မှာ feature တစ်ခုနှင့် အခြား feature တစ်ခု၏ တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ၎င်းတို့၏ ဂျီဩမေတြီများမည်သို့ မျှဝေနေရာယူနေသလဲဆိုသည်ကို နှိုင်းယှဉ်ခြင်းအားဖြင့် ဆုံးဖြတ်ရန်အသုံးပြုသော boolean (မှန်/မှား) function များကို ဆိုလိုပါသည်။
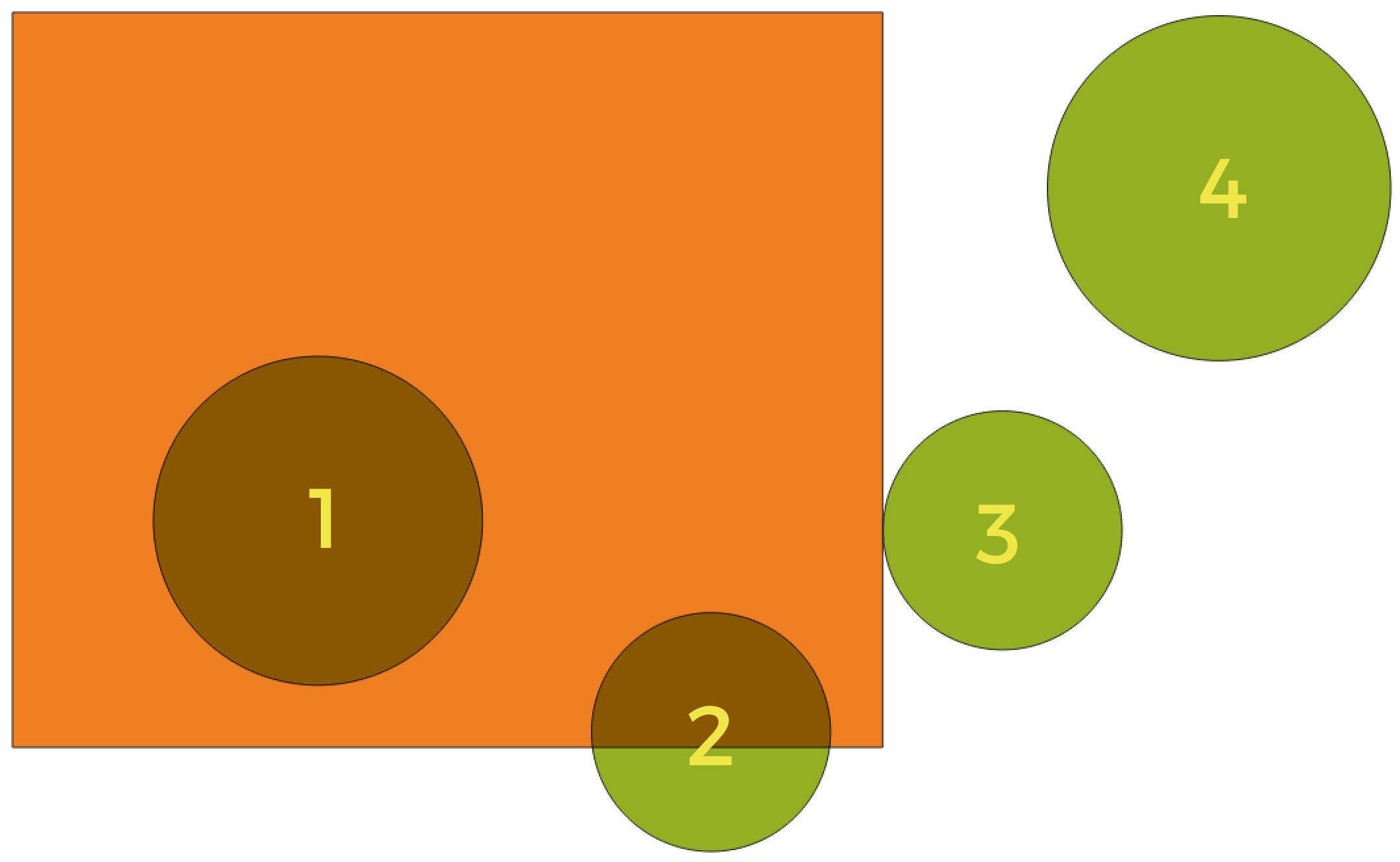
Fig. 29.123 Layer များအကြား တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ရှာဖွေခြင်း
အထက်ဖော်ပြပါပုံကိုအသုံးပြုပြီး လိမ္မော်ရောင် ထောင့်မှန်စတုဂံ feature များကို အစိမ်းရောင်စက်ဝိုင်းများနှင့် တည်နေရာအရ နှိုင်းယှဉ်ပြီး အစိမ်းရောင်စက်ဝိုင်းများကို ရှာဖွေပါသည်။ အသုံးပြုနိုင်သော geometric predicate များမှာ-
- Intersect (ထိဖြတ်ခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့်ထိဖြတ်/မဖြတ်ကို စစ်ဆေးပေးပါသည်။ ထိဖြတ်နေလျှင် (နေရာအစိတ်အပိုင်းတစ်ခုကိုမျှဝေသုံးစွဲခြင်း - ထပ်နေခြင်း သို့မဟုတ် ထိနေခြင်း ကိုဆိုလိုပါသည်) 1 (အမှန်) တန်ဖိုးကို ထုတ်ပေးပြီး မဖြစ်လျှင် 0 တန်ဖိုးကိုထုတ်ပေးပါသည်။ အထက်ဖော်ပြပါ ဓာတ်ပုံတွင် စက်ဝိုင်း 1၊ 2 နှင့် 3 တို့ကိုထုတ်ပေးပါသည်။
- Contain (ပါဝင်ခြင်း)
b ၏အမှတ်များသည် a ၏အပြင်ဘက်တွင် မရှိလျှင်နှင့် မရှိမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပြီး အနည်းဆုံး b ၏အတွင်းဘက်ကတစ်မှတ်သည် a ၏အတွင်းဘက်တွင် ရှိရပါမည်။ ပုံတွင် မည်သည့်စက်ဝိုင်းမှ ပြန်ထုတ်မပေးပါ သို့သော် ၎င်းသည် စက်ဝိုင်း 1 အပြည့်အဝပါဝင်သောကြောင့် အခြားနည်းဖြင့်ရှာဖွေလျှင် ထောင့်မှန်စတုဂံ ကိုပြန်ထုတ်ပေးပါမည်။ ယခုနည်းလမ်းလည်း are within (အတွင်းတွင်ရှိခြင်း) နှင့် ဆန့်ကျင်ဘက်ဖြစ်ပါသည်။
- Disjoint (အဆက်ဖြုတ်ခြင်း)
ဂျီဩမေတြီ များသည် မည်သည့်အစိတ်အပိုင်းမျှ နေရာချင်းမျှဝေမနေလျှင် (ထပ်မနေ၊ ထိမနေခြင်း ကိုဆိုလိုပါသည်) တန်ဖိုး 1 (အမှန်) ကို ထုတ်ပေးပါမည်။ စက်ဝိုင်း 4 ကိုသာ ပြန်ထုတ်ပေးမည်ဖြစ်သည်။
- Equal (ညီမျှခြင်း)
ဂျီဩမေတြီ များသည်လုံးဝ တစ်ပုံစံတည်း တူနေလျှင် သို့မဟုတ် တူနေမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်းများကို ထုတ်မပေးပါ။
- Touch (ထိနေခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြားဂျီဩမေတြီ တစ်ခုနှင့် ထိ/မထိ စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် အနည်းဆုံး ဘုံ point တစ်ခုရှိနေပြီး ၎င်းတို့၏အတွင်းပိုင်းများသည် ထိဖြတ်မနေသောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 3 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Overlap (ထပ်နေခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့် ထပ်/မထပ် ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် နေရာခြင်း မျှဝေနေပြီး အရွယ်အစားလည်း တူညီနေသော်လည်း တစ်ခုထဲတွင် အခြားတစ်ခုက လုံးဝဝင်ရောက်နေခြင်း မဟုတ်လျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 2 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Are within (အတွင်းတွင်ရှိခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုအတွင်းတွင်ရှိ/မရှိ ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီ a သည် geometry b ၏အတွင်းတွင် လုံးဝကျရောက်နေလျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 1 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Cross (ကန့်လန့်ဖြတ်နေခြင်း)
