29.1.17. Vector ဆိုင်ရာ အထွေထွေ (Vector general)
29.1.17.1. မြေပုံအရိပ်ချစနစ် သတ်မှတ်ခြင်း (Assign projection)
Vector layer တစ်ခုတွင် projection (မြေပုံအရိပ်ချစနစ်) အသစ်တစ်ခုအား သတ်မှတ်ထည့်သွင်းပေးပါသည်။
Input layer တစ်ခုနှင့် အတိအကျတူသည့် feature များနှင့်ဂျီဩမေတြီများရှိသည့် layer အသစ်တစ်ခုကိုဖန်တီးပေးပါသည်။ သို့သော် CRS အသစ်တစ်ခုကိုအသုံးပြုမည်ဖြစ်သည်။ ဂျီဩမေတြီများကို projection တစ်ခုမှတစ်ခုသို့ပြောင်းလဲခြင်း (reprojection) မဟုတ် ဘဲ မတူညီသော CRS တစ်ခုကိုသာထည့်သွင်းလိုက်ခြင်းဖြစ်သည်။
ဤ algorithm အား မမှန်ကန်သော projection သတ်မှတ်ထားမိသည့် layer များကိုပြင်ဆင်ရန် အသုံးပြုနိုင်ပါသည်။
ဤ algorithm သည် Attribute များကို ပြောင်းလဲပြင်ဆင်မည်မဟုတ်ပါ။
See also
Shapefile ၏ projection သတ်မှတ်ခြင်း (Define Shapefile projection) ၊ Projection ရှာဖွေခြင်း (Find projection) ၊ Layer ကို projection ပြောင်းခြင်း (Reproject layer)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
CRS မှားယွင်းနေသော သို့မဟုတ် CRS မပါရှိသော vector layer |
Assigned CRS (သတ်မှတ်ပေးမည့် CRS) |
|
[crs] Default: |
Vector layer တွင်သတ်မှတ်အသုံးပြုရမည့် CRS အသစ်ကိုရွေးချယ်ပါ |
Assigned CRS (CRS သတ်မှတ်ထားပြီးသော) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Assigned CRS (CRS သတ်မှတ်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
သတ်မှတ်ထည့်သွင်းထားသည့် projection ဖြင့် vector layer |
Python code
Algorithm ID: native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.2. လိပ်စာအစုလိုက် ကို တည်နေရာရှာပေးသည့် Nominatim geocoder (Batch Nominatim geocoder)
String (စာသား) field ပါရှိသော input layer တစ်ခုအတွက် Nominatim service ကို အသုံးပြု၍ အစုလိုက် geocoding(လိပ်စာများနှင့် နေရာအမည်များအား ပထဝီဝင်ဆိုင်ရာ ကိုဩဒိနိတ်များအဖြစ်ပြောင်းလဲခြင်း) ကိုလုပ်ဆောင်ပေးပါသည်။ Output layer တွင် ကိုဩဒိနိတ်ဖြင့် ပြောင်းလဲဖော်ပြထားသော တည်နေရာအပြင် ၎င်း တည်နေရာနှင့်ဆက်စပ်နေသည့် attribute အချို့ ကိုကိုယ်စားပြုသည့် point ဂျီဩမေတြီတစ်ခု ပါဝင်ပါလိမ့်မည်။
 တွင် အမှန်ခြစ်ပေးခြင်းဖြင့် point feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ကိုအသုံးပြုနိုင်ပါသည်။
တွင် အမှန်ခြစ်ပေးခြင်းဖြင့် point feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ကိုအသုံးပြုနိုင်ပါသည်။
Note
ဤ algorithm သည် OpenStreetMap ဖောင်ဒေးရှင်းမှ ပံ့ပိုးသော Nominatim geocoding ဝန်ဆောင်မှု၏ အသုံးပြုမှု မူဝါဒ ကို လိုက်နာပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Feature များကို geocode ပြုလုပ်ရမည့် vector layer |
Address field (လိပ်စာဖော်ပြထားသော field) |
|
[tablefield: string] |
Geocode ပြုလုပ်ရန် လိပ်စာများပါဝင်သော Field |
Geocoded (Geocode ပြုလုပ်ထားသော) |
|
[vector: point] Default: |
Geocode ပြုလုပ်ထားပြီးသော လိပ်စာ များသာပါဝင်သော output layer အား သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Geocoded (Geocode ပြုလုပ်ထားသော) |
|
[vector: point] |
Geocode ပြုလုပ်ထားသော လိပ်စာများနှင့်သက်ဆိုင်သော point feature များပါဝင်သည့် vector layer |
Python code
Algorithm ID: native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.3. Layer ကို spatial bookmark များအဖြစ်ပြောင်းခြင်း (Convert layer to spatial bookmarks)
Layer တစ်ခုတွင်ပါဝင်သည့် feature များ၏ extent နှင့် သက်ဆိုင်သော spatial (တည်နေရာဆိုင်ရာ) bookmark များကိုဖန်တီးပေးပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: line, polygon] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Bookmark destination (Bookmark ထားရှိမည့် နေရာ) |
|
[enumeration] Default: 0 |
Bookmark များအတွက် ထားရှိမည့်နေရာကိုရွေးချယ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
Name field (အမည် field) |
|
[expression] |
ထွက်ရှိလာသော bookmark များအား အမည်ပေးမည့် Field သို့မဟုတ် expression |
Group field (အုပ်စု field) |
|
[expression] |
ထွက်ရှိလာသော bookmark များအား အုပ်စုများဖန်တီးပေးမည့် Field သို့မဟုတ် expression |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Count of bookmarks added (ထည့်သွင်းထားသော bookmark များအရေအတွက်) |
|
[number] |
Python code
Algorithm ID: native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.4. spatial bookmark များကို layer အဖြစ် ပြောင်းလဲခြင်း (Convert spatial bookmarks to layer)
သိမ်းဆည်းထားသော တည်နေရာဆိုင်ရာ (spatial) bookmark များအတွက် polygon feature များပါဝင်သည့် layer အသစ်တစ်ခုကိုဖန်တီးပေးပါသည်။ Export ထုတ်ရာ၌ လက်ရှိ project နှင့်သက်ဆိုင်သော bookmark များကိုသာ၊ အသုံးပြုသူ bookmark များအားလုံး သို့မဟုတ် နှစ်ခုစလုံးနှင့် သက်ဆိုင်သော bookmark များကို စစ်ထုတ်နိုင်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Bookmark source (Bookmark ရင်းမြစ်) |
|
[enumeration] [list] Default: [0,1] |
Bookmark များ၏ ရင်းမြစ်(များ) ကိုရွေးချယ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို၍ အသုံးပြုနိုင်သည်-
|
Output CRS (ရလာဒ်တွင်အသုံးပြုမည့် CRS) |
|
[crs] Default: |
Output layer ၏ CRS |
Output (ရလာဒ်) |
|
[vector: polygon] Default: |
Output layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Output (ရလာဒ်) |
|
[vector: polygon] |
Bookmark များပါဝင်သည့် output vector layer |
Python code
Algorithm ID: native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.5. Attribute အညွှန်းစနစ်ဖန်တီးခြင်း (Create attribute index)
Attribute ဇယားမှ field တစ်ခုတွင် အချက်အလက်များရှာဖွေရာ၌ ပိုမိုမြန်ဆန်စေရန် အညွှန်းကိန်း (index) တစ်ခုကိုဖန်တီးပေးပါသည်။ Index ဖန်တီးခြင်းသည် layer ၏ data ထောက်ပံ့ပေးသူ နှင့် field အမျိုးအစား နှစ်ခုလုံးပေါ်တွင်မူတည်ပါသည်။
မည်သည့် output ကိုမျှဖန်တီးမည်မဟုတ်ဘဲ index အား layer ထဲတွင်ပင်သိမ်းဆည်းထားပေးမည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
Attribute index တစ်ခုအား ဖန်တီးမည့် vector layer ကိုရွေးချယ်ပါ။ |
Attribute to index (Index ဖန်တီးရမည့် Attribute) |
|
[tablefield: any] |
Vector layer မှ Field |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Indexed layer (အညွှန်းကိန်း ဖန်တီးထားသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
