29.1.16. Vector ဖန်တီးခြင်း (Vector creation)
29.1.16.1. အပြိုင်မျဉ်းများ (Array of offset (parallel) lines)
Feature တစ်ခုချင်းစီအတွက် များစွာသော offset (အရွေ့) version များကိုဖန်တီးခြင်းဖြင့် layer တစ်ခုရှိ line feature များ၏ မိတ္တူများကိုဖန်တီးပေးပါသည်။ သတ်မှတ်ထားသော အကွာအဝေးတစ်ခုဖြင့် version အသစ်တစ်ခုစီကို တိုး၍ offset လုပ်သွားမည်ဖြစ်သည်။
အပေါင်းလက္ခဏာရှိသည့် အကွာအဝေးသည် line များကိုဘယ်ဘက်သို့ offset လုပ်သွားမည်ဖြစ်ပြီး အနုတ်လက္ခဏာရှိသည့် အကွာအဝေးသည် line များကိုညာဘက်သို့ offset လုပ်သွားမည်ဖြစ်သည်။

Fig. 29.36 အပြာရောင်ဖြင့် မူရင်း layer ၊ အနီရောင်ဖြင့် offset layer
 ဖြင့် line feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း ပြုလုပ်နိုင်ပါသည်။
ဖြင့် line feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း ပြုလုပ်နိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: line] |
Offset များအတွက် အသုံးပြုမည့် input line vector layer |
Number of features to create (ဖန်တီးရမည့် feature များ အရေအတွက်) |
|
[number Default: 10 |
Feature တစ်ခုစီအတွက် ထုတ်ပေးရမည့် offset မိတ္တူများ၏အရေအတွက် |
Offset step distance (Offset အဆင့် အကွာအဝေး) |
|
[အရေအတွက် Default: 1.0 |
ကပ်လျက်ရှိသည့် offset မိတ္တူနှစ်ခုကြားအကွာအဝေး |
Offset lines (Offset မျဉ်းများ) |
|
[vector: line] Default: |
Offset feature များပါဝင်သည့် output line layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |

အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Segments (မျဉ်းပိုင်းများ) |
|
[number] Default: 8 |
လုံးဝန်းသော offset များဖန်တီးသောအခါ စက်ဝိုင်း၏လေးပုံတစ်ပုံကိုခန့်မှန်းရန် အသုံးပြုရမည့် မျဉ်းပိုင်းများအရေအတွက် |
Join style (အဆက် style) |
|
[enumeration] Default: 0 |
Line တစ်ခုထဲရှိ ထောင့်များကို offset လုပ်ရာတွင် အသုံးပြုသင့်သည့် အဆက် (join) အမျိုးအစားများဖြစ်သည့် round (စောင်းလုံး)၊ miter (စောင်းတိ) သို့မဟုတ် bevel (စောင်းသတ်) ကို သတ်မှတ်ပါ။ ၎င်းတို့မှာ-

Fig. 29.37 Round ၊ miter နှင့် bevel အဆက် style များ |
Miter limit (Miter ကန့်သတ်ချက်) |
|
[number] Default: 2.0 |
Miter join တစ်ခုကို offset အကွာအဝေး၏ factor တစ်ခုအဖြစ် ဖန်တီးသောအခါ အသုံးပြုရမည့် offset ဂျီဩမေတြီမှ အများဆုံးအကွာအဝေးကို သတ်မှတ်ပေးပါသည်။ (Miter အဆက် style များအတွက်သာ အသုံးပြုနိုင်သည်)။ အနည်းဆုံး- 1.0 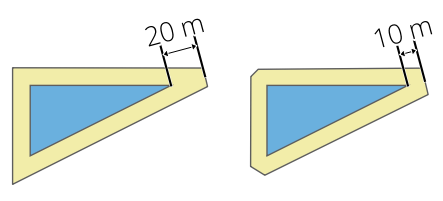
Fig. 29.38 ကန့်သတ်ချက် 2 ရှိသည့် 10m buffer တစ်ခု နှင့် ကန့်သတ်ချက် 1 ရှိသည့် 10m buffer တစ်ခု |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Offset lines (Offset မျဉ်းများ) |
|
[vector: line] |
Offset feature များပါဝင်သည့် output line layer ။ မူလ feature များကိုလည်း မိတ္တူကူးယူထားမည်ဖြစ်သည်။ |
Python code
Algorithm ID: native:arrayoffsetlines
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.2. feature များပွားခြင်း (Array of translated features)
Layer တစ်ခုအတွင်းရှိ feature တစ်ခုချင်းစီ၏ များစွာသော ရွှေ့ပြောင်းထားသည့် (translated) version များကိုဖန်တီးခြင်းဖြင့် ၎င်း feature များ၏မိတ္တူများကိုဖန်တီးပေးပါသည်။ မိတ္တူတစ်ခုချင်းစီသည် X၊ Y နှင့်/သို့မဟုတ် Z ဝင်ရိုးတွင် ကြိုတင်သတ်မှတ်ထားသော ပမာဏတစ်ခုအတိုင်း တိုး၍ ရွေ့လျားသွားမည်ဖြစ်သည်။
ဂျီဩမေတြီထဲရှိ M တန်ဖိုးများကိုလည်း translate (ရွှေ့ပြောင်း) ပြုလုပ်နိုင်ပါသည်။
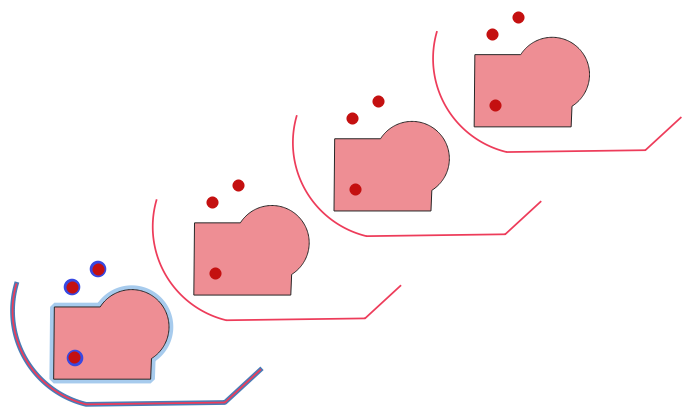
Fig. 29.39 Input layer များကို အပြာရောင်နှင့်ပြသထားသည်၊ translate လုပ်ထားပြီးသော feature များပါဝင်သည့် output layer များကိုအနီရောင်နှင့်ပြသထားသည်
ဖြင့် point ၊ line နှင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ပြုလုပ်နိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Translate လုပ်ရမည့် input vector layer |
Number of features to create (ဖန်တီးရမည့် feature များ၏အရေအတွက်) |
|
[number Default: 10 |
Feature တစ်ခုချင်းစီအတွက် ထုတ်ရမည့် မိတ္တူများ၏အရေအတွက် |
Step distance (x-axis) (Step အကွာအဝေး (x-ဝင်ရိုး)) |
|
[number Default: 0.0 |
X ဝင်ရိုးပေါ်တွင် အသုံးချရမည့် အရွေ့ |
Step distance (y-axis) (Step အကွာအဝေး (y-ဝင်ရိုး)) |
|
[number Default: 0.0 |
Y ဝင်ရိုးပေါ်တွင် အသုံးချရမည့် အရွေ့ |
Step distance (z-axis) (Step အကွာအဝေး (z-ဝင်ရိုး)) |
|
[number Default: 0.0 |
Z ဝင်ရိုးပေါ်တွင် အသုံးချရမည့် အရွေ့ |
Step distance (m values) (Step အကွာအဝေး (m တန်ဖိုးများ)) |
|
[number Default: 0.0 |
M တန်ဖိုးများတွင် အသုံးချရမည့်အရွေ့ |
Translated (ရွှေ့ပြောင်းထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Feature များ၏ translate (ရွှေ့ထားသော) လုပ်ထားသော မိတ္တူများပါရှိသည့် output vector layer ။ မူလ feature များကိုလည်း မိတ္တူကူးယူထားမည်ဖြစ်သည်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Translated (ရွှေ့ပြောင်းထားပြီးသော) |