အသုံးပြုထားသော ဂျီဩမေတြီ များသည် အားလုံးမဟုတ်တောင် အချို့သော အတွင်းပိုင်း ဘုံ point များရှိနေပြီး အမှန်တကယ် ကန့်လန့်ဖြတ်နေခြင်း သည် အမြင့်ဆုံး ဂျီဩမေတြီ ထက်နိမ့်သော dimension တစ်ခုတွင် ဖြစ်သောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ ဥပမာ- polygon တစ်ခုကိုဖြတ်သော line တစ်ခုသည် line အဖြစ် ကန့်လန့်ဖြတ်ပါမည် (အမှန်)။ ကန့်လန့်ဖြတ်နေသော line နှစ်ခုသည် point အဖြစ် ဖြတ်ပါလိမ့်မည် (အမှန်)။ Polygon နှစ်ခုသည် polygon တစ်ခုအဖြစ် ဖြတ်ပါလိမ့်မည် (အမှား)။ ဓာတ်ပုံတွင် စက်ဝိုင်းများကို ပြန်ထုတ်မပေးပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extract features from (Feature များထုတ်ယူမည့် layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Where the features (geometric predicate) |
|
[enumeration] [list] Default: [0] |
ရွေးချယ်ခြင်းပြုနိုင်စေရန်အတွက် Input feature တွင် ရှိသင့်သည့် intersect feature တစ်ခုနှင့် တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relation) အမျိုးအစား။ အောက်ပါတို့အနက်မှ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို၍ ရွေးချယ်နိုင်ပါသည်-
အခြေအနေတစ်ခုထက်ပို၍ ရွေးချယ်ခဲ့ပါက ၎င်းတို့အနက်မှ အနည်းဆုံးတစ်ခု (OR operation) သည် feature တစ်ခုထုတ်ယူရန်အတွက် ကိုက်ညီနေရမည်ဖြစ်သည်။ |
By comparing to the features from |
|
[vector: any] |
ထိဖြတ်ခြင်း vector layer |
Extracted (location) (ထုတ်ယူပြီးသော (တည်နေရာ)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
နှိုင်းယှဉ်ခြင်း layer ထဲရှိ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပိုသော feature များဖြင့် ရွေးချယ်ထားသည့် တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relationship) ရှိသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extracted (location) (ထုတ်ယူပြီးသော (တည်နေရာ)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
နှိုင်းယှဉ်ခြင်း layer ထဲရှိ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပိုသော feature များဖြင့် ရွေးချယ်ထားသည့် တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relationship) ရှိသော input layer မှ feature များပါဝင်သည့် vector layer။ |
Python code
Algorithm ID: qgis:extractbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.4. အကွာအဝေးအတွင်းထုတ်ယူခြင်း (Extract within distance)
Input layer တစ်ခုမှ ကိုက်ညီမှုရှိသော feature များသာ ပါဝင်သော vector layer အသစ်တစ်ခု ဖန်တီးပေးပါသည်။ ထပ်ဆောင်း ရည်ညွှန်း layer တစ်ခုထဲရှိ feature များမှ တိတိကျကျသတ်မှတ်ထားသော အများဆုံးအကွာအဝေး အတွင်းတွင် ရှိနေသည့်အခါတိုင်းတွင် feature များကို မိတ္တူကူးယူပေးမည် ဖြစ်ပါသည်။
See also