သတ်မှတ်ထားသော field တစ်ခုအတွက် index တစ်ခုပါရှိသည့် input vector layer ၏ မိတ္တူတစ်ခု |
Python code
Algorithm ID: native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.6. တည်နေရာဆိုင်ရာ အညွှန်းစနစ်ဖန်တီးခြင်း (Create spatial index)
Layer တစ်ခုထဲရှိ feature များ၏ spatial တည်နေရာအပေါ်အခြေခံ၍ ၎င်းတို့ကို လျင်မြန်စွာရှာဖွေနိုင်ရန်အတွက် index တစ်ခုကို ဖန်တီးပေးပါသည်။ တည်နေရာဆိုင်ရာ index ဖန်တီးခြင်းသည် layer ၏ data ပံ့ပိုးပေးသူပေါ်တွင် မူတည်ပါသည်။
Output layer အသစ်များကို ဖန်တီးမည်မဟုတ်ပါ။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Indexed layer (အညွှန်းကိန်း ပြုလုပ်ထားသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
တည်နေရာဆိုင်ရာ index တစ်ခုပါရှိသော input vector layer ၏ မိတ္တူတစ်ခု |
Python code
Algorithm ID: native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.7. Shapefile ၏ projection သတ်မှတ်ခြင်း (Define Shapefile projection)
ရှိနေပြီးသား Shapefile format dataset တစ်ခု၏ CRS (projection) ကို သတ်မှတ်ထားသော CRS အတိုင်း ဖြစ်အောင် သတ်မှတ်ပေးပါသည်။ Shapefile format dataset တစ်ခုတွင် prj file သည် ပျောက်နေပြီး အသုံးပြုရမည့် မှန်ကန်သည့် projection အားသိလျှင် ဤ algorithm သည် လွန်စွာအသုံးဝင်ပါသည်။
မြေပုံအရိပ်ချစနစ် သတ်မှတ်ခြင်း (Assign projection) algorithm နှင့်မတူညီသောအချက်မှာ layer အသစ်တစ်ခုကို ထပ်မံဖန်တီးမည်မဟုတ်ဘဲ လက်ရှိ layer ကိုသာ မွမ်းမံပြင်ဆင်မည်ဖြစ်သည်။
Note
Shapefile dataset များအတွက် သတ်မှတ်ထားသော CRS နှင့်ကိုက်ညီမှုရှိစေရန် .prj နှင့် .qpj ဖိုင်များအား အစားထိုးလုပ်ဆောင်မည်ဖြစ်သည်- သို့မဟုတ် ထိုဖိုင်များ ပျောက်ဆုံးနေပါက အသစ်ဖန်တီးမည်ဖြစ်သည်။
Default menu-
See also
မြေပုံအရိပ်ချစနစ် သတ်မှတ်ခြင်း (Assign projection) ၊ Projection ရှာဖွေခြင်း (Find projection) ၊ Layer ကို projection ပြောင်းခြင်း (Reproject layer)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
Projection အချက်အလက်များ ပျောက်နေသည့် vector layer |
CRS |
|
[crs] |
Vector layer တွင် သတ်မှတ်အသုံးပြုမည့် CRS ကိုရွေးချယ်ပါ။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
သတ်မှတ်ထားသော projection ပါရှိသည့် input vector layer |
Python code
Algorithm ID: qgis:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.8. ပုံတူဖြစ်ထပ်နေသော ဂျီဩမေတြီများကို ဖျက်ပေးခြင်း (Delete duplicate geometries)
ပုံတူဖြစ်နေသော ဂျီဩမေတြီများကို ရှာဖွေ၍ ဖယ်ရှားပေးပါသည်။
Attribute များကိုစစ်ဆေးမည်မဟုတ်သောကြောင့် feature နှစ်ခုတွင် ထပ်တူညီသည့် ဂျီဩမေတြီများ ရှိသော်လည်း မတူညီသည့် attribute များရှိပါက ၎င်းတို့ထဲမှတစ်ခုကိုသာလျှင် ရလာဒ် layer ထဲတွင် ထည့်သွင်းမည်ဖြစ်သည်။
See also
ဂျီဩမေတြီများ ချန်ထားခြင်း (Drop geometries) ၊ အကောင်အထည့်မဲ့ဂျီဩမေတြီများကိုဖယ်ရှားခြင်း (Remove null geometries) ၊ Attribute တူနေသောအရာများကို ဖျက်ပေးခြင်း (Delete duplicates by attribute)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ရှင်းလင်းလိုသည့် ပုံတူဖြစ်နေသော ဂျီဩမေတြီများ ပါဝင်နေသည့် layer |
Cleaned (ရှင်းလင်းထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Count of discarded duplicate records (ဖျက်ထားသော ပုံတူဖြစ်နေသော မှတ်တမ်းများ၏ အရေအတွက်) |
|
[number] |
ဖျက်ထားသော ပုံတူဖြစ်နေသော မှတ်တမ်းများ၏ အရေအတွက် |
Cleaned (ရှင်းလင်းထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ပုံတူဖြစ်နေသော ဂျီဩမေတြီများ မပါရှိသည့် output layer |
Count of retained records (ဆက်လက်ထားရှိသည့် မှတ်တမ်းများအရေအတွက်) |
|
[number] |
သီးခြားကွဲပြား (unique) နေသော မှတ်တမ်းများအရေအတွက် |
Python code
Algorithm ID: native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.9. Attribute တူနေသောအရာများကို ဖျက်ပေးခြင်း (Delete duplicates by attribute)
သတ်မှတ်ထားသော field / field များကိုသာ ထည့်သွင်းစဉ်းစား၍ ပုံတူဖြစ်နေသော row များကိုဖျက်ပေးပါသည်။ ပထမဆုံး ကိုက်ညီသော row သာကျန်ရှိမည်ဖြစ်ပြီး ပုံတူဖြစ်နေသောအရာများကို ဖျက်ပစ်မည်ဖြစ်သည်။
Optional အနေဖြင့် ထို ပုံတူဖြစ်နေသော မှတ်တမ်းများအား လေ့လာဆန်းစစ်ခြင်းပြုလုပ်နိုင်ရန်အတွက် သီးခြား output ဖိုင်တစ်ခုထဲတွင် သိမ်းဆည်းထားနိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော layer |
Fields to match duplicates by (ပုံတူဖြစ်နေသောအရာများကို ရှာဖွေရန် အသုံးပြုသည့် Field များ) |
|
[tablefield: any] [list] |
ပုံတူဖြစ်နေသောအရာများကို သတ်မှတ်ဖော်ပြပေးသော Field များ ။ ထို Field များအားလုံးအတွက် ထပ်တူညီသောတန်ဖိုးများရှိသည့် feature များကို ပုံတူဖြစ်နေသောအရာများအဖြစ် သတ်မှတ်မည်ဖြစ်သည်။ |
Filtered (no duplicates) (စစ်ထုတ်ထားသော (ပုံတူဖြစ်နေသောအရာများမပါဝင်သော)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
သီးခြားကွဲပြားသော feature များပါဝင်သော output layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Filtered (duplicates) (စစ်ထုတ်ထားသော (ပုံတူဖြစ်နေသောအရာများပါဝင်နေသော)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ပုံတူဖြစ်နေသောအရာများသာပါဝင်သည့် output layer အားသတ်မှတ်ပါ။ အောက်ပါတို့မှ တစ်ခုဖြင့်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Filtered (duplicates) (စစ်ထုတ်ထားသော (ပုံတူဖြစ်နေသောအရာများပါဝင်နေသော)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ဖယ်ရှားထားသော feature များပါဝင်သည့် vector layer ။ မသတ်မှတ်ထားပါက ဖန်တီးပေးမည်မလုပ်ပါ ( |
Count of discarded duplicate records (ဖျက်လိုက်သော ပုံတူဖြစ်နေသည့်အရာများ ၏အရေအတွက်) |
|
[number] |
ဖျက်လိုက်သော ပုံတူဖြစ်နေသောအရာများ၏ အရေအတွက် |
Filtered (no duplicates) (စစ်ထုတ်ထားသော (ပုံတူဖြစ်နေသောအရာများမပါဝင်သော)) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
သီးခြား ကွဲပြားသည့် feature များပါဝင်သော vector layer |
Count of retained records (ဆက်လက်ထားရှိသော မှတ်တမ်းများအရေအတွက်) |
|
[number] |
သီးခြား ကွဲပြားသည့်မှတ်တမ်းများ၏ အရေအတွက် |
Python code
Algorithm ID: native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.10. Dataset အပြောင်းအလဲများကို ရှာဖွေဖော်ထုတ်ခြင်း (Detect dataset changes)
Vector layer နှစ်ခုကို နှိုင်းယှဉ်ပေး၍ ၎င်းတို့ကြားတွင် မည်သည့် feature များသည် မပြောင်းလဲပဲရှိနေသည်၊ ပေါင်းထည့်ထားသည် သို့မဟုတ် ဖျက်ပစ်ထားသည် တို့ကို ဆုံးဖြတ်ပေးသည်။ Dataset တူညီပြီး မတူကွဲပြားသော ပုံစံနှစ်မျိုးအား နှိုင်းယှဉ်ရန် ၎င်းကို ဖန်တီးထားခြင်းဖြစ်သည်။