|
[same as input] |
Feature များ၏ translate (ရွှေ့ထားသော) လုပ်ထားသော မိတ္တူများပါရှိသည့် output vector layer ။ မူလ feature များကိုလည်း မိတ္တူကူးယူထားမည်ဖြစ်သည်။ |
Python code
Algorithm ID: native:arraytranslatedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.3. Grid ဖန်တီးခြင်း (Create grid)
ပေးထားသော မြေပုံအတိုင်းအတာနယ်ပယ် (extent) အားဖုံးလွှမ်းထားသော grid ကွက်တစ်ခုပါရှိသည့် vector layer တစ်ခုကိုဖန်တီးပေးပါသည်။ Grid cell များသည် ကွဲပြားသော ပုံသဏ္ဍာန်များရှိနိုင်သည်-

Fig. 29.40 ကွဲပြားသော grid cell ပုံသဏ္ဍာန်များ
Grid ထဲရှိ အရာတစ်ခုစီ၏အရွယ်အစားကို အလျားလိုက်နှင့်ဒေါင်လိုက် အကွာအဝေးတစ်ခုကိုအသုံးပြု၍ သတ်မှတ်သည်။
Output layer ၏ CRS အားသတ်မှတ်ပေးရပါမည်။
ဤ CRS ၏ ကိုဩဒိနိတ်နှင့် ယူနစ်များအတိုင်း grid ၏ extent နှင့် အကွာအဝေးတန်ဖိုးများအား ဖော်ပြပေးရပါမည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Grid type (Grid အမျိုးအစား) |
|
[enumeration] Default: 0 |
Grid ၏ ပုံသဏ္ဍာန် ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်သည်-
|
Grid extent (Grid နယ်ပယ်အတိုင်းအတာ) |
|
[extent] |
Grid ၏ နယ်ပယ်အတိုင်းအတာ အသုံးပြုနိုင်သော နည်းလမ်းများမှာ -
|
Horizontal spacing (ရေပြင်ညီ အကွာအဝေး) |
|
[number] Default: 1.0 |
X-ဝင်ရိုးပေါ်ရှိ grid cell တစ်ခု၏အရွယ်အစား |
Vertical spacing (ဒေါင်လိုက် အကွာအဝေး) |
|
[number] Default: 1.0 |
Y-ဝင်ရိုးပေါ်ရှိ grid cell တစ်ခု၏အရွယ်အစား |
Horizontal overlay (ရေပြင်ညီ ထပ်နေမှု) |
|
[number] Default: 0.0 |
X-ဝင်ရိုးပေါ်ရှိ ကပ်လျက် grid cell နှစ်ခုကြား overlay အကွာအဝေး |
Vertical overlay (ဒေါင်လိုက် ထပ်နေမှု) |
|
[number] Default: 0.0 |
Y-ဝင်ရိုးပေါ်ရှိ ကပ်လျက် grid cell နှစ်ခုကြား overlay အကွာအဝေး |
Grid CRS |
|
[crs] Default: Project CRS |
Grid အတွက် အသုံးပြုမည့် Coordinate reference system (ရည်ညွှန်းကိုဩဒိနိတ်စနစ်) |
Grid |
|
[vector: any] Default: |
ရရှိလာသော vector grid layer ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Grid |
|
[vector: any] |
ရရှိလာသော vector grid layer ။ Output ဂျီဩမေတြီအမျိုးအစား (point ၊ line သို့မဟုတ် polygon) သည် Grid type ပေါ်တွင်မူတည်ပါသည်။ |
Python code
Algorithm ID: native:creategrid
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.4. ဇယားကို point layer အဖြစ်ဖန်တီးခြင်း (Create points layer from table)
ကိုဩဒိနိတ် field များပါဝင်သည့် column များရှိသော ဇယားတစ်ခုမှ point layer ကို ဖန်တီးပေးပါသည်။
X ကိုဩဒိနိတ် နှင့် Y ကိုဩဒိနိတ် များအပြင် Z နှင့် M field များကိုလည်းသတ်မှတ်ပေးနိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer သို့မဟုတ် ဇယားတစ်ခု |
X field |
|
[tablefield: any] |
X ကိုဩဒိနိတ်ပါဝင်သော Field |
Y field |
|
[tablefield: any] |
Y ကိုဩဒိနိတ်ပါဝင်သော Field |
Z field Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] |
Z ကိုဩဒိနိတ်ပါဝင်သော Field |
M field Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] |
M တန်ဖိုးပါဝင်သော Field |
Target CRS (ဦးတည်ရာ CRS) |
|
[crs] Default: |
Layer အတွက် အသုံးပြုမည့် Coordinate reference system ။ ပေးထားသော ကိုဩဒိနိတ်များကို လိုက်လျောညီထွေဖြစ်သည်ဟုယူဆပါသည်။ |
Points from table (ဇယားမှ point များ) |
|
[vector: point] Default: |
ရရှိလာသည့် point layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Points from table (ဇယားမှ point များ) |
|
[vector: point] |
ရရှိလာသော point layer |
Python code
Algorithm ID: native:createpointslayerfromtable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.5. မျဉ်းတစ်ခုဖြတ်သွားသည့် pixel များ၏အလယ်မှတ်များကို point များအဖြစ်ဖန်တီးခြင်း (Generate points (pixel centroids) along line)
Input raster တစ်ခုနှင့် line layer တစ်ခုမှ point vector layer တစ်ခုကို ထုတ်ပေးပါသည်။
Point များသည် line layer ကိုထိဖြတ်သွားသည့် pixel centroid (အလယ်ဗဟို) များကို ကိုယ်စားပြုပါသည်။
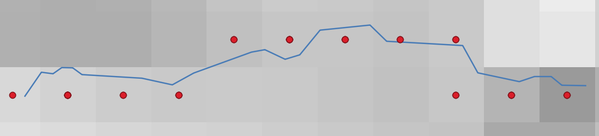
Fig. 29.41 Pixel centroid များ၏ point များ
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Raster layer |
|
[raster] |
ထည့်သွင်းအသုံးပြုသော raster layer |
Vector layer |
|
[vector: line] |
ထည့်သွင်းအသုံးပြုသော line vector layer |
Points along line (မျဉ်းတလျှောက် point များ) |
|
[vector: point] Default: |
Pixel centroid များပါဝင်သော ရလာဒ် point layer ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Points along line (မျဉ်းတလျှောက် point များ) |
|
[vector: point] |
Pixel centroid များပါဝင်သော ရလာဒ် point layer |