အကွာအဝေးအတွင်း ရွေးချယ်ခြင်း (Select within distance) ၊ တည်နေရာဖြင့် ထုတ်ယူခြင်း (Extract by location)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extract features from (Feature များထုတ်ယူမည့် layer) |
|
[vector: any] |
Feature များကို မိတ္တူကူးမည့် input vector layer |
By comparing to the features from |
|
[vector: any] |
နီးစပ်မှု (closeness) အတွက်အသုံးပြုမည့် feature များပါဝင်သော Vector layer ။ |
Where the features are within |
|
[number] Default: 100 |
ရည်ညွှန်း feature များ ပတ်လည်ရှိ အများဆုံး အကွာအဝေး။ ထိုအကွာအဝေးအတွင်းတွင် ရှိသော input feature များကို ရွေးချယ်မည်ဖြစ်သည်။ |
Modify current selection by |
|
[enumeration] Default: 0 |
Algorithm ၏ ရွေးချယ်ခြင်းကို မည်သို့စီမံသင့်သည်ကို ရွေးချယ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
|
Extracted (location) (ထုတ်ယူထားပြီးသော (တည်နေရာ)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ရည်ညွှန်း feature များမှ သတ်မှတ်ထားသော အကွာအဝေးအတွင်းရှိသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extracted (location) (ထုတ်ယူထားပြီးသော (တည်နေရာ)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရည်ညွှန်း feature များမှ အကွာအဝေးအခြေအနေနှင့် ကိုက်ညီသော input layer မှ feature များပါဝင်သည့် vector layer။ |
Python code
Algorithm ID: native:extractwithindistance
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.5. ဂျီဩမေတြီ အမျိုးအစားဖြင့် စစ်ထုတ်ခြင်း (Filter by geometry type)
Feature များကို ၎င်းတို့၏ ဂျီဩမေတြီအမျိုးအစားဖြင့် စစ်ထုတ်မည်ဖြစ်ပါသည်။ ဝင်ရောက်လာသော feature များကို ၎င်းတို့တွင် point တစ်ခု ၊ line သို့မဟုတ် polygon ဂျီဩမေတြီ ရှိခြင်း မရှိခြင်း အပေါ်တွင်အခြေခံပြီး ရလာဒ်အမျိုးမျိုး ထုတ်ပေးမည် ဖြစ်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
အကဲဖြတ်ရန် layer |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Point features Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: point] |
Point များပါသည့် layer |
Line features Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: line] |
Line များပါသည့် layer |
Polygon features Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: polygon] |
Polygon များပါသည့် layer |
Features with no geometry Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[table] |
ဂျီဩမေတြီများမပါဝင်သော (Geometry-less) vector layer |
Python code
Algorithm ID: native:filterbygeometry
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.6. ကျပန်းထုတ်ယူခြင်း (Random extract)
Vector layer တစ်ခုကို ယူပြီး input layer ထဲရှိ feature များအစု (subset) တစ်ခုသာလျှင် ပါဝင်သည့် layer အသစ်တစ်ခုကို ထုတ်ပေးပါသည်။