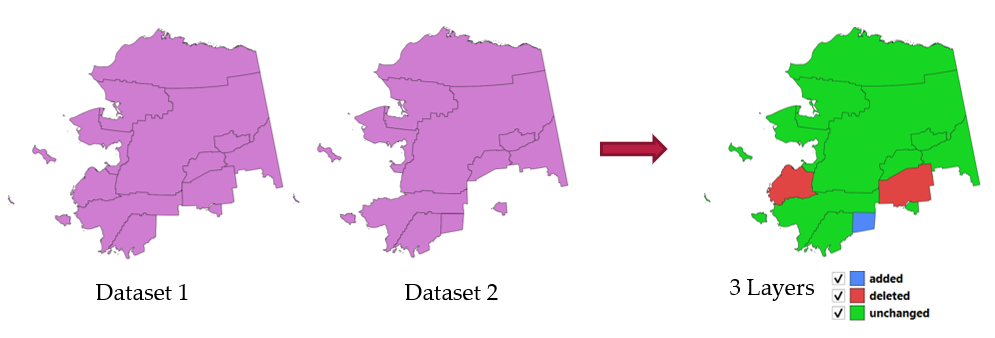
Fig. 29.46 Dataset ပြောင်းလဲသွားမှုအား ရှာဖွေဖော်ထုတ်ခြင်း ဥပမာ
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Original layer (မူရင်း layer) |
|
[vector: any] |
မူရင်းပုံစံ အဖြစ် သတ်မှတ်စဉ်းစားသည့် vector layer |
Revised layer (စိစစ်ပြင်ဆင်ထားသော layer) |
|
[vector: any] |
စိစစ်ပြင်ဆင်ထားသော သို့မဟုတ် ပြုပြင်ပြောင်းလဲထားသော layer |
Attributes to consider for match (ကိုက်ညီမှုရှိမရှိ ရှာဖွေကြည့်ရှုရမည့် Attribute များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] [list] |
ကိုက်ညီမှုရှိမရှိ ရှာဖွေကြည့်ရှုရမည့် Attribute များ။ Default အားဖြင့် attribute များအားလုံးကို နှိုင်းယှဉ်ပေးမည်ဖြစ်သည်။ |
Geometry comparison behavior (ဂျီဩမေတြီ ကို နှိုင်းယှဉ်စစ်ဆေးသည့်ပုံစံ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[enumeration] Default: 1 |
နှိုင်းယှဉ်စစ်ဆေးမည့် စံ (criteria) အားသတ်မှတ်ပေးပါသည်။ ရွေးချယ်စရာများမှာ-
|
Unchanged features (ပြောင်းလဲခြင်းမရှိသော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: Original layer နှင့်အတူတူဖြစ်ပါသည်] |
ပြောင်းလဲခြင်းမရှိသော feature များပါရှိသည့် output vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Added features (ပေါင်းထည့်ထားသော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: Original layer နှင့်အတူတူဖြစ်ပါသည်] |
ပေါင်းထည့်ထားသော feature များပါရှိသည့် output vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Deleted features (ဖျက်ထားသော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[vector: Original layer နှင့်အတူတူဖြစ်ပါသည်] |
ဖျက်ထားပြီးသော feature များ ပါရှိသည့် output vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Unchanged features (ပြောင်းလဲခြင်းမရှိသော feature များ) |
|
[vector: Original layer နှင့်အတူတူဖြစ်ပါသည်] |
ပြောင်းလဲခြင်းမရှိသော feature များပါဝင်သည့် vector layer |
Added features (ပေါင်းထည့်ထားသော feature များ) |
|
[vector: Original layer နှင့်အတူတူဖြစ်ပါသည်] |
ပေါင်းထည့်ထားသော feature များ ပါဝင်သည့် vector layer |
Deleted features (ဖျက်ထားသော feature များ) |
|
[vector: Original layer နှင့်အတူတူဖြစ်ပါသည်] |
ဖျက်ထားသော featureများ ပါဝင်သည့် vector layer |
Count of unchanged features (ပြောင်းလဲခြင်းမရှိသော feature များ၏အရေအတွက်) |
|
[number] |
ပြောင်းလဲခြင်းမရှိသော feature များ၏အရေအတွက် |
Count of features added in revised layer (စိစစ်ပြင်ဆင်ထားသော layer တွင် ထည့်သွင်းထားသော feature များ၏အရေအတွက်) |
|
[number] |
စိစစ်ပြင်ဆင်ထားသော layer တွင် ထည့်သွင်းထားသော feature များ၏အရေအတွက် |
Count of features deleted from original layer (မူရင်း layer မှဖျက်ထားပြီးသော feature များ၏အရေအတွက်) |
|
[number] |
မူရင်း layer မှ ဖျက်ထားပြီးသော feature များ၏အရေအတွက် |
Python code
Algorithm ID: native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.11. ဂျီဩမေတြီများ ချန်ထားခြင်း (Drop geometries)
Input layer ၏ attribute ဇယားအတွက် ရိုးရှင်းသော ဂျီဩမေတြီဆိုင်ရာအချက်အလက်မပါရှိသည့် မိတ္တူတစ်ခုအားဖန်တီးပေးပါသည်။ မူရင်း layer ၏ Attribute ဇယားကို ဆက်လက်ထားရှိပေးမည်ဖြစ်သည်။
ဖိုင်ကို စက်အတွင်းရှိ folder တစ်ခုထဲတွင်သိမ်းဆည်းလျှင် ရလာဒ် အတွက် ဖိုင် format အမျိုးအစားများစွာရွေးချယ်နိုင်ပါသည်။
အားအမှန်ခြစ်ပေးခြင်းဖြင့် point ၊ line နှင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ကိုအသုံးပြုနိုင်မည်ဖြစ်သည်။
See also
ပုံတူဖြစ်ထပ်နေသော ဂျီဩမေတြီများကို ဖျက်ပေးခြင်း (Delete duplicate geometries) ၊ အကောင်အထည့်မဲ့ဂျီဩမေတြီများကိုဖယ်ရှားခြင်း (Remove null geometries)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer ထည့်သွင်းအသုံးပြုသော layer |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Dropped geometries (ဂျီဩမေတြီများ ဖယ်ရှားထားပြီးသော) |
|
[table] |
ဂျီဩမေတြီမပါရှိသည့် output layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Dropped geometries (ဂျီဩမေတြီများ ဖယ်ရှားထားပြီးသော) |
|
[table] |
ဂျီဩမေတြီမပါရှိသည့် output layer ။ မူရင်း attribute ဇယား၏ မိတ္တူတစ်ခု ။ |
Python code
Algorithm ID: native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.12. SQL လုပ်ဆောင်ခြင်း (Execute SQL)
ရင်းမြစ် layer ပေါ်တွင် SQL syntax ကိုအသုံးပြု၍ ရိုးရှင်းသော သို့မဟုတ် ရှုပ်ထွေးသော query (database တစ်ခုမှအချက်အလက်များထုတ်ယူရန် တောင်းခံခြင်း) ကို လုပ်ဆောင်ပေးပါသည်။
Input datasource များကို input1 ၊ input2… inputN အစရှိသည်တို့ဖြင့် အမျိုးအစားသတ်မှတ်ပြီး ရိုးရှင်းသော query တစ်ခုသည် SELECT * FROM input1 ကဲ့သို့ဖြစ်ပါလိမ့်မည်။
ရိုးရှင်းသော query တစ်ခုအပြင် expression များ သို့မဟုတ် variable (ကိန်းရှင်) များကို SQL query parameter ထဲတွင် ထည့်သွင်းနိုင်ပါသည်။ အကယ်၍ ဤ algorithm အား Processing model တစ်ခုအတွင်း လုပ်ဆောင်ပြီး query ၏ parameter တစ်ခုအနေဖြင့် model input တစ်ခုကို အသုံးပြုလိုလျှင် အထူးသဖြင့်အသုံးဝင်မည်ဖြစ်သည်။ ဥပမာအားဖြင့် query တစ်ခုသည် SELECT * FROM [% @table %] ဖြစ်ပြီး @table သည် model input ကိုသတ်မှတ်ပေးသည့် variable ဖြစ်ပါသည်။
Query မှရရှိလာသော ရလာဒ် အား layer အသစ်တစ်ခုအဖြစ် ပေါင်းထည့်ပေးမည်ဖြစ်သည်။
See also
SpatiaLite တွင် SQL ကိုစေခိုင်းလုပ်ဆောင်ခြင်း (SpatiaLite execute SQL) ၊ PostgreSQL မှ SQL ကိုစေခိုင်းလုပ်ဆောင်ခြင်း (PostgreSQL execute SQL)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Additional input datasources (called input1, .., inputN in the query) (ထပ်ဆောင်း input datasource များ (Query ထဲတွင် input1၊ ..၊ inputN ဟုခေါ်သည်)) |
|
[vector: any] [list] |
Query ပြုလုပ်ရန် layer များ၏စာရင်း။ SQL editor ထဲတွင် ထို layer များအား ၎င်းတို့၏ နာမည် အရင်း ဖြင့် သို့မဟုတ် ရွေးချယ်ထားသော layer အရေအတွက်ပေါ်မူတည်၍ input1 ၊ input2 ၊ inputN စသည့် အမည်များဖြင့် ရည်ညွှန်းပေးနိုင်သည်။ |
SQL query |
|
[string] |
SQL query စာသားအားရိုက်ထည့်ပါ၊ ဥပမာအားဖြင့် |
Unique identifier field (Unique ဖြစ်သော ခွဲခြားသတ်မှတ်ပေးမည့် field) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
သီးခြားကွဲပြားသည့် ID ဖြင့် column အားသတ်မှတ်ပါ။ |
Geometry field (ဂျီဩမေတြီ field) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