Python code
Algorithm ID: qgis:generatepointspixelcentroidsalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.6. Polygonတစ်ခုအတွင်း ကျသည့် pixel များ၏ အလယ်မှတ်များကို point များအဖြစ်ဖန်တီးခြင်း (Generate points (pixel centroids) inside polygon)
Input raster တစ်ခုနှင့် polygon layer တစ်ခုမှ point vector layer တစ်ခုကို ထုတ်ပေးပါသည်။
Point များသည် polygon layer ကိုထိဖြတ်သွားသည့် pixel centroid (အလယ်ဗဟို) များကို ကိုယ်စားပြုပါသည်။
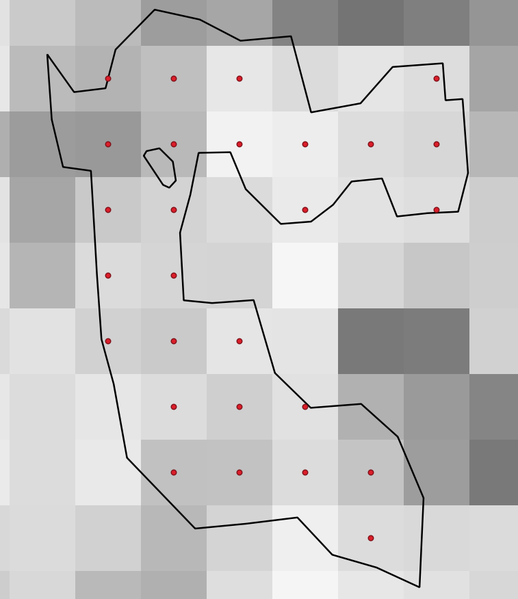
Fig. 29.42 Pixel centroid များ၏ point များ
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Raster layer* |
|
[raster] |
ထည့်သွင်းအသုံးပြုသော raster layer |
Vector layer |
|
[vector: polygon] |
ထည့်သွင်းအသုံးပြုသော polygon vector layer |
Points inside polygons (Polygon အတွင်းရှိ point များ) |
|
[vector: point] Default: |
Pixel centroid များပါဝင်သော ရလာဒ် point layer ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Points inside polygons (Polygon အတွင်းရှိ point များ) |
|
[vector: point] |
Pixel centroid များပါဝင်သော ရလာဒ် point layer |
Python code
Algorithm ID: native:generatepointspixelcentroidsinsidepolygons
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.7. တည်နေရာအချက်အလက်များပါဝင်သည့် ဓာတ်ပုံများကို ထည့်သွင်းခြင်း (Import geotagged photos)
ရင်းမြစ် folder တစ်ခုရှိ JPEG သို့မဟုတ် HEIC/HEIF ဓာတ်ပုံများမှ geotag ပြုလုပ်ထားသော တည်နေရာများနှင့် သက်ဆိုင်သော point layer တစ်ခုကို ဖန်တီးပေးပါသည်။
Point layer တွင် geotag များကိုဖတ်နိုင်သည့် input file တစ်ခုလျှင် PointZ feature တစ်ခုပါဝင်လိမ့်မည်။ Geotag များမှ မည်သည့် altitude (အမြင့်) အချက်အလက်ကိုမဆို point ၏ Z တန်ဖိုးကိုသတ်မှတ်ရန် အသုံးပြုမည်ဖြစ်သည်။
လောင်ဂျီကျုနှင့် လတ္တီကျု များအပြင် ဓာတ်ပုံထဲတွင် altitude ၊ လားရာ နှင့် timestamp (အချိန်သတင်းအချက်အလက်) တို့ပါဝင်ပါက ၎င်းတို့ကို point ထဲသို့ attribute များအဖြစ် ပေါင်းထည့်မည်ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input folder (ထည့်သွင်းအသုံးပြုသော folder) |
|
[folder] |
Geotag ပြုလုပ်ထားသော ဓာတ်ပုံများပါဝင်သည့် ရင်းမြစ် folder လမ်းကြောင်း |
Scan recursively (အဆင့်ဆင့် ထပ်ခါတလဲလဲ scan လုပ်ခြင်း) |
|
[boolean] Default: False |
အမှန်ခြစ်ပေးထားပါက folder နှင့် ၎င်း၏ subfolder များကို scan ဖတ်ပေးမည်ဖြစ်သည်။ |
Photos (ဓာတ်ပုံများ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: point] Default: |
Geotag ပြုလုပ်ထားသော ဓာတ်ပုံများအတွက် point vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Invalid photos table (ဆီလျော်မှုမရှိသော ဓာတ်ပုံများဇယား) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[table] Default: |
ဖတ်၍မရသော သို့မဟုတ် geotag မပြုလုပ်ထားသော ဓာတ်ပုံများ ပါဝင်သည့် ဇယားကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Photos (ဓာတ်ပုံများ) |
|
[vector: point] |
Geotag ပြုလုပ်ထားသော ဓာတ်ပုံများပါဝင်သည့် point vector layer ။ Layer ၏ form တွင် လမ်းကြောင်းများနှင့် ဓာတ်ပုံ ကြိုတင်ကြည့်ရှုမှု (preview) setting များဖြင့် အလိုအလျောက် ထည့်သွင်းသွားမည်ဖြစ်သည်။ |
Invalid photos table (ဆီလျော်မှုမရှိသော ဓာတ်ပုံများဇယား) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[table] |
ဖတ်၍မရသော သို့မဟုတ် geotag မပြုလုပ်ထားသော ဓာတ်ပုံများ ပါဝင်သည့် ဇယားကိုလည်း ဖန်တီးနိုင်ပါသည်။ |
Python code
Algorithm ID: native:importphotos
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.8. Point များမှလိုင်းအဖြစ်သို့ (Points to path)
Expression တစ်ခု သို့မဟုတ် input point layer ထဲရှိ field တစ်ခုဖြင့် သတ်မှတ်ထားသော order (အစဉ်) အတိုင်း point များကို ဆက်ပေးခြင်းဖြင့် point layer တစ်ခုကို line layer တစ်ခုသို့ ပြောင်းလဲပေးပါသည်။
Line feature များကို ကွဲပြားခြားနားစေရန်အတွက် point များကို field တစ်ခု သို့မဟုတ် expression တစ်ခုဖြင့် အုပ်စုဖွဲ့နိုင်ပါသည်။
Line vector layer အပြင် စာသား file တစ်ခုသည် ရလာဒ် line ကို စမှတ်တစ်ခုနှင့် bearing (ရပ်ညွှန်း)/ဦးတည်ချက်များ (azimuth နှင့်နှိုင်းရဖြစ်သော) နှင့်အကွာအဝေးများ၏ အစီအစဉ် (sequence) တစ်ခုအဖြစ် ဖော်ပြသော output တစ်ခုဖြစ်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input point layer (ထည့်သွင်းအသုံးပြုသော point layer) |
|
[vector: point] |
ထည့်သွင်းအသုံးပြုသော point vector layer |
Create closed paths (လမ်းကြောင်း အပိတ်များဖန်တီးခြင်း) |
|
[boolean] Default: False |
အမှန်ခြစ်ပေးထားပါက line ၏ ပထမဆုံးနှင့် နောက်ဆုံး point များသည် ချိတ်ဆက်သွားမည်ဖြစ်ပြီး ထွက်လာသော လမ်းကြောင်းကို ပိတ်ပေးမည်ဖြစ်သည်။ |
Order expression (အစီအစဉ် expression) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[expression] |