အစု (subset) ကို feature ID များအပေါ်တွင် အခြေခံပြီး ကျပန်းသတ်မှတ်ပါသည်။ အစုထဲရှိ စုစုပေါင်း feature အရေအတွက်ကို သတ်မှတ်ရန် ရာခိုင်နှုန်း (percentage) သို့မဟုတ် အရေအတွက် (count) တန်ဖိုးတစ်ခုကို အသုံးပြုပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Feature များကို ရွေးချယ်ရန် ရင်းမြစ် vector layer |
Method (နည်းလမ်း) |
|
[enumeration] Default: 0 |
ကျပန်းရွေးချယ်ခြင်း နည်းလမ်းများ။ အောက်ပါတို့အနက်မှ တစ်ခုဖြစ်ပါသည်-
|
Number/percentage of selected features (ရွေးချယ်ထားသည့် feature များ၏ အရေအတွက်/ရာခိုင်နှုန်း) |
|
[number] Default: 10 |
ရွေးချယ်ရန် feature များ၏ အရေအတွက် သို့မဟုတ် ရာခိုင်နှုန်း |
Extracted (random) (ထုတ်ယူထားပြီးသော (ကျပန်း)) |
|
[vector: any] Default: |
ကျပန်းရွေးချယ်ထားသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extracted (random) (ထုတ်ယူထားပြီးသော (ကျပန်း)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer မှ ကျပန်းရွေးချယ်ထားသည့် feature များပါဝင်သည့် vector layer |
Python code
Algorithm ID: qgis:randomextract
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.7. Subset များအတွင်း ကျပန်းထုတ်ယူခြင်း (Random extract within subsets)
Vector layer တစ်ခုကို ယူပြီး input layer ထဲရှိ feature များအစု (subset) တစ်ခုသာလျှင် ပါဝင်သည့် layer အသစ်တစ်ခုကို ထုတ်ပေးပါသည်။
အစု (subset) ကို feature ID များအပေါ်တွင် အခြေခံပြီး ကျပန်းသတ်မှတ်ပါသည်။ အစုထဲရှိ စုစုပေါင်း feature အရေအတွက်ကို သတ်မှတ်ရန် ရာခိုင်နှုန်း (percentage) သို့မဟုတ် အရေအတွက် (count) တန်ဖိုးတစ်ခုကို အသုံးပြုပါသည်။ ရာခိုင်နှုန်း/အရေအတွက် တန်ဖိုးကို layer တစ်ခုလုံးအတွက် အသုံးပြုမည်မဟုတ်ပါ၊ သို့သော် အမျိုးအစား (category) တစ်ခုချင်းစီတွင် အသုံးပြုသွားမည်ဖြစ်သည်။ အမျိုးအစား (category) များကို ပေးထားသည့် အချက်အလက် (attribute) တစ်ခုအရ သတ်မှတ်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Feature များကို ရွေးချယ်ရန် vector layer |
ID field |
|
[tablefield: any] |
Feature များကို ရွေးချယ်ရန် ရင်းမြစ် vector layer ၏ အမျိုးအစား (category) |
Method (နည်းလမ်း) |
|
[enumeration] Default: 0 |
ကျပန်းရွေးချယ်ခြင်း နည်းလမ်း။ အောက်ပါတို့အနက်မှ တစ်ခုဖြစ်ပါသည်-
|
Number/percentage of selected features (ရွေးချယ်ထားသည့် feature များ၏ အရေအတွက်/ရာခိုင်နှုန်း) |
|
[number] Default: 10 |
ရွေးချယ်ရန် feature များ၏ အရေအတွက် သို့မဟုတ် ရာခိုင်နှုန်း |
Extracted (random stratified) (ထုတ်ယူထားပြီးသော (ကျပန်းအလွှာခွဲ)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ကျပန်းရွေးချယ်ထားသော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Extracted (random stratified) (ထုတ်ယူထားပြီးသော (ကျပန်းအလွှာခွဲ)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer မှ ကျပန်းရွေးချယ်ထားသည့် feature များပါဝင်သည့် vector layer |
Python code
Algorithm ID: qgis:randomextractwithinsubsets
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.8. ကျပန်းရွေးချယ်ခြင်း (Random selection)