ဂျီဩမေတြီ field အားသတ်မှတ်ပါ |
Geometry type (ဂျီဩမေတြီ အမျိုးအစား) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[enumeration] Default: 0 |
ရလာဒ်အတွက် ဂျီဩမေတြီကို ရွေးချယ်ပါ။ Default အားဖြင့် algorithm သည် အလိုအလျောက် ရှာဖွေဖော်ထုတ်ပေးမည်ဖြစ်သည်။ အောက်ပါတို့မှတစ်ခုဖြင့်-
|
CRS Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[crs] |
Output layer တွင် သတ်မှတ်အသုံးပြုမည့် CRS |
SQL Output (SQL ရလာဒ်) |
|
[vector: any] Default: |
Query ဖြင့် ဖန်တီးထားသော output layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
SQL Output (SQL ရလာဒ်) |
|
[vector: any] |
Query ဖြင့် ဖန်တီးထားသော vector layer |
Python code
Algorithm ID: qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.13. Layer များကို DXF ဖိုင်အဖြစ် ထုတ်ယူခြင်း (Export layers to DXF)
Layer များကို DXF file အဖြစ်သို့ Export ထုတ်ပေးပါသည်။ Layer တစ်ခုစီအတွက် field တစ်ခုကို ရွေးချယ်နိုင်ပြီး ၎င်း field မှ တန်ဖိုးများကို အသုံးပြု၍ DXF output ထဲရှိ ထုတ်ယူထားသော ဦးတည်ရာ layer များထဲမှ feature များကို အပိုင်းများအဖြစ် ပိုင်းခြားပေးပါသည်။
See also
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layers (ထည့်သွင်းအသုံးပြုသော layer များ) |
|
[vector: any] [list] |
Export ပြုလုပ်မည့် input vector layer များ |
Symbology mode (သင်္ကေတဆိုင်ရာ ပုံစံ) |
|
[enumeration] Default: 0 |
Output layer များတွင် အသုံးပြုမည့် သင်္ကေတအမျိုးအစားကို အောက်ပါတို့မှရွေးချယ်နိုင်မည်-
|
Symbology scale (သင်္ကေတများအတွက် စကေး) |
|
[scale] Default: 1:1 000 000 |
Data export လုပ်ရာတွင် သုံးသော Default စကေး |
Encoding |
|
[enumeration] |
Layer များတွင် အသုံးပြုမည့် encoding |
CRS |
|
[crs] |
Output layer အတွက် CRS အားရွေးချယ်ပါ။ |
Use layer title as name (Layer ၏ ခေါင်းစဉ်ကို အမည်အဖြစ်အသုံးပြုခြင်း) |
|
[boolean] Default: False |
Output layer အား layer ၏ အမည်အစား layer ခေါင်းစဉ်ဖြင့် အမည်ပေးခြင်း (QGISတွင် သတ်မှတ်ထားသည့်အတိုင်း) |
Force 2D (နှစ်ဘက်မြင်ပုံစံကို တွန်းအားပေးလုပ်ဆောင်ခြင်း) |
|
[boolean] Default: False |
|
Export labels as MTEXT elements (အညွှန်းများကို MTEXT element များအဖြစ် Export ထုတ်ပေးခြင်း) |
|
[boolean] Default: False |
အညွှန်းများကို MTEXT သို့မဟုတ် TEXT element များအဖြစ် Export ထုတ်ပေးပါသည် |
DXF |
|
[file] Default: |
Output DXF file အတွက် သီးခြားသတ်မှတ်ချက်။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
DXF |
|
[file] |
Input layer များပါရှိသည့် |
Python code
Algorithm ID: native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.14. ရွေးချယ်ထားသော feature များကို ထုတ်ယူခြင်း (Extract selected features)
ရွေးချယ်ထားသော feature များကို layer အသစ်တစ်ခုအဖြစ် သိမ်းဆည်းပေးပါသည်။
Note
အကယ်၍ ရွေးချယ်လိုက်သော layer တွင် feature များရွေးချယ်ထားခြင်းမရှိပါက အသစ်ဖန်တီးလိုက်သော layer သည် ဗလာ (empty) ဖြစ်နေပါမည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
သိမ်းဆည်းရန် ရွေးချယ်မှုလုပ်ဆောင်ရမည့် Layer |
Selected features (ရွေးချယ်ထားသော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ရွေးချယ်ထားသော feature များအတွက် vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Selected features (ရွေးချယ်ထားသော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရွေးချယ်ထားသော feature များသာပါဝင်သည့် vector layer သို့မဟုတ် မည်သည်ကိုမျှမရွေးချယ်ထားပါက feature မပါရှိသော vector layer |
Python code
Algorithm ID: native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.15. Shapefile encoding ကို ထုတ်ယူခြင်း (Extract Shapefile encoding)
Shapefile တစ်ခုအတွင်း ထည့်သွင်းထားသော attribute encoding အချက်အလက်ကို ထုတ်ယူပေးပါသည်။ Optional .cpg file တစ်ခုမှ သတ်မှတ်ထားသော encoding နှင့် .dbf LDID header block ထဲတွင်ရှိသော မည်သည့် encoding အသေးစိတ်အချက်အလက်များမဆို ထည့်သွင်းစဉ်းစားမည်ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
Encoding အချက်အလက်များကိုထုတ်ယူမည့် ESRI Shapefile ( |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Shapefile encoding |
|
[string] |
Input file ထဲတွင် သတ်မှတ်ထားသော encoding အချက်အလက်များ |
CPG encoding |
|
[string] |
မည်သည့် |
LDID encoding |
|
[string] |
|
Python code
Algorithm ID: native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.16. Projection ရှာဖွေခြင်း (Find projection)
Layer တစ်ခုတွင် ၎င်း၏ projection ကိုမသိပါက သင့်လျော်သော ကိုသြဒိနိတ်ရည်ညွှန်းစနစ် (CRS) များပါဝင်သည့် ဇကာတင်စာရင်းတစ်ခုအား ဖန်တီးမည်ဖြစ်သည်။
Layer မှလွှမ်းခြုံရန် မျှော်မှန်းထားသောဧရိယာကို ဦးတည်ရာ (target) ဧရိယာ parameter မှတဆင့် သတ်မှတ်ပေးရပါမည်။ ဤ target ဧရိယာအတွက် အသုံးပြုမည့် ကိုသြဒိနိတ်ရည်ညွှန်းစနစ် သည် QGIS မှ သိရှိသည့်အရာ ဖြစ်ရပါမည်။
ဤ algorithm သည် သိရှိထားပြီးသည့် CRS တိုင်းတွင် layer ၏ extent ကို စစ်ဆေးပြီးနောက် layer သည် ဤ projection ထဲတွင်ဖြစ်ခဲ့လျှင် target ဧရိယာနှင့်နီးစပ်သော projection များကို စာရင်းပြုစုခြင်းအားဖြင့် လုပ်ဆောင်ပါသည်။
See also
မြေပုံအရိပ်ချစနစ် သတ်မှတ်ခြင်း (Assign projection) ၊ Shapefile ၏ projection သတ်မှတ်ခြင်း (Define Shapefile projection) ၊ Layer ကို projection ပြောင်းခြင်း (Reproject layer)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
Projection မသိရှိသော Layer |
Target area for layer (xmin, xmax, ymin, ymax) (Layer အတွက် ဦးတည် ဧရိယာ (xmin၊ xmax၊ ymin၊ ymax)) |
|
[extent] |
Layer မှ လွှမ်းခြုံထားသော ဧရိယာ။ အသုံးပြုနိုင်သော နည်းလမ်းများမှာ -
|
CRS candidates (ရွေးချယ်စရာ CRS များ) |
|
[table] Default: |
Coordinate Reference System (CRS) အကြံပြုချက်များ (EPSG codes) အတွက် ဇယား(ဂျီဩမေတြီမပါရှိသော layer) အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
CRS candidates (ရွေးချယ်စရာ CRS များ) |
|
[table] |
ပေးထားသော စံနှုန်းများနှင့် ကိုက်ညီသော CRS (EPSG codes) အားလုံးပါဝင်သည့် ဇယားတစ်ခု။ |
Python code
Algorithm ID: qgis:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.17. ဆက်စပ်အချက်များကိုပေါင်းဝင်စေခြင်း (Flatten relationship)