လမ်းကြောင်းထဲရှိ point များကို ချိတ်ဆက်ရန် အစီအစဉ် (order) အတွက် Field သို့မဟုတ် expression ။ အကယ်၍ မသတ်မှတ်ထားပါက feature ID ( |
Sort text containing numbers naturally (ဂဏန်းများပါဝင်သည့် စာသားများအား သဘာဝကိန်းစဉ်အတိုင်း စဉ်ပေးခြင်း) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[boolean] Default: False |
အမှန်ခြစ်ပေးထားပါက ထည့်သွင်းထားသော expression အတိုင်း feature များကို သဘာဝအတိုင်း စဉ်ပေးသွားမည်ဖြစ်သည် (ဆိုလိုသည်မှာ- ‘a9’ < ‘a10’)။ |
Path group expression (လမ်းကြောင်းအုပ်စု expression) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[expression] |
Field သို့မဟုတ် expression ထဲရှိ တန်ဖိုးတူညီသော point feature များကို တူညီသော line ထဲတွင် အုပ်စုဖွဲ့ပေးပါလိမ့်မည်။ မသတ်မှတ်ထားပါက input point များအားလုံးဖြင့် လမ်းကြောင်း တစ်ခုတည်းကို ဖန်တီးမည်ဖြစ်သည်။ |
Paths (လမ်းကြောင်းများ) |
|
[vector: line] Default: |
လမ်းကြောင်းအတွက် line vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Directory for text output (စာသား output အတွက် ဖိုင်လမ်းကြောင်း) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[folder] Default: |
Point များနှင့် လမ်းကြောင်းများကိုဖော်ပြသော file များပါဝင်သည့် ဖိုင်လမ်းကြောင်းကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Paths (လမ်းကြောင်းများ) |
|
[vector: line] |
လမ်းကြောင်းအတွက် line vector layer |
Directory for text output (စာသား output အတွက် ဖိုင်လမ်းကြောင်း) |
|
[folder] |
Point များနှင့် လမ်းကြောင်းများကိုဖော်ပြသော file များပါဝင်သည့် ဖိုင်လမ်းကြောင်း |
Python code
Algorithm ID: native:pointstopath
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.9. မျဉ်းတစ်လျှောက်တွင် ကျပန်း point များဖန်တီးခြင်း (Random points along line)
အခြား layer ၏ line များပေါ်တွင် နေရာချထားသော point များဖြင့် point layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
Input layer ထဲရှိ line တစ်ကြောင်းချင်းစီအတွက် သတ်မှတ်ပေးထားသော point အရေအတွက်ကို ရလာဒ် layer ထဲတွင် ပေါင်းထည့်သွားမည်ဖြစ်သည်။ Point တစ်ခုကို ပေါင်းထည့်ရန်အတွက် လုပ်ငန်းစဉ်များမှာ-
Input layer မှ line feature တစ်ခုကို ကျပန်းရွေးချယ်ပါ
အကယ်၍ feature သည် multi-part (အစိတ်အပိုင်းများစွာပါဝင်သော) ဖြစ်ပါက ၎င်း၏အစိတ်အပိုင်းတစ်ခုအား ကျပန်းရွေးချယ်ပါ
ထို line ၏မျဉ်းပိုင်းတစ်ခုအား ကျပန်းရွေးချယ်ပါ
၎င်းမျဉ်းပိုင်းပေါ်တွင် တည်နေရာတစ်ခုအား ကျပန်းရွေးချယ်ပါ
ဆိုလိုသည်မှာ line များ၏ ကွေးနေသောအပိုင်းများ (တိုသောမျဉ်းပိုင်းများဖြင့်) သည် ဖြောင့်တန်းသောအပိုင်းများ (ရှည်သောမျဉ်းပိုင်းများဖြင့်) ထက် point ပိုမိုရရှိလိမ့်မည်ဖြစ်ပြီး အောက်ပါပုံတွင် ပြထားသည့်အတိုင်း Random points along lines algorithm ၏ output ကို Random points on lines algorithm (၎င်းသည် ပျမ်းမျှအားဖြင့် line များတစ်လျှောက် အညီအမျှ ပျံ့နှံ့နေသော point များကို ဖန်တီးပေးပါသည်) ၏ output ဖြင့် နှိုင်းယှဉ်နိုင်မည်ဖြစ်သည်။
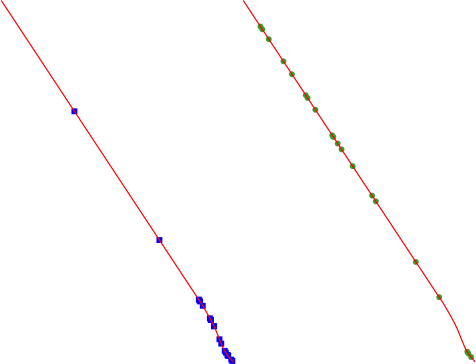
Fig. 29.43 Algorithm output ဥပမာ၊ ဘယ်- Random points along line ၊ ညာ- Random points on lines
Point များတစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်နေခြင်းမရှိစေရန်အတွက် အနည်းဆုံးအကွာအဝေးကို သတ်မှတ်ထားနိုင်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input point layer (ထည့်သွင်းအသုံးပြုသော point layer) |
|
[vector: line] |
ထည့်သွင်းအသုံးပြုသော line vector layer |
Number of points (Point များအရေအတွက်) |
|
[number] Default: 1 |
ဖန်တီးရမည့် point များအရေအတွက် |
Minimum distance between points (Point များကြား အနည်းဆုံးအကွာအဝေး) |
|
[number] Default: 0.0 |
Point များကြား အနည်းဆုံးအကွာအဝေး |
Random points (ကျပန်း point များ) |
|
[vector: point] Default: |
ရလာဒ် ကျပန်း point များ ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Random points (ကျပန်း point များ) |
|
[vector: point] |
Output ကျပန်း point များ layer |
Python code
Algorithm ID: qgis:qgisrandompointsalongline
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.10. မြေပုံနယ်ပယ်အတွင်း ကျပန်း point များဖန်တီးခြင်း (Random points in extent)
သတ်မှတ်ထားသော extent တစ်ခုအတွင်းတွင် ပေးထားသော ကျပန်း point များအရေအတွက်ဖြင့် point layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
Point များတစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်စွာ မရှိစေရန် အကွာအဝေး factor တစ်ခုကိုသတ်မှတ်နိုင်ပါသည်။ အကယ်၍ point များကြား အနည်းဆုံးအကွာအဝေးသည် point အသစ်များဖန်တီးရန်မဖြစ်နိုင်ပါက အကွာအဝေးအား လျှော့ချပေးနိုင်သလို အများဆုံးကြိုးစားမှုအကြိမ်ရေကိုလဲတိုးမြှင့်ပေးနိုင်ပါသည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input extent (ထည့်သွင်းအသုံးပြုသော extent) |