Vector layer တစ်ခုကို ယူပြီး ၎င်း feature များ၏ အစု (subset) တစ်ခုကို ရွေးချယ်ပေးပါသည်။ ဤ algorithm သည် layer အသစ်တစ်ခု ထုတ်ပေးမည် မဟုတ်ပါ။
အစု (subset) ကို feature ID များအပေါ်တွင် အခြေခံပြီး ကျပန်းသတ်မှတ်ပါသည်။ အစုထဲရှိ စုစုပေါင်း feature အရေအတွက်ကို သတ်မှတ်ရန် ရာခိုင်နှုန်း (percentage) သို့မဟုတ် အရေအတွက် (count) တန်ဖိုးတစ်ခုကို အသုံးပြုပါသည်။
Default menu -
See also
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ရွေးချယ်ခြင်းများအတွက် vector layer |
Method (နည်းလမ်း) |
|
[enumeration] Default: 0 |
ကျပန်းရွေးချယ်ခြင်း နည်းလမ်း။ အောက်ပါတို့အနက်မှ တစ်ခုဖြစ်ပါသည်-
|
Number/percentage of selected features (ရွေးချယ်ထားသည့် feature များ၏ အရေအတွက်/ရာခိုင်နှုန်း) |
|
[number] Default: 10 |
ရွေးချယ်ရန် feature များ၏ အရေအတွက် သို့မဟုတ် ရာခိုင်နှုန်း |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသည့် feature များပါဝင်သော input layer |
Python code
Algorithm ID: qgis:randomselection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.9. Subset များအတွင်း ကျပန်းရွေးချယ်ခြင်း (Random selection within subsets)
Vector layer တစ်ခုကို ယူပြီး ၎င်း feature များ၏ အစု (subset) တစ်ခုကို ရွေးချယ်ပေးပါသည်။ ဤ algorithm သည် layer အသစ်တစ်ခု ထုတ်ပေးမည် မဟုတ်ပါ။
အစု (subset) ကို feature ID များအပေါ်တွင် အခြေခံပြီး ကျပန်းသတ်မှတ်ပါသည်။ အစုထဲရှိ စုစုပေါင်း feature အရေအတွက်ကို သတ်မှတ်ရန် ရာခိုင်နှုန်း (percentage) သို့မဟုတ် အရေအတွက် (count) တန်ဖိုးတစ်ခုကို အသုံးပြုပါသည်။
ရာခိုင်နှုန်း/အရေအတွက် တန်ဖိုးကို layer တစ်ခုလုံးအတွက် အသုံးပြုမည်မဟုတ်ပါ၊ သို့သော် အမျိုးအစား (category) တစ်ခုချင်းစီတွင် အသုံးပြုသွားမည်ဖြစ်သည်။
ပေးထားသည့် အချက်အလက် (attribute) တစ်ခုအရ အမျိုးအစား (category) များကို သတ်မှတ်မည်ဖြစ်ပြီး ၎င်းကို algorithm အတွက် input parameter တစ်ခုအဖြစ်လည်း သတ်မှတ်မည် ဖြစ်သည်။
Output အသစ်များကို ဖန်တီးမည် မဟုတ်ပါ။
Default menu -
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Feature များ ရွေးချယ်မည့် vector layer |
ID field |
|
[tablefield: any] |
Feature များရွေးချယ်မည့် input layer ၏ အမျိုးအစား (category) |
Method (နည်းလမ်း) |
|
[enumeration] Default: 0 |
ကျပန်းရွေးချယ်ခြင်း နည်းလမ်း။ အောက်ပါတို့အနက်မှ တစ်ခုဖြစ်ပါသည်-
|
Number/percentage of selected features (ရွေးချယ်ထားသည့် feature များ၏ အရေအတွက်/ရာခိုင်နှုန်း) |
|
[number] Default: 10 |
ရွေးချယ်ရန် feature များ၏ အရေအတွက် သို့မဟုတ် ရာခိုင်နှုန်း |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသည့် feature များပါဝင်သော input layer |
Python code
Algorithm ID: qgis:randomselectionwithinsubsets
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.10. အချက်အလက်(attribute)ဖြင့် ရွေးချယ်ခြင်း) (Select by attribute)