Vector layer တစ်ခုအတွက် relationship (ဆက်နွယ်မှု) တစ်ခုအား ပြေပြစ်ချောမွေ့စေပြီး ဆက်စပ်နေသော child (အခွဲ) feature တစ်ခုလျှင် parent (မူရင်း) feature တစ်ခု ပါဝင်သော layer တစ်ခုတည်းအဖြစ် export ထုတ်ပေးပါသည်။ ဤ ပင်မ (master) feature တွင် ဆက်စပ်နေသည့် feature များအတွက် attribute များ အားလုံးပါဝင်ပါသည်။ ဥပမာအားဖြင့် CSV သို့ export ထုတ်နိုင်သော ဇယားတစ်ခုအဖြစ် ဆက်နွယ်မှုကို ရရှိစေမည်ဖြစ်သည်။
Fig. 29.47 ဆက်နွယ်နေသော အခွဲများပါဝင်သည် region တစ်ခု၏ပုံစံ (ဘယ်) - ဆက်နွယ်နေသော အခွဲ တစ်ခုစီအတွက် ချိတ်ဆက်ထားသော attribute များပါရှိသည့် အပွား region feature တစ်ခု (ညာ)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
ပြေပြစ်ချောမွေ့စေရန် ပြုလုပ်သင့်သည့် ဆက်နွယ်မှု ပါရှိသော layer |
Flattened Layer (ပြေပြစ်ချောမွေ့အောင်ပြုလုပ်ထားသော Layer) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output layer (ပြေပြစ်ချောမွေ့အောင်ပြုလုပ်ထားသော) အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Flattened Layer (ပြေပြစ်ချောမွေ့အောင်ပြုလုပ်ထားသော Layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ဆက်နွယ်နေသော feature များအတွက် attribute များအားလုံးပါဝင်သည့် master (ပင်မ)feature များပါရှိသော layer တစ်ခု |
Python code
Algorithm ID: native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.18. Field တန်ဖိုးဖြင့် attribute များကို ချိတ်ဆက်ခြင်း (Join attributes by field value)
Input vector layer တစ်ခုကိုယူပြီး ၎င်း၏ attribute ဇယားထဲတွင် ထပ်ဆောင်း attribute များဖြင့် ထပ်တိုးထားသော vector layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
ထပ်ဆောင်း attribute များနှင့် ၎င်းတို့၏တန်ဖိုးများကို ဒုတိယ vector layer တစ်ခုမှရယူမည်ဖြစ်သည်။ ၎င်း layer တစ်ခုစီမှ attribute တစ်ခုကိုရွေးချယ်၍ ချိတ်ဆက်မူစံနှုန်း (join criteria) ကို သတ်မှတ်ပါသည်။
See also
နီးစပ်မှုဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (Join attributes by nearest) ၊ တည်နေရာအရ attribute များကို ချိတ်ဆက်ခြင်း (Join attributes by location)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer ။ Output layer တွင် ဤ layer မှ feature များ အပြင် ဒုတိယ layer မှကိုက်ညီသော feature များ၏ attribute များလည်း ပါဝင်ပါလိမ့်သည်။ |
Table field (ဇယား field) |
|
[tablefield: any] |
ချိတ်ဆက်ရာတွင် အသုံးပြုမည့် ရင်းမြစ် layer ၏ Field |
Input layer 2 (ထည့်သွင်းအသုံးပြုသော ဒုတိယ layer) |
|
[vector: any] |
ချိတ်ဆက်ရန် attribute ဇယားပါရှိသော Layer |
Table field 2 (ဒုတိယ ဇယား field) |
|
[tablefield: any] |
ချိတ်ဆက်ရာတွင် အသုံးပြုမည့် ဒုတိယ (join) layer ၏ Field ။ ထို field ၏အမျိုးအစားသည် input ဇယား field အမျိုးအစားနှင့် တူညီရမည် (သို့မဟုတ် ကိုက်ညီမှုရှိရမည်) |
Layer 2 fields to copy (မိတ္တူကူးယူရမည့် ဒုတိယ Layer field များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] [list] |
ပေါင်းထည့်လိုသော သီးခြား field များကို ရွေးချယ်ပါ။ Default အားဖြင့် field များအားလုံးကို ပေါင်းထည့်မည်ဖြစ်သည်။ |
Join type (ချိတ်ဆက်မှု အမျိုးအစား) |
|
[enumeration] Default: 1 |
နောက်ဆုံး ချိတ်ဆက်ထားသော layer ၏ အမျိုးအစား။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
Discard records which could not be joined (ချိတ်ဆက်ခြင်းမပြုနိုင်သည့် မှတ်တမ်းများကိုဖျက်ပစ်ခြင်း) |
|
[boolean] Default: True |
ချိတ်ဆက်ခြင်းမပြုနိုင်သည့် feature များကို ဆက်လက်မထားရှိလိုပါက အမှန်ခြစ်ပေးထားပါ။ |
Joined field prefix (ချိတ်ဆက်ထားသော field အတွက် ရှေ့ဆက်စာလုံး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
ချိတ်ဆက်ထားပြီးသော field များကို အလွယ်တကူ ခွဲခြားနိုင်ရန်နှင့် field အမည်များတူနေခြင်းကို ရှောင်ရှားနိုင်ရန်အတွက် ၎င်းတို့တွင် prefix (ရှေ့ဆက်စာလုံး) တစ်ခုပေါင်းထည့်ပါ။ |
Joined layer (ချိတ်ဆက်ထားပြီးသော layer) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ချိတ်ဆက်ခြင်းအတွက် output vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Unjoinable features from first layer (ပထမ layer မှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ပထမ layer မှ ပေါင်းစပ်ခြင်းမပြုနိုင်သော feature များအတွက် output vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Number of joined features from input table (Input ဇယားမှ ချိတ်ဆက်ထားပြီးသော feature များအရေအတွက်) |
|
[number] |
|
Unjoinable features from first layer (ပထမ layer မှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
မကိုက်ညီသည့် feature များပါဝင်သော vector layer |
Joined layer (ချိတ်ဆက်ထားပြီးသော layer) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ချိတ်ဆက်မှုမှ ပေါင်းထည့်ထားသော attribute များပါဝင်သည့် output vector layer |
Number of unjoinable features from input table (Input ဇယားမှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များအရေအတွက်) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[number] |
Python code
Algorithm ID: native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.19. တည်နေရာအရ attribute များကို ချိတ်ဆက်ခြင်း (Join attributes by location)
Input vector layer တစ်ခုကိုယူပြီး ၎င်း၏ attribute ဇယားထဲတွင် ထပ်ဆောင်း attribute များဖြင့် ထပ်တိုးထားသော vector layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
ထပ်ဆောင်း attribute များနှင့် ၎င်းတို့၏တန်ဖိုးများကို ဒုတိယ vector layer တစ်ခုမှရယူမည်ဖြစ်သည်။ ပထမ layer မှ feature တစ်ခုချင်းစီသို့ ပေါင်းထည့်သော ဒုတိယ layer မှ တန်ဖိုးများကို ရွေးချယ်ရန် တည်နေရာဆိုင်ရာစံနှုန်း (spatial criteria) ကိုအသုံးပြုပါသည်။
Default menu-
See also
နီးစပ်မှုဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (Join attributes by nearest) ၊ Field တန်ဖိုးဖြင့် attribute များကို ချိတ်ဆက်ခြင်း (Join attributes by field value) ၊ Join attributes by location (summary) (တည်နေရာအားဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (အကျဉ်းချုပ်))
တည်နေရာဆိုင်ရာ ဆက်နွယ်မှုများကို လေ့လာခြင်း (Exploring spatial relations)
Geometric predicate ဆိုသည်မှာ feature တစ်ခုနှင့် အခြား feature တစ်ခု၏ တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ၎င်းတို့၏ ဂျီဩမေတြီများမည်သို့ မျှဝေနေရာယူနေသလဲဆိုသည်ကို နှိုင်းယှဉ်ခြင်းအားဖြင့် ဆုံးဖြတ်ရန်အသုံးပြုသော boolean (မှန်/မှား) function များကို ဆိုလိုပါသည်။