|
[extent] |
ကျပန်း point များအတွက် မြေပုံ extent အသုံးပြုနိုင်သော နည်းလမ်းများမှာ -
|
Number of points (Point များအရေအတွက်) |
|
[number] Default: 1 |
ဖန်တီးရမည့် point များ အရေအတွက် |
Minimum distance between points (Point များကြား အနည်းဆုံးအကွာအဝေး) |
|
[number] Default: 0.0 |
Point များကြား အနည်းဆုံးအကွာအဝေး |
Target CRS |
|
[crs] Default: Project CRS |
ကျပန်း point များ layer ၏ CRS |
Random points (ကျပန်း point များ) |
|
[vector: point] Default: |
Output ကျပန်း point များ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Maximum number of search attempts given the minimum distance (အနည်းဆုံးအကွာအဝေးတွင် အများဆုံး ရှာဖွေရန်ကြိုးစားမှုအကြိမ်ရေ) |
|
[number] Default: 200 |
Point များအား နေရာချရန် အများဆုံး ကြိုးစားမှုအကြိမ်ရေ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Random points (ကျပန်း point များ) |
|
[vector: point] |
Output ကျပန်း point layer |
Python code
Algorithm ID: native:randompointsinextent
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.11. Layer နယ်နိမိတ်အတွင်း ကျပန်း point များဖန်တီးခြင်း (Random points in layer bounds)
ပေးထားသော layer တစ်ခု၏နယ်နိမိတ်အတွင်း သတ်မှတ်ပေးထားသော ကျပန်း point များအရေအတွက်ဖြင့် point layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
Point များတစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်စွာ ရှိမနေစေရန်အတွက် အနည်းဆုံးအကွာအဝေးကို သတ်မှတ်နိုင်ပါသည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: polygon] |
ဧရိယာအားသတ်မှတ်ပေးသည့် ထည့်သွင်းအသုံးပြုသော polygon layer |
Number of points (Point များအရေအတွက်) |
|
[number] Default: 1 |
ဖန်တီးရမည့် point များအရေအတွက် |
Minimum distance between points (Point များကြား အများဆုံးအကွာအဝေး) |
|
[number] Default: 0.0 |
Point များကြား အနည်းဆုံးအကွာအဝေး |
Random points (ကျပန်း point များ) |
|
[vector: point] Default: |
Output ကျပန်း point များ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Random points (ကျပန်း point များ) |
|
[vector: point] |
Output ကျပန်း point များ layer |
Python code
Algorithm ID: qgis:randompointsinlayerbounds
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.12. Polygon များအတွင်း ကျပန်း point များဖန်တီးခြင်း (Random points in polygons)
အခြား layer တစ်ခု၏ polygon များအတွင်းတွင် နေရာချထားသော point များဖြင့် point layer တစ်ခုကို ဖန်တီးပေးပါသည်။
Input layer ထဲရှိ feature ဂျီဩမေတြီ (polygon / multi-polygon) တစ်ခုချင်းစီအတွက် ရလာဒ် layer ထဲသို့ သတ်မှတ်ပေးထားသော point အရေအတွက်အား ပေါင်းထည့်ပေးမည်ဖြစ်သည်။
Output point layer ထဲတွင် point များ တစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်စွာ မရှိနေစေရန် feature တစ်ခုချင်းစီအတွက်နှင့် အားလုံးအတွက် အနည်းဆုံး အကွာအဝေးကိုသတ်မှတ်နိုင်ပါသည်။ အကယ်၍ အနည်းဆုံး အကွာအဝေးတစ်ခုကို သတ်မှတ်ထားပါက feature တစ်ခုချင်းစီအတွက် သတ်မှတ်ထားသော point များအရေအတွက်ကို ဖန်တီးနိုင်မည်မဟုတ်ပါ။ ထုတ်ယူထားသော point များနှင့် လွဲချော်သွားသော point များ၏ စုစုပေါင်းအရေအတွက်အား Algorithm ၏ output အတိုင်း ရရှိမည်ဖြစ်သည်။
အောက်ဖော်ပြပါပုံသည် feature တစ်ခုချင်းစီအတွက်အပြင် အားလုံးအတွက် အနည်းဆုံးအကွာအဝေးနှင့် သုည/သုညမဟုတ်သော အနည်းဆုံးအကွာအဝေးများ၏ အကျိုးသက်ရောက်မှုကိုပြသသည် (တူညီသော အစမှတ်ဖြင့် ဖန်တီးထားသောကြောင့် ထုတ်ပေးသောပထမဆုံးအမှတ်သည် အတူတူပင်ဖြစ်လိမ့်မည်)
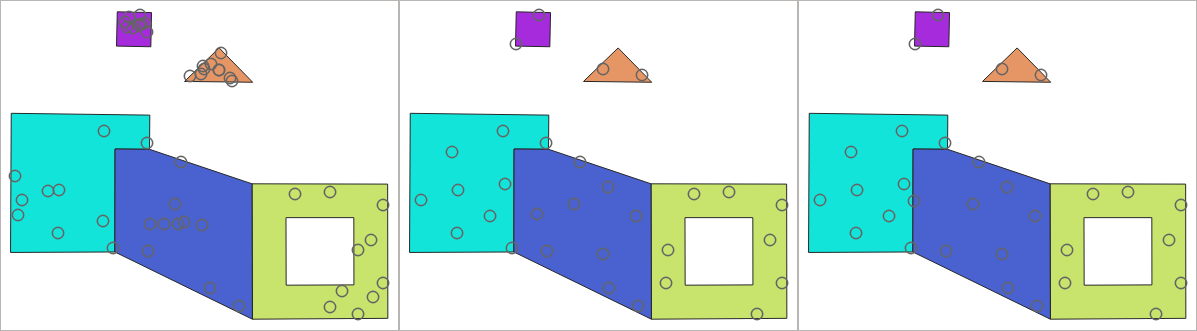
Fig. 29.44 Polygon feature တစ်ခုလျှင် point ဆယ်ခု၊ ဘယ်ဘက်- min. distances = 0 ၊ အလယ်- min.distances = 1 ၊ ညာဘက်- min. distance = 1 ၊ global min. distance = 0
Point တစ်ခုချင်းစီအတွက် ကြိုးပမ်းမှု (try) အရေအတွက်အား သတ်မှတ်ထားနိုင်သည်။ ၎င်းသည် သုံညမဟုတ်သော အနည်းဆုံးအကွာအဝေးအတွက်သာ ဆီလျော်မှုရှိမည်ဖြစ်ပါသည်။
ကျပန်း point များ ထုတ်ပေးသည့်အရာအတွက် စမှတ် (seed) တစ်ခုကိုသတ်မှတ်ပေးထားခြင်းဖြင့် algorithm ကိုအသုံးပြုတိုင်း ထပ်တူကျသော ကျပန်း အရေအတွက် အစီအစဉ်များ ရရှိစေမည်ဖြစ်သည်။
Point တစ်ခုအား ဖန်တီးခဲ့သော polygon feature ၏ attribute များကို ထည့်သွင်းနိုင်သည် (Include polygon attributes) ။
Feature များအားလုံးအတွက် တူညီသော point သိပ်သည်းမှု ရှိစေလိုပါက polygon feature ဂျီဩမေတြီ၏ ဧရိယာကိုအသုံးပြု၍ point များ၏ အရေအတွက်ကို data ဖြင့် သတ်မှတ်နိုင် (data-define) ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input polygon layer (ထည့်သွင်းအသုံးပြုသော polygon layer) |
|
[vector: line] |
ထည့်သွင်းအသုံးပြုသော polygon vector layer |