Vector layer တစ်ခုထဲတွင် ရွေးချယ်ခြင်းတစ်ခု ဖန်တီးပေးပါသည်။
Feature များ ရွေးချယ်ခြင်းအတွက် စံသတ်မှတ်ချက်သည် input layer မှ အချက်အလက်တစ်ခု၏ တန်ဖိုးများအပေါ်တွင် အခြေခံပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Feature များ ရွေးချယ်မည့် vector layer |
Selection attribute (ရွေးချယ်ခြင်း အချက်အလက်) |
|
[tablefield: any] |
Layer ၏ စစ်ထုတ် (filter) သော field |
Operator (+ - * / စသည့်သင်္ကေတ) |
|
[enumeration] Default: 0 |
အမျိုးမျိုးသော operator (သင်္ချာဆိုင်ရာ သို့မဟုတ် လော့ဂျစ်ဆိုင်ရာလုပ်ဆောင်ချက်များကို ကိုယ်စားပြုသည့်အရာ) များကို အသုံးပြုနိုင်ပါသည်-
|
Value (တန်ဖိုး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
အကဲဖြတ်ရန် တန်ဖိုး |
Modify current selection by |
|
[enumeration] Default: 0 |
Algorithm ၏ ရွေးချယ်ခြင်းကို မည်သို့စီမံသင့်သည်ကို ရွေးချယ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသည့် feature များပါဝင်သော input layer |
Python code
Algorithm ID: qgis:selectbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.11. Expression ဖြင့် ရွေးချယ်ခြင်း (Select by expression)
Vector layer တစ်ခုထဲတွင် ရွေးချယ်မှုတစ်ခုကို ဖန်တီးပေးပါသည်။
Feature များရွေးချယ်ခြင်းအတွက် စံသတ်မှတ်ချက်သည် QGIS expression တစ်ခုပေါ်တွင် အခြေခံပါသည်။ Expression နှင့်ပတ်သက်၍ ပိုမိုသိရှိလိုပါက စေခိုင်းချက်များ (Expressions) တွင် လေ့လာနိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Expression |
|
[expression] |
Input layer ကို စစ်ထုတ် (filter) ရန် Expression |
Modify current selection by |
|
[enumeration] Default: 0 |
Algorithm ၏ ရွေးချယ်ခြင်းကို မည်သို့စီမံသင့်သည်ကို ရွေးချယ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသည့် feature များပါဝင်သော input layer |
Python code
Algorithm ID: qgis:selectbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.12. တည်နေရာဖြင့် ရွေးချယ်ခြင်း (Select by location)
Vector layer တစ်ခုထဲတွင် ရွေးချယ်မှုတစ်ခုကို ဖန်တီးပေးပါသည်။
Feature များရွေးချယ်ခြင်းအတွက် စံသတ်မှတ်ချက်သည် feature တစ်ခုချင်းစီနှင့် ထပ်ဆောင်း layer တစ်ခုထဲရှိ feature များအကြားရှိ တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relationship) အပေါ် အခြေခံပါသည်။
Default menu -
See also
တည်နေရာဖြင့် ထုတ်ယူခြင်း (Extract by location) ၊ အကွာအဝေးအတွင်း ရွေးချယ်ခြင်း (Select within distance)
တည်နေရာဆိုင်ရာ ဆက်နွယ်မှုများကို လေ့လာခြင်း (Exploring spatial relations)
Geometric predicate ဆိုသည်မှာ feature တစ်ခုနှင့် အခြား feature တစ်ခု၏ တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ၎င်းတို့၏ ဂျီဩမေတြီများမည်သို့ မျှဝေနေရာယူနေသလဲဆိုသည်ကို နှိုင်းယှဉ်ခြင်းအားဖြင့် ဆုံးဖြတ်ရန်အသုံးပြုသော boolean (မှန်/မှား) function များကို ဆိုလိုပါသည်။
Fig. 29.124 Layer များအကြား တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ရှာဖွေခြင်း