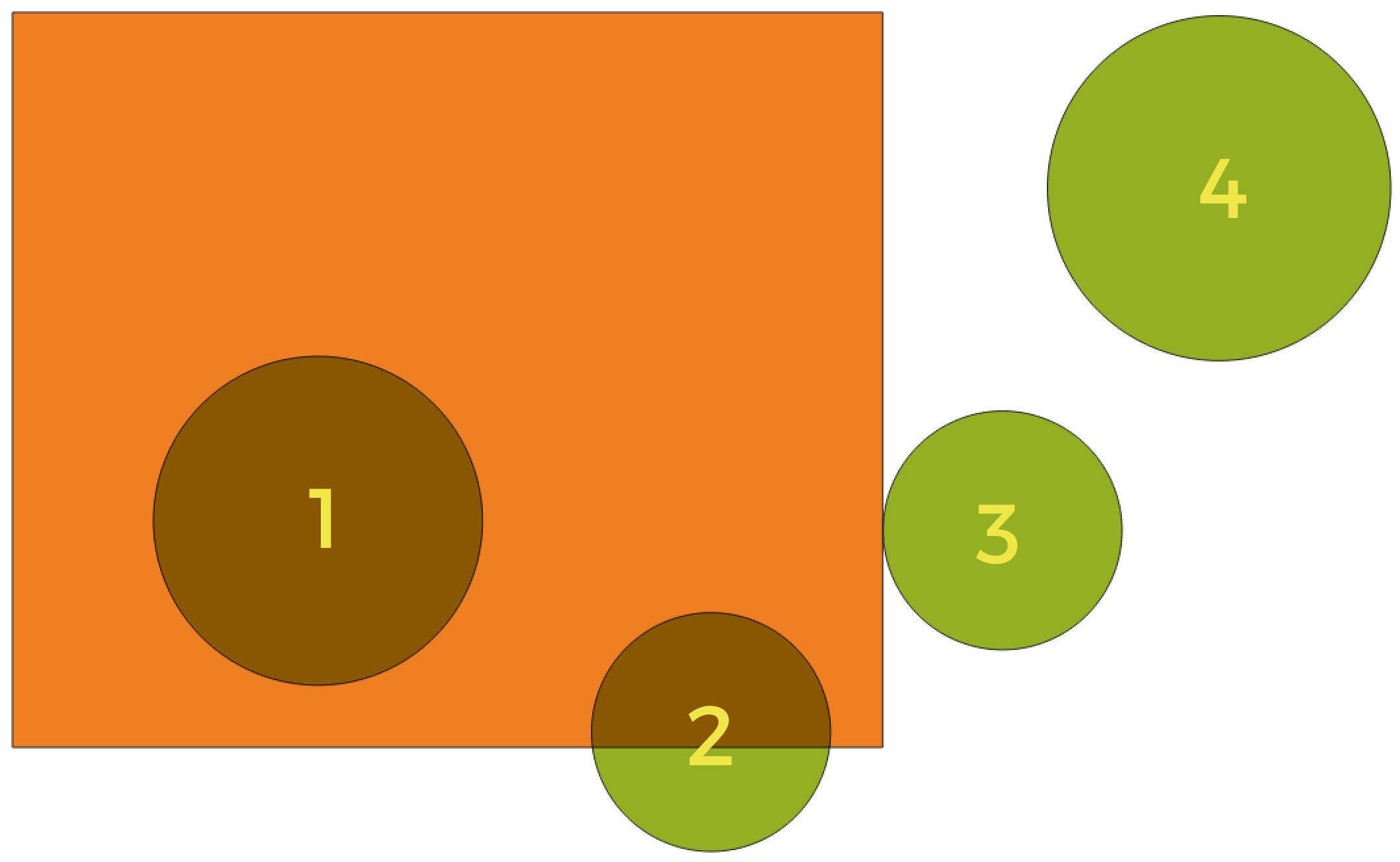
Fig. 29.48 Layer များအကြား တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ရှာဖွေခြင်း
အထက်ဖော်ပြပါပုံကိုအသုံးပြုပြီး လိမ္မော်ရောင် ထောင့်မှန်စတုဂံ feature များကို အစိမ်းရောင်စက်ဝိုင်းများနှင့် တည်နေရာအရ နှိုင်းယှဉ်ပြီး အစိမ်းရောင်စက်ဝိုင်းများကို ရှာဖွေပါသည်။ အသုံးပြုနိုင်သော geometric predicate များမှာ-
- Intersect (ထိဖြတ်ခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့်ထိဖြတ်/မဖြတ်ကို စစ်ဆေးပေးပါသည်။ ထိဖြတ်နေလျှင် (နေရာအစိတ်အပိုင်းတစ်ခုကိုမျှဝေသုံးစွဲခြင်း - ထပ်နေခြင်း သို့မဟုတ် ထိနေခြင်း ကိုဆိုလိုပါသည်) 1 (အမှန်) တန်ဖိုးကို ထုတ်ပေးပြီး မဖြစ်လျှင် 0 တန်ဖိုးကိုထုတ်ပေးပါသည်။ အထက်ဖော်ပြပါ ဓာတ်ပုံတွင် စက်ဝိုင်း 1၊ 2 နှင့် 3 တို့ကိုထုတ်ပေးပါသည်။
- Contain (ပါဝင်ခြင်း)
b ၏အမှတ်များသည် a ၏အပြင်ဘက်တွင် မရှိလျှင်နှင့် မရှိမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပြီး အနည်းဆုံး b ၏အတွင်းဘက်ကတစ်မှတ်သည် a ၏အတွင်းဘက်တွင် ရှိရပါမည်။ ပုံတွင် မည်သည့်စက်ဝိုင်းမှ ပြန်ထုတ်မပေးပါ သို့သော် ၎င်းသည် စက်ဝိုင်း 1 အပြည့်အဝပါဝင်သောကြောင့် အခြားနည်းဖြင့်ရှာဖွေလျှင် ထောင့်မှန်စတုဂံ ကိုပြန်ထုတ်ပေးပါမည်။ ယခုနည်းလမ်းလည်း are within (အတွင်းတွင်ရှိခြင်း) နှင့် ဆန့်ကျင်ဘက်ဖြစ်ပါသည်။
- Disjoint (အဆက်ဖြုတ်ခြင်း)
ဂျီဩမေတြီ များသည် မည်သည့်အစိတ်အပိုင်းမျှ နေရာချင်းမျှဝေမနေလျှင် (ထပ်မနေ၊ ထိမနေခြင်း ကိုဆိုလိုပါသည်) တန်ဖိုး 1 (အမှန်) ကို ထုတ်ပေးပါမည်။ စက်ဝိုင်း 4 ကိုသာ ပြန်ထုတ်ပေးမည်ဖြစ်သည်။
- Equal (ညီမျှခြင်း)
ဂျီဩမေတြီ များသည်လုံးဝ တစ်ပုံစံတည်း တူနေလျှင် သို့မဟုတ် တူနေမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်းများကို ထုတ်မပေးပါ။
- Touch (ထိနေခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြားဂျီဩမေတြီ တစ်ခုနှင့် ထိ/မထိ စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် အနည်းဆုံး ဘုံ point တစ်ခုရှိနေပြီး ၎င်းတို့၏အတွင်းပိုင်းများသည် ထိဖြတ်မနေသောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 3 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Overlap (ထပ်နေခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့် ထပ်/မထပ် ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် နေရာခြင်း မျှဝေနေပြီး အရွယ်အစားလည်း တူညီနေသော်လည်း တစ်ခုထဲတွင် အခြားတစ်ခုက လုံးဝဝင်ရောက်နေခြင်း မဟုတ်လျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 2 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Are within (အတွင်းတွင်ရှိခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုအတွင်းတွင်ရှိ/မရှိ ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီ a သည် geometry b ၏အတွင်းတွင် လုံးဝကျရောက်နေလျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 1 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Cross (ကန့်လန့်ဖြတ်နေခြင်း)
အသုံးပြုထားသော ဂျီဩမေတြီ များသည် အားလုံးမဟုတ်တောင် အချို့သော အတွင်းပိုင်း ဘုံ point များရှိနေပြီး အမှန်တကယ် ကန့်လန့်ဖြတ်နေခြင်း သည် အမြင့်ဆုံး ဂျီဩမေတြီ ထက်နိမ့်သော dimension တစ်ခုတွင် ဖြစ်သောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ ဥပမာ- polygon တစ်ခုကိုဖြတ်သော line တစ်ခုသည် line အဖြစ် ကန့်လန့်ဖြတ်ပါမည် (အမှန်)။ ကန့်လန့်ဖြတ်နေသော line နှစ်ခုသည် point အဖြစ် ဖြတ်ပါလိမ့်မည် (အမှန်)။ Polygon နှစ်ခုသည် polygon တစ်ခုအဖြစ် ဖြတ်ပါလိမ့်မည် (အမှား)။ ဓာတ်ပုံတွင် စက်ဝိုင်းများကို ပြန်ထုတ်မပေးပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Join to features in |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer ။ Output layer တွင် ဤ layer မှ feature များ အပြင် ဒုတိယ layer မှကိုက်ညီသော feature များ၏ attribute များလည်း ပါဝင်ပါလိမ့်သည်။ |
Where the features |
|
[enumeration] [list] Default: [0] |
ရင်းမြစ် feature နှင့် ဦးတည်ရာ feature တို့အကြား ပေါင်းစပ်နိုင်စေရန်အတွက် ရှိသင့်သည့် တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relation) အမျိုးအစား ။ အောက်ပါရွေးချယ်စရာများထဲမှ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို၍ ရွေးချယ်နိုင်သည်-
အကယ်၍ အခြေအနေ တစ်ရပ်ထက်ပို၍ ရွေးချယ်ထားလျှင် အနည်းဆုံးတော့ ၎င်းတို့ထဲမှတစ်ခုသည် feature တစ်ခုအားထုတ်ယူရန် အခြေအနေနှင့်ကိုက်ညီမှုရှိရမည် (OR operation)။ |
By comparing to |
|
[vector: any] |
ချိတ်ဆက်မှု layer ။ ဤ vector layer မှ feature များသည် တည်နေရာဆိုင်ရာဆက်နွယ်မှုနှင့် ကိုက်ညီပါက ၎င်းတို့၏ attribute များကို ရင်းမြစ် layer attribute ဇယားသို့ ပေါင်းထည့် မည်ဖြစ်သည်။ |
Fields to add (leave empty to use all fields) (ပေါင်းထည့်မည့် Field များ (field များအားလုံးကိုအသုံးပြုရန် empty ထားရှိပါ)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] [list] |
ချိတ်ဆက်မှု layer မှ ပေါင်းထည့်လိုသော သီးသန့် field များကိုရွေးချယ်ပါ။ Default အားဖြင့်field များအားလုံးကို ပေါင်းထည့်မည်ဖြစ်သည်။ |
Join type (ချိတ်ဆက်မှု အမျိုးအစား) |
|
[enumeration] |
နောက်ဆုံး ချိတ်ဆက်ထားပြီးသော layer ၏ အမျိုးအစား။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
Discard records which could not be joined (ချိတ်ဆက်ခြင်းမပြုနိုင်သည့် မှတ်တမ်းများကိုဖျက်ခြင်း) |
|
[boolean] Default: False |
ချိတ်ဆက်ခြင်းမပြုနိုင်သော input layer ၏ feature များကို output မှ ဖယ်ရှားပေးပါသည်။ |
Joined field prefix (ချိတ်ဆက်ထားသော field ရှေ့ဆက်စာလုံး) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
ချိတ်ဆက်ထားသော field များကို အလွယ်တကူ ခွဲခြားသတ်မှတ်နိုင်ရန်နှင့် field အမည်များ တူနေခြင်းကိုရှောင်ရှားရန်အတွက် ၎င်း field များရှေ့တွင် prefix (ရှေ့ဆက်စာလုံး) တစ်ခုထည့်သွင်းပါ။ |
Joined layer (ချိတ်ဆက်ထားသော layer) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ချိတ်ဆက်မှုအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Unjoinable features from first layer (ပထမ layer မှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ပထမ layerမှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များအတွက် output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Number of joined features from input table (Input ဇယားမှ ချိတ်ဆက်ထားပြီးသော feature များ၏အရေအတွက်) |
|
[number] |
|