Number of points for each feature (Feature တစ်ခုစီအတွက် point များအရေအတွက်) |
|
[number Default: 1 |
ဖန်တီးရမည့် point များအရေအတွက် |
Minimum distance between points (Point များကြား အနည်းဆုံးအကွာအဝေး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number Default: 0.0 |
Polygon feature တစ်ခုအတွင်းရှိ point များကြား အနည်းဆုံးအကွာအဝေး |
Random points in polygons (Polygon များအတွင်းရှိ ကျပန်း point များ) |
|
[vector: point] Default: |
Output ကျပန်း point များ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Global minimum distance between points (Point များကြား Global ဖြစ်သော အနည်းဆုံးအကွာအဝေး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number Default: 0.0 |
အားလုံးအတွက် သတ်မှတ်ထားသော point များကြား အနည်းဆုံး အကွာအဝေး။ သက်ရောက်မှုရှိစေရန် ထို parameter သည် feature တစ်ခုချင်းစီအတွက် point များကြား အနည်းဆုံးအကွာအဝေး ထက် ပို၍နည်းသင့်သည်။ |
Maximum number of search attempts (for Min. dist. > 0) (အများဆုံး ရှာဖွေရန်ကြိုးစားမှုအကြိမ်ရေ (for Min. dist. > 0)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number Default: 10 |
Point တစ်ခုချင်းစီအတွက် အများဆုံး ကြိုးစားမှု (try) အကြိမ်ရေ။ Point များကြား အနည်းဆုံးအကွာအဝေးကိုသတ်မှတ်ထားမှသာ (0 ထက်ကြီးသောတန်ဖိုးပေးထားမှသာ) ဆီလျော်မှုရှိမည်ဖြစ်သည်။ |
Random seed (ကျပန်း အစမှတ်) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number] Default: Not set |
ကျပန်း ဂဏန်းများထုတ်ပေးရာတွင် အသုံးပြုရမည့်အစမှတ်။ |
Include polygon attributes (Polygon attribute များ ပါရှိစေခြင်း) |
|
[boolean] Default: True |
သတ်မှတ်ထားလျှင် point တစ်ခုသည် ၎င်းအားနေရာချထားသည့် line ပေါ်မှ attribute များကို ရရှိလိမ့်မည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Random points in polygons (Polygon များအတွင်းရှိ ကျပန်း point များ) |
|
[vector: point] |
ကျပန်း point များပါဝင်သော ရလာဒ် layer |
Number of features with empty or no geometry (ဗလာဖြစ်နေသော သို့မဟုတ် ဂျီဩမေတြီမပါရှိသော feature များအရေအတွက်) |
|
[number] |
|
Total number of points generated (ဖန်တီးလိုက်သော point များအရေအတွက်စုစုပေါင်း) |
|
[number] |
|
Number of missed points (လွဲချော်သွားသည့် point များအရေအတွက်) |
|
[number] |
အနည်းဆုံးအကွာအဝေး ကန့်သတ်ချက်များကြောင့် ဖန်တီး၍မရနိုင်သော point များအရေအတွက် |
Number of features with missed points (လွဲချော်သွားသည့် point များပါဝင်သော feature များအရေအတွက်) |
|
[number] |
ဗလာဖြစ်နေသော သို့မဟုတ် ဂျီဩမေတြီမပါရှိသည့် feature များမပါရှိပါ။ |
Python code
Algorithm ID: native:randompointsinpolygons
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.13. Polygon များအတွင်း ကျပန်း point များဖန်တီးခြင်း (Random points inside polygons)
Input polygon layer ၏ polygon တစ်ခုစီအတွင်းတွင် သတ်မှတ်ထားသော ကျပန်း point များအရေအတွက်ဖြင့် point layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
ရရှိနိုင်သော sampling နည်းလမ်းနှစ်ခုမှာ -
Points count - Feature တစ်ခုစီအတွက် point များအရေအတွက်
Points density - Feature တစ်ခုစီအတွက် point များ သိပ်သည်းဆ
အမှတ်များတစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်စွာ ရှိမနေစေရန်အတွက် အနည်းဆုံးအကွာအဝေးကိုသတ်မှတ်နိုင်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: polygon] |
ထည့်သွင်းအသုံးပြုသော polygon vector layer |
Sampling strategy (Sampling နည်းလမ်း) |
|
[enumeration] Default: 0 |
အသုံးပြုရမည့် Sampling နည်းလမ်း။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
Point count or density (Point အရေအတွက် သို့မဟုတ် သိပ်သည်းဆ) |
|
[number Default: 1.0 |
Point များ၏အရေအတွက် သို့မဟုတ် သိပ်သည်းဆ၊ ရွေးချယ်သည့် Sampling strategy အပေါ်တွင်မူတည်သည်။ |
Minimum distance between points (Point များကြားအနည်းဆုံးအကွာအဝေး) |
|
[number] Default: 0.0 |
Point များကြားအနည်းဆုံးအကွာအဝေး |
Random points (ကျပန်း point များ) |
|
[vector: point] Default: |
Output ကျပန်း point များ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Random points (ကျပန်း point များ) |
|
[vector: point] |
Output ကျပန်း point များ layer |
Python code
Algorithm ID: qgis:randompointsinsidepolygons
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.14. Line များပေါ်တွင် ကျပန်း point များဖန်တီးခြင်း (Random points on lines)
အခြား layer တစ်ခု၏ line များအပေါ်တွင် နေရာချထားသော point များဖြင့် point layer တစ်ခုကိုဖန်တီးပေးပါသည်။
Input layer ထဲရှိ feature ဂျီဩမေတြီ (line / multi-line) တစ်ခုစီအတွက် သတ်မှတ်ပေးထားသော point များအရေအတွက်အား ရလာဒ် layer ထဲသို့ ပေါင်းထည့်ပေးမည်ဖြစ်သည်။