အထက်ဖော်ပြပါပုံကိုအသုံးပြုပြီး လိမ္မော်ရောင် ထောင့်မှန်စတုဂံ feature များကို အစိမ်းရောင်စက်ဝိုင်းများနှင့် တည်နေရာအရ နှိုင်းယှဉ်ပြီး အစိမ်းရောင်စက်ဝိုင်းများကို ရှာဖွေပါသည်။ အသုံးပြုနိုင်သော geometric predicate များမှာ-
- Intersect (ထိဖြတ်ခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့်ထိဖြတ်/မဖြတ်ကို စစ်ဆေးပေးပါသည်။ ထိဖြတ်နေလျှင် (နေရာအစိတ်အပိုင်းတစ်ခုကိုမျှဝေသုံးစွဲခြင်း - ထပ်နေခြင်း သို့မဟုတ် ထိနေခြင်း ကိုဆိုလိုပါသည်) 1 (အမှန်) တန်ဖိုးကို ထုတ်ပေးပြီး မဖြစ်လျှင် 0 တန်ဖိုးကိုထုတ်ပေးပါသည်။ အထက်ဖော်ပြပါ ဓာတ်ပုံတွင် စက်ဝိုင်း 1၊ 2 နှင့် 3 တို့ကိုထုတ်ပေးပါသည်။
- Contain (ပါဝင်ခြင်း)
b ၏အမှတ်များသည် a ၏အပြင်ဘက်တွင် မရှိလျှင်နှင့် မရှိမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပြီး အနည်းဆုံး b ၏အတွင်းဘက်ကတစ်မှတ်သည် a ၏အတွင်းဘက်တွင် ရှိရပါမည်။ ပုံတွင် မည်သည့်စက်ဝိုင်းမှ ပြန်ထုတ်မပေးပါ သို့သော် ၎င်းသည် စက်ဝိုင်း 1 အပြည့်အဝပါဝင်သောကြောင့် အခြားနည်းဖြင့်ရှာဖွေလျှင် ထောင့်မှန်စတုဂံ ကိုပြန်ထုတ်ပေးပါမည်။ ယခုနည်းလမ်းလည်း are within (အတွင်းတွင်ရှိခြင်း) နှင့် ဆန့်ကျင်ဘက်ဖြစ်ပါသည်။
- Disjoint (အဆက်ဖြုတ်ခြင်း)
ဂျီဩမေတြီ များသည် မည်သည့်အစိတ်အပိုင်းမျှ နေရာချင်းမျှဝေမနေလျှင် (ထပ်မနေ၊ ထိမနေခြင်း ကိုဆိုလိုပါသည်) တန်ဖိုး 1 (အမှန်) ကို ထုတ်ပေးပါမည်။ စက်ဝိုင်း 4 ကိုသာ ပြန်ထုတ်ပေးမည်ဖြစ်သည်။
- Equal (ညီမျှခြင်း)
ဂျီဩမေတြီ များသည်လုံးဝ တစ်ပုံစံတည်း တူနေလျှင် သို့မဟုတ် တူနေမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်းများကို ထုတ်မပေးပါ။
- Touch (ထိနေခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြားဂျီဩမေတြီ တစ်ခုနှင့် ထိ/မထိ စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် အနည်းဆုံး ဘုံ point တစ်ခုရှိနေပြီး ၎င်းတို့၏အတွင်းပိုင်းများသည် ထိဖြတ်မနေသောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 3 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Overlap (ထပ်နေခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့် ထပ်/မထပ် ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် နေရာခြင်း မျှဝေနေပြီး အရွယ်အစားလည်း တူညီနေသော်လည်း တစ်ခုထဲတွင် အခြားတစ်ခုက လုံးဝဝင်ရောက်နေခြင်း မဟုတ်လျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 2 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Are within (အတွင်းတွင်ရှိခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုအတွင်းတွင်ရှိ/မရှိ ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီ a သည် geometry b ၏အတွင်းတွင် လုံးဝကျရောက်နေလျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 1 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Cross (ကန့်လန့်ဖြတ်နေခြင်း)