Unjoinable features from first layer (ပထမ layer မှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ကိုက်ညီမှုမရှိသော feature များ ပါဝင်သည့် vector layer |
Joined layer (ချိတ်ဆက်ထားသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ချိတ်ဆက်မှုမှ ပေါင်းထည့်ထားသော attribute များပါဝင်သည့် output vector layer |
Python code
Algorithm ID: native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.20. Join attributes by location (summary) (တည်နေရာအားဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (အကျဉ်းချုပ်))
Input vector layer တစ်ခုကိုယူပြီး ၎င်း၏ attribute ဇယားထဲတွင် ထပ်ဆောင်း attribute များဖြင့် ထပ်တိုးထားသော vector layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။
ထပ်ဆောင်း attribute များနှင့် ၎င်းတို့၏တန်ဖိုးများကို ဒုတိယ vector layer တစ်ခုမှရယူမည်ဖြစ်သည်။ ပထမ layer မှ feature တစ်ခုချင်းစီသို့ ပေါင်းထည့်သော ဒုတိယ layer မှ တန်ဖိုးများကို ရွေးချယ်ရန် တည်နေရာဆိုင်ရာစံနှုန်း (spatial criteria) ကိုအသုံးပြုပါသည်။
ဤ algorithm သည် ဒုတိယ layer ထဲရှိ ကိုက်ညီမှုရှိသော feature များမှတန်ဖိုးများအတွက် ကိန်းဂဏန်း အချက်အလက်ဆိုင်ရာ အကျဉ်းချုပ် ကိုတွက်ချက်ပေးပါသည် (ဥပမာအားဖြင့် အများဆုံးတန်ဖိုး၊ ပျမ်းမျှတန်ဖိုး အစရှိသည်)။
တည်နေရာဆိုင်ရာ ဆက်နွယ်မှုများကို လေ့လာခြင်း (Exploring spatial relations)
Geometric predicate ဆိုသည်မှာ feature တစ်ခုနှင့် အခြား feature တစ်ခု၏ တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ၎င်းတို့၏ ဂျီဩမေတြီများမည်သို့ မျှဝေနေရာယူနေသလဲဆိုသည်ကို နှိုင်းယှဉ်ခြင်းအားဖြင့် ဆုံးဖြတ်ရန်အသုံးပြုသော boolean (မှန်/မှား) function များကို ဆိုလိုပါသည်။
Fig. 29.49 Layer များအကြား တည်နေရာဆိုင်ရာဆက်နွယ်မှုကို ရှာဖွေခြင်း
အထက်ဖော်ပြပါပုံကိုအသုံးပြုပြီး လိမ္မော်ရောင် ထောင့်မှန်စတုဂံ feature များကို အစိမ်းရောင်စက်ဝိုင်းများနှင့် တည်နေရာအရ နှိုင်းယှဉ်ပြီး အစိမ်းရောင်စက်ဝိုင်းများကို ရှာဖွေပါသည်။ အသုံးပြုနိုင်သော geometric predicate များမှာ-
- Intersect (ထိဖြတ်ခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့်ထိဖြတ်/မဖြတ်ကို စစ်ဆေးပေးပါသည်။ ထိဖြတ်နေလျှင် (နေရာအစိတ်အပိုင်းတစ်ခုကိုမျှဝေသုံးစွဲခြင်း - ထပ်နေခြင်း သို့မဟုတ် ထိနေခြင်း ကိုဆိုလိုပါသည်) 1 (အမှန်) တန်ဖိုးကို ထုတ်ပေးပြီး မဖြစ်လျှင် 0 တန်ဖိုးကိုထုတ်ပေးပါသည်။ အထက်ဖော်ပြပါ ဓာတ်ပုံတွင် စက်ဝိုင်း 1၊ 2 နှင့် 3 တို့ကိုထုတ်ပေးပါသည်။
- Contain (ပါဝင်ခြင်း)
b ၏အမှတ်များသည် a ၏အပြင်ဘက်တွင် မရှိလျှင်နှင့် မရှိမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပြီး အနည်းဆုံး b ၏အတွင်းဘက်ကတစ်မှတ်သည် a ၏အတွင်းဘက်တွင် ရှိရပါမည်။ ပုံတွင် မည်သည့်စက်ဝိုင်းမှ ပြန်ထုတ်မပေးပါ သို့သော် ၎င်းသည် စက်ဝိုင်း 1 အပြည့်အဝပါဝင်သောကြောင့် အခြားနည်းဖြင့်ရှာဖွေလျှင် ထောင့်မှန်စတုဂံ ကိုပြန်ထုတ်ပေးပါမည်။ ယခုနည်းလမ်းလည်း are within (အတွင်းတွင်ရှိခြင်း) နှင့် ဆန့်ကျင်ဘက်ဖြစ်ပါသည်။
- Disjoint (အဆက်ဖြုတ်ခြင်း)
ဂျီဩမေတြီ များသည် မည်သည့်အစိတ်အပိုင်းမျှ နေရာချင်းမျှဝေမနေလျှင် (ထပ်မနေ၊ ထိမနေခြင်း ကိုဆိုလိုပါသည်) တန်ဖိုး 1 (အမှန်) ကို ထုတ်ပေးပါမည်။ စက်ဝိုင်း 4 ကိုသာ ပြန်ထုတ်ပေးမည်ဖြစ်သည်။
- Equal (ညီမျှခြင်း)
ဂျီဩမေတြီ များသည်လုံးဝ တစ်ပုံစံတည်း တူနေလျှင် သို့မဟုတ် တူနေမှသာ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်းများကို ထုတ်မပေးပါ။
- Touch (ထိနေခြင်း)
ဂျီဩမေတြီ တစ်ခုသည် အခြားဂျီဩမေတြီ တစ်ခုနှင့် ထိ/မထိ စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် အနည်းဆုံး ဘုံ point တစ်ခုရှိနေပြီး ၎င်းတို့၏အတွင်းပိုင်းများသည် ထိဖြတ်မနေသောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 3 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Overlap (ထပ်နေခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုနှင့် ထပ်/မထပ် ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီများသည် နေရာခြင်း မျှဝေနေပြီး အရွယ်အစားလည်း တူညီနေသော်လည်း တစ်ခုထဲတွင် အခြားတစ်ခုက လုံးဝဝင်ရောက်နေခြင်း မဟုတ်လျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 2 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Are within (အတွင်းတွင်ရှိခြင်း)
ဂျီဩမေတြီ သည် အခြား ဂျီဩမေတြီ တစ်ခုအတွင်းတွင်ရှိ/မရှိ ကို စစ်ဆေးပေးပါသည်။ ဂျီဩမေတြီ a သည် geometry b ၏အတွင်းတွင် လုံးဝကျရောက်နေလျှင် တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ စက်ဝိုင်း 1 ကိုသာ ပြန်ထုတ်ပေးပါသည်။
- Cross (ကန့်လန့်ဖြတ်နေခြင်း)
အသုံးပြုထားသော ဂျီဩမေတြီ များသည် အားလုံးမဟုတ်တောင် အချို့သော အတွင်းပိုင်း ဘုံ point များရှိနေပြီး အမှန်တကယ် ကန့်လန့်ဖြတ်နေခြင်း သည် အမြင့်ဆုံး ဂျီဩမေတြီ ထက်နိမ့်သော dimension တစ်ခုတွင် ဖြစ်သောအခါ တန်ဖိုး 1 (အမှန်) ကိုထုတ်ပေးပါသည်။ ဥပမာ- polygon တစ်ခုကိုဖြတ်သော line တစ်ခုသည် line အဖြစ် ကန့်လန့်ဖြတ်ပါမည် (အမှန်)။ ကန့်လန့်ဖြတ်နေသော line နှစ်ခုသည် point အဖြစ် ဖြတ်ပါလိမ့်မည် (အမှန်)။ Polygon နှစ်ခုသည် polygon တစ်ခုအဖြစ် ဖြတ်ပါလိမ့်မည် (အမှား)။ ဓာတ်ပုံတွင် စက်ဝိုင်းများကို ပြန်ထုတ်မပေးပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Join to features in |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer ။ Output layer တွင် ဤ layer မှ feature များ အပြင် ဒုတိယ layer မှကိုက်ညီသော feature များ၏ attribute များလည်း ပါဝင်ပါလိမ့်သည်။ |
Where the features |
|
[enumeration] [list] Default: [0] |
ရင်းမြစ် feature နှင့် ဦးတည်ရာ feature တို့အကြား ပေါင်းစပ်နိုင်စေရန်အတွက် ရှိသင့်သည့် တည်နေရာဆိုင်ရာဆက်နွယ်မှု (spatial relation) အမျိုးအစား ။ အောက်ပါရွေးချယ်စရာများထဲမှ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို၍ ရွေးချယ်နိုင်သည်-
အကယ်၍ အခြေအနေ တစ်ရပ်ထက်ပို၍ ရွေးချယ်ထားလျှင် အနည်းဆုံးတော့ ၎င်းတို့ထဲမှတစ်ခုသည် feature တစ်ခုအားထုတ်ယူရန် အခြေအနေနှင့်ကိုက်ညီမှုရှိရမည် (OR operation)။ |
By comparing to |
|
[vector: any] |
ချိတ်ဆက်မှု layer ။ ဤ vector layer မှ feature များသည် တည်နေရာဆိုင်ရာဆက်နွယ်မှုနှင့် ကိုက်ညီပါက ၎င်းတို့၏ attribute များကို ရင်းမြစ် layer attribute ဇယားသို့ ပေါင်းထည့် မည်ဖြစ်သည်။ |
Fields to summarize (leave empty to use all fields) (အကျဉ်းချုပ်ပြုလုပ်ရန် Field များ (field များအားလုံးကိုအသုံးပြုရန်အတွက် empty ထားပါ)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[tablefield: any] [list] |
ချိတ်ဆက်မှု layer မှ ပေါင်းထည့်လိုသော သီးသန့် field များကိုရွေးချယ်ပါ။ Default အားဖြင့်field များအားလုံးကို ပေါင်းထည့်မည်ဖြစ်သည်။ |