Output point layer ထဲတွင် point များ တစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်စွာတည်ရှိနေခြင်း မဖြစ်စေရန် feature တစ်ခုချင်းစီအတွက်နှင့် အားလုံးအတွက် အနည်းဆုံး အကွာအဝေးကိုသတ်မှတ်နိုင်သည်။ အကယ်၍ အနည်းဆုံး အကွာအဝေးတစ်ခုကို သတ်မှတ်ထားပါက feature တစ်ခုစီအတွက် သတ်မှတ်ထားသော point အရေအတွက်ကို ဖန်တီးနိုင်မည်မဟုတ်ပါ။ ထုတ်ယူထားသော point များနှင့် လွဲချော်သွားသော point များ၏ စုစုပေါင်းအရေအတွက်အား Algorithm ၏ output အတိုင်း ရရှိမည်ဖြစ်သည်။
အောက်ဖော်ပြပါပုံသည် feature တစ်ခုချင်းစီအတွက်အပြင် အားလုံးအတွက် အနည်းဆုံးအကွာအဝေးနှင့် သုည/သုညမဟုတ်သော အနည်းဆုံးအကွာအဝေးများ၏ အကျိုးသက်ရောက်မှုကိုပြသသည် (တူညီသော အစမှတ်ဖြင့် ဖန်တီးထားသောကြောင့် ထုတ်ပေးသောပထမဆုံးအမှတ်သည် အတူတူပင်ဖြစ်လိမ့်မည်)
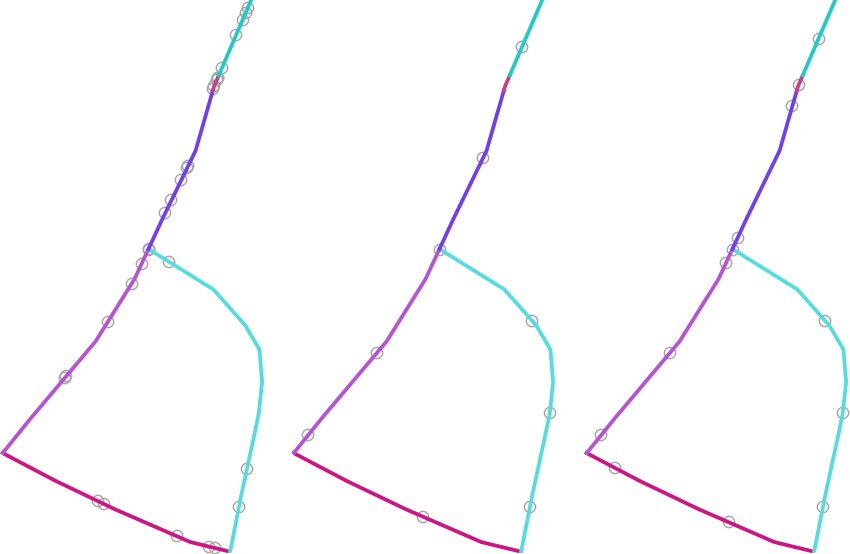
Fig. 29.45 Line feature တစ်ခုလျှင် point ၅ ခု ၊ ဘယ်ဘက်- min. distances = 0 ၊ အလယ်- min.distances != 0 ၊ ညာဘက်- min. distance != 0 ၊ global min. distance = 0
Point တစ်ခုချင်းစီအတွက် ကြိုးပမ်းမှု (try) အရေအတွက်အား သတ်မှတ်ထားနိုင်သည်။ ၎င်းသည် သုံညမဟုတ်သော အနည်းဆုံးအကွာအဝေးအတွက်သာ ဆီလျော်မှုရှိမည်ဖြစ်ပါသည်။
ကျပန်း point များ ထုတ်ပေးသည့်အရာအတွက် စမှတ် (seed) တစ်ခုကိုသတ်မှတ်ပေးထားခြင်းဖြင့် algorithm ကိုအသုံးပြုတိုင်း ထပ်တူကျသော ကျပန်း အရေအတွက် အစီအစဉ်များ ရရှိစေမည်ဖြစ်သည်။
Point တစ်ခုအား ဖန်တီးခဲ့သော line feature ၏ attribute များကို ထည့်သွင်းနိုင်သည် (Include line attributes) ။
Line feature များအားလုံးအတွက် တူညီသော point သိပ်သည်းမှု ရှိစေလိုပါက line feature ဂျီဩမေတြီ၏ အလျားကိုအသုံးပြု၍ point များ၏ အရေအတွက်ကို data ဖြင့် သတ်မှတ်နိုင် (data-define) ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input line layer (ထည့်သွင်းအသုံးပြုသော line layer) |
|
[vector: line] |
ထည့်သွင်းအသုံးပြုသော line vector layer |
Number of points for each feature (Feature တစ်ခုစီအတွက် point များအရေအတွက်) |
|
[number Default: 1 |
ဖန်တီးရမည့် point များအရေအတွက် |
Minimum distance between points (per feature) (Point များကြား အနည်းဆုံးအကွာအဝေး (feature တစ်ခုချင်းစီအတွက်)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number Default: 0.0 |
Line feature တစ်ခုအတွင်းရှိ point များကြားအနည်းဆုံးအကွာအဝေး |
Random points on lines (Line များပေါ်ရှိ ကျပန်း point များ) |
|
[vector: point] Default: |
Output ကျပန်း point များ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Global minimum distance between points (Point များကြား Global ဖြစ်သော အနည်းဆုံးအကွာအဝေး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number Default: 0.0 |
အားလုံးအတွက် သတ်မှတ်ထားသော point များကြား အနည်းဆုံး အကွာအဝေး။ သက်ရောက်မှုရှိစေရန် ထို parameter သည် feature တစ်ခုချင်းစီအတွက် point များကြား အနည်းဆုံးအကွာအဝေး ထက် ပို၍နည်းသင့်သည်။ |
Maximum number of search attempts (for Min. dist. > 0) (အများဆုံး ရှာဖွေရန်ကြိုးစားမှုအကြိမ်ရေ (for Min. dist. > 0)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number Default: 10 |
Point တစ်ခုချင်းစီအတွက် အများဆုံး ကြိုးစားမှု (try) အကြိမ်ရေ။ Point များကြား အနည်းဆုံးအကွာအဝေးကိုသတ်မှတ်ထားမှသာ (0 ထက်ကြီးသောတန်ဖိုးပေးထားမှသာ) ဆီလျော်မှုရှိမည်ဖြစ်သည်။ |
Random seed (ကျပန်း အစမှတ်) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number] Default: Not set |
ကျပန်း ဂဏန်းများထုတ်ပေးရာတွင် အသုံးပြုရမည့်အစမှတ်။ |
Include line attributes (Line attribute များ ပါရှိစေခြင်း) |
|
[boolean] Default: True |
သတ်မှတ်ထားလျှင် point တစ်ခုသည် ၎င်းအားနေရာချထားသည့် line ပေါ်မှ attribute များကို ရရှိလိမ့်မည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Random points on lines (Line များပေါ်ရှိ ကျပန်း point များ) |
|
[vector: point] |
ကျပန်း point များပါဝင်သော ရလာဒ် layer |
Number of features with empty or no geometry (ဗလာဖြစ်နေသော သို့မဟုတ် ဂျီဩမေတြီမပါရှိသော feature များအရေအတွက်) |
|
[number] |
|
Number of features with missed points (လွဲချော်သွားသည့် point များပါဝင်သော feature များအရေအတွက်) |
|
[number] |
ဗလာဖြစ်နေသော သို့မဟုတ် ဂျီဩမေတြီမပါရှိသည့် feature များမပါရှိပါ။ |
Total number of points generated (ဖန်တီးလိုက်သော point များအရေအတွက်စုစုပေါင်း) |
|
[number] |
|
Number of missed points (လွဲချော်သွားသည့် point များအရေအတွက်) |
|
[number] |
အနည်းဆုံးအကွာအဝေး ကန့်သတ်ချက်များကြောင့် ဖန်တီး၍မရနိုင်သော point များအရေအတွက် |
Python code
Algorithm ID: native:randompointsonlines
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.15. Raster pixel များမှ point များသို့ ပြောင်းခြင်း (Raster pixels to points)