အသုံးပြုထားသော ဂျီဩမေတြီ များသည် အားလုံးမဟုတ်တောင် အချို့သော အတွင်းပိုင်း ဘုံ point များရှိနေပြီး အမှန်တကယ် ကန့်လန့်ဖြတ်နေခြင်း သည် အမြင့်ဆုံး ဂျီဩမေတြီ ထက်နိမ့်သော dimension တစ်ခုတွင် ဖြစ်သောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ ဥပမာ- polygon တစ်ခုကိုဖြတ်သော line တစ်ခုသည် line အဖြစ် ကန့်လန့်ဖြတ်ပါမည် (အမှန်)။ ကန့်လန့်ဖြတ်နေသော line နှစ်ခုသည် point အဖြစ် ဖြတ်ပါလိမ့်မည် (အမှန်)။ Polygon နှစ်ခုသည် polygon တစ်ခုအဖြစ် ဖြတ်ပါလိမ့်မည် (အမှား)။ ဓာတ်ပုံတွင် စက်ဝိုင်းများကို ပြန်ထုတ်မပေးပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Select features from (Feature များရွေးချယ်မည့် layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Where the features (geometric predicate) |
|
[enumeration] [list] Default: [0] |
ရွေးချယ်ခြင်းပြုနိုင်စေရန်အတွက် Input feature တွင် ရှိသင့်သည့် intersect feature တစ်ခုနှင့် တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relation) အမျိုးအစား။ အောက်ပါတို့အနက်မှ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို၍ ရွေးချယ်နိုင်ပါသည်-
အခြေအနေတစ်ခုထက်ပို၍ ရွေးချယ်ခဲ့ပါက ၎င်းတို့အနက်မှ အနည်းဆုံးတစ်ခု (OR operation) သည် feature တစ်ခုထုတ်ယူရန်အတွက် ကိုက်ညီနေရမည်ဖြစ်သည်။ |
By comparing to the features from |
|
[vector: any] |
ထိဖြတ်ခြင်း vector layer |
Modify current selection by |
|
[enumeration] Default: 0 |
Algorithm ၏ ရွေးချယ်ခြင်းကို မည်သို့စီမံသင့်သည်ကို ရွေးချယ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသည့် feature များပါဝင်သော input layer |
Python code
Algorithm ID: qgis:selectbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.20.13. အကွာအဝေးအတွင်း ရွေးချယ်ခြင်း (Select within distance)
Vector layer တစ်ခုထဲတွင် ရွေးချယ်မှုတစ်ခုကို ဖန်တီးပေးပါသည်။ ထပ်ဆောင်း ရည်ညွှန်း layer တစ်ခုအတွင်းရှိ feature များမှ သတ်မှတ်ထားသည့် အများဆုံးအကွာအဝေးအတွင်း ရှိနေသည့် အခါတိုင်းတွင် feature များကို ရွေးချယ်မည်ဖြစ်ပါသည်။
See also
အကွာအဝေးအတွင်းထုတ်ယူခြင်း (Extract within distance) ၊ တည်နေရာဖြင့် ရွေးချယ်ခြင်း (Select by location)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Select features from (Feature များရွေးချယ်မည့် layer) |
|
[vector: any] |
Feature များကို ရွေးချယ်မည့် input vector layer |
By comparing to the features from |
|
[vector: any] |
နီးစပ်မှု (closeness) အတွက်အသုံးပြုမည့် feature များပါဝင်သော Vector layer ။ |
Where the features are within |
|
[number] Default: 100 |
ရည်ညွှန်း feature များ ပတ်လည်ရှိ အများဆုံး အကွာအဝေး။ ထိုအကွာအဝေးအတွင်းတွင် ရှိသော input feature များကို ရွေးချယ်မည်ဖြစ်သည်။ |
Modify current selection by |
|
[enumeration] Default: 0 |
Algorithm ၏ ရွေးချယ်ခြင်းကို မည်သို့စီမံသင့်သည်ကို ရွေးချယ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသည့် feature များပါဝင်သော input layer |
Python code
Algorithm ID: native:selectwithindistance
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။