Raster layer တစ်ခုထဲမှ pixel တစ်ခုစီနှင့် သက်ဆိုင်သော point များပါဝင်သည့် vector layer တစ်ခုကိုဖန်တီးပေးပါသည်။
၎င်းသည် raster layer ထဲရှိ pixel တစ်ခုစီ၏ အလယ်ဗဟိုအတွက် point feature များဖန်တီးခြင်းဖြင့် raster layer တစ်ခုကို vector layer တစ်ခုသို့ပြောင်းလဲပေးခြင်းဖြစ်သည်။ Nodata pixel များကို output ထဲတွင် ထည့်သွင်းမည်မဟုတ်ပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Raster layer |
|
[raster] |
ထည့်သွင်းအသုံးပြုသော raster layer |
Band number (လှိုင်းအလွှာ နံပါတ်) |
|
[raster band] |
Data ထုတ်ယူရမည့် raster band |
Field name (Field အမည်) |
|
[string] Default: ‘VALUE’ |
Raster band တန်ဖိုးအား သိမ်းဆည်းမည့် field ၏အမည် |
Vector points |
|
[vector: point] Default: |
Pixel ၏ အလယ်ဗဟိုမှတ်များပါဝင်သည့် ရလာဒ် point layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Vector points |
|
[vector: point] |
Pixel ၏ အလယ်ဗဟိုမှတ်များ ပါဝင်သည့် ရလာဒ် point layer |
Python code
Algorithm ID: native:pixelstopoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.16. Raster pixel များမှ polgyon များသို့ ပြောင်းခြင်း(Raster pixels to polygons)
Raster layer တစ်ခုထဲရှိ pixel တစ်ခုစီနှင့် သက်ဆိုင်သော polygon များပါဝင်သည့် vector layer တစ်ခုကိုဖန်တီးပေးပါသည်။
၎င်းသည် raster layer ထဲရှိ pixel တစ်ခုချင်းစီ၏ extent အတွက် polygon feature များဖန်တီးခြင်းဖြင့် raster layer တစ်ခုကို vector layer တစ်ခုသို့ပြောင်းလဲပေးခြင်းဖြစ်သည်။ Nodata pixel များကို ouput ထဲတွင် ထည့်သွင်းပေးမည်မဟုတ်ပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Raster layer |
|
[raster] |
Input ရာစတာ layer |
Band number (လှိုင်းအလွှာ နံပါတ်) |
|
[raster band] |
အချက်အလက်ထုတ်ယူရမည့် raster band |
Field name (Field အမည်) |
|
[string] Default: ‘VALUE’ |
Raster band တန်ဖိုးအား သိမ်းဆည်းမည့် field ၏အမည် |
Vector polygons |
|
[vector: polygon] Default: |
Pixel extent များ၏ ရလာဒ် polygon layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Vector polygons |
|
[vector: polygon] |
Pixel extent များ၏ ရလာဒ် polygon layer |
Python code
Algorithm ID: native:pixelstopolygons
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.16.17. အကွာအဝေးညီ အမှတ်များ (Regular points)
သတ်မှတ်ထားသော extent တစ်ခုအတွင်း အကွာအဝေး အညီအမျှရှိသည့် grid ထဲတွင် နေရာချထားသော point များဖြင့် point layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
Grid ကို point များကြား spacing (ကြားအကွာအဝေး)ဖြင့်ဖြစ်စေ (ရှုထောင့်အားလုံးအတွက် တူညီသော spacing) သို့မဟုတ် ဖန်တီးရမည့် point များအရေအတွက်ဖြင့်ဖြစ်စေ သတ်မှတ်ပါသည်။ Point များ၏အရေအတွက်ဖြင့် သတ်မှတ်လိုပါက spacing အား extent မှဆုံးဖြတ်လိမ့်မည်ဖြစ်သည်။ ထောင့်မှန်စတုဂံပုံ grid ကွက် အပြည့်တစ်ခုကိုဖန်တီးရန်အတွက် အသုံးပြုသူမှသတ်မှတ်ထားသော အနည်းဆုံး point အရေအတွက်ကို ထုတ်ပေးမည်ဖြစ်သည်။
Point များအကြား spacing တွင် ကျပန်း offset များ ထားရှိပေးနိုင်ပြီး ထိုသို့ထားရှိခြင်းသည် အညီအမျှမဟုတ်သော point ပုံစံကို ရရှိစေမည်ဖြစ်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input extent (xmin, xmax, ymin, ymax) (ထည့်သွင်းအသုံးပြုသော နယ်ပယ်အတိုင်းအတာ (xmin၊ xmax၊ ymin၊ ymax)) |
|
[extent] |
ကျပန်း point များအတွက် မြေပုံ extent အသုံးပြုနိုင်သော နည်းလမ်းများမှာ -
|
Point spacing/count (Point ကြားအကွာအဝေး/အရေအတွက်) |
|
[number] Default: 100 |
Point များကြား spacing သို့မဟုတ် point များအရေအတွက် ၊ |
Initial inset from corner (LH side) (ထောင့်မှအစပြုခြင်း (ဘယ်ဘက်)) |
|
[number] Default: 0.0 |
ဘယ်ဘက် အပေါ်ထောင့်နှင့်နှိုင်းရဖြစ်သော point များကို offset လုပ်ပေးပါသည်။ ဤ တန်ဖိုးကို X ဝင်ရိုး နှင့် Y ဝင်ရိုးနှစ်ခုစလုံးအတွက် အသုံးပြုပါသည်။ |
Apply random offset to point spacing (Point spacing များတွင် ကျပန်း offset အသုံးပြုခြင်း) |
|
[boolean] Default: False |
အမှန်ခြစ်ပေးထားပါက အမှတ်များတွင် ကျပန်းအကွာအဝေးနှင့်ခြားနားနေမည်။ |
Use point spacing (Point spacing အသုံးပြုခြင်း) |
|
[boolean] Default: True |
အမှန်ခြစ်မပေးထားပါက point spacing ကိုထည့်သွင်းစဉ်းစားမည်မဟုတ်ပါ။ |
Output layer CRS (Output layer တွင်အသုံးပြုသော CRS) |
|
[crs] Default: Project CRS |
ကျပန်း point layer ၏ CRS |
Regular points (အကွာအဝေးညီသော point များ) |
|
[vector: point] Default: |
အကွာအဝေးညီသော point layer output ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Regular points (အကွာအဝေးညီသော point များ) |
|
[vector: point] |
အကွာအဝေးညီသော point layer output |
Python code
Algorithm ID: qgis:regularpoints
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။