Summaries to calculate (leave empty to use all fields) (တွက်ချက်ရမည့် အကျဉ်းချုပ်များ (field များအားလုံးကိုအသုံးပြုရန်အတွက် empty ထားပါ)) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[enumeration] [list] Default: [] |
Input feature တစ်ခုချင်းစီအတွက် ၎င်းတို့နှင့်ကိုက်ညီမှုရှိသော feature များ၏ ချိတ်ဆက်ထားသည့် field များပေါ်တွင် ကိန်းဂဏန်းအချက်အလက်များကိုတွက်ချက်မည်ဖြစ်သည်။ အောက်ပါရွေးချယ်စရာများထဲမှ တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို၍ ရွေးချယ်နိုင်သည်-
|
Discard records which could not be joined (ချိတ်ဆက်၍မရသော မှတ်တမ်းများကို ဖျက်ခြင်း) |
|
[boolean] Default: False |
ချိတ်ဆက်၍မရသော input layer ၏ feature များကို output မှ ဖယ်ရှားပါ။ |
Joined layer (ချိတ်ဆက်ထားသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ချိတ်ဆက်မှုအတွက် output vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Joined layer (ချိတ်ဆက်ထားသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ချိတ်ဆက်မှုမှ ရရှိလာသော အကျဉ်းချုပ် attribute များပါရှိသော output vector layer |
Python code
Algorithm ID: qgis:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.21. နီးစပ်မှုဖြင့် attribute များကိုချိတ်ဆက်ခြင်း (Join attributes by nearest)
Input vector layer တစ်ခုမှ ၎င်း၏ attribute ဇယားထဲတွင် ထပ်ဆောင်း field များ ထည့်သွင်းထားသော vector layer အသစ်တစ်ခုကို ဖန်တီးပေးပါသည်။ ထပ်ဆောင်း attributeများ နှင့် ၎င်းတို့၏တန်ဖိုးများကို ဒုတိယ vector layer မှရယူမည်ဖြစ်သည်။ Layer တစ်ခုချင်းစီမှ အနီးဆုံးသော feature များကိုရှာဖွေ၍ ချိတ်ဆက်ပေးခြင်းဖြစ်သည်။
Default အားဖြင့် အနီးစပ်ဆုံး feature ကိုသာသွား၍ ချိတ်ဆက်စေသော်လည်း k-nearest neighboring (K အရေအတွက် အနီးစပ်ဆုံးအနီးအနား) feature များနှင့်လည်း ချိတ်ဆက်နိုင်သည်။
အကယ်၍ အများဆုံးအကွာအဝေးတစ်ခုကိုသတ်မှတ်ထားပါက ထိုအကွာအဝေးထက်ပို၍ နီးကပ်သည့် feature များသာ ကိုက်ညီမည်ဖြစ်သည်။
See also
အနီးဆုံးအရာကိုလေ့လာဆန်းစစ်မှု (Nearest neighbour analysis) ၊ Field တန်ဖိုးဖြင့် attribute များကို ချိတ်ဆက်ခြင်း (Join attributes by field value) ၊ တည်နေရာအရ attribute များကို ချိတ်ဆက်ခြင်း (Join attributes by location) ၊ အကွာအဝေး မက်ထရစ် (Distance matrix)
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input layer (ထည့်သွင်းအသုံးပြုသော layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော layer |
Input layer 2 (ထည့်သွင်းအသုံးပြုသော ဒုတိယ layer) |
|
[vector: any] |
ချိတ်ဆက်မည့် layer |
Layer 2 fields to copy (leave empty to copy all fields) (မိတ္တူကူးယူရမည့် Layer 2 field များ (field အားလုံးကို မိတ္တူကူးယူရန် empty ထားပါ)) |
|
[fields] |
မိတ္တူကူးယူရမည့် Join layer field များ (အကယ်၍ ဗလာဖြစ်နေလျှင် field အားလုံးအား မိတ္တူကူးယူမည်ဖြစ်သည်) |
Discard records which could not be joined (ချိတ်ဆက်ခြင်းမပြုနိုင်သည့် မှတ်တမ်းများကို ဖျက်ခြင်း) |
|
[boolean] Default: False |
ချိတ်ဆက်ခြင်းမပြုနိုင်သည့် input layer မှတ်တမ်းများကို output မှ ဖယ်ရှားမည်ဖြစ်သည်။ |
Joined field prefix (ချိတ်ဆက်ထားသော field၏ ရှေ့ဆက်စာလုံး) |
|
[string] |
ချိတ်ဆက်ထားသော field ၏ prefix (ရှေ့ဆက်စာလုံး) |
Maximum nearest neighbors (အများဆုံးဖြစ်သည့် အနီးစပ်ဆုံး အနီးအနားများ) |
|
[number] Default: 1 |
အနီးစပ်ဆုံး အနီးအနားများ၏ အများဆုံးအရေအတွက် |
Maximum distance (အများဆုံး အကွာအဝေး) |
|
[number] |
အများဆုံး ရှာဖွေအကွာအဝေး |
Joined layer (ချိတ်ဆက်ပြီးသော layer) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ချိတ်ဆက်ပြီးသော feature များပါရှိသည့် vector layer ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
Unjoinable features from first layer (ပထမ layer မှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များပါဝင်သည့် vector layer အားသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Joined layer (ချိတ်ဆက်ပြီးသော layer) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
ရရှိလာသော ချိတ်ဆက်ပြီးသည့် layer |
Unjoinable features from first layer (ပထမ layer မှ ချိတ်ဆက်ခြင်းမပြုနိုင်သည့် feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Join Layer ရှိ မည်သည့် feature များနှင့်မျှ မချိတ်ဆက်နိုင်သော ပထမ Layer မှ feature များပါဝင်သည့် Layer |
Number of joined features from input table (Input ဇယားမှ ချိတ်ဆက်ပြီးသော feature များ၏အရေအတွက်) |
|
[number] |
Input ဇယားမှ ချိတ်ဆက်ထားပြီးသော feature များ၏အရေအတွက် |
Number of unjoinable features from input table (Input ဇယားမှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ၏အရေအတွက်) |
|
[number] |
Input ဇယားမှ ချိတ်ဆက်ခြင်းမပြုနိုင်သော feature များ၏အရေအတွက် |
Python code
Algorithm ID: native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.22. Vector layer များကိုပေါင်းခြင်း (Merge vector layers)
တူညီသော ဂျီဩမေတြီ အမျိုးအစားရှိသည့် မြောက်များစွာသော vector layer များကို တစ်ခုတည်းအဖြစ် ပေါင်းစပ်ပေးသည်။
ရရှိလာသော layer ၏ attribute ဇယားတွင် input layer များအားလုံးမှ field များ ပါဝင်မည်ဖြစ်သည်။ အကယ်၍ အမည်တူပြီး အမျိုးအစားမတူညီသော field များပါဝင်နေပါက export ထုတ်ထားသော field ကို string type (စာသားပုံစံ) field တစ်ခုအဖြစ်သို့ အလိုအလျောက်ပြောင်းလဲသွားမည်ဖြစ်သည်။ မူလ layer အမည် နှင့် အချက်အလက်အရင်းအမြစ်များ သိမ်းဆည်းထားသည့် field အသစ်များကိုလည်း ပေါင်းထည့်သွားမည်ဖြစ်သည်။
အကယ်၍ မည်သည့် input layer တွင်မဆို Z သို့မဟုတ် M တန်ဖိုးများပါဝင်ပါက output layer တွင်လည်း ထိုတန်ဖိုးများပါဝင်မည်ဖြစ်သည်။ အလားတူစွာ အကယ်၍ input layer များထဲမှတစ်ခုသည် multi-part(အစိတ်အပိုင်းများစွာပါရှိနေခြင်း) ဖြစ်လျှင် ရရှိလာသော layer သည်လည်း multi-part layer တစ်ခုဖြစ်လိမ့်မည်။
ထို့အပြင် ပေါင်းစပ်လိုက်သော layer အတွက် ဦးတည်အသုံးပြုမည့် coordinate reference system (CRS)ကို သတ်မှတ်နိုင်သည်။ အကယ်၍ မသတ်မှတ်ထားပါက CRS အား ပထမဆုံး input layer အတိုင်းအသုံးပြုမည်ဖြစ်သည်။ ၎င်း CRS နှင့်ကိုက်ညီမှုရှိစေရန် layer အားလုံးအား projection တစ်ခုမှတစ်ခုသို့ ပြောင်းလဲပေးမည်ဖြစ်သည်။
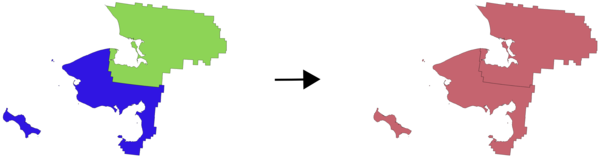
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layers (ထည့်သွင်းအသုံးပြုသော Layer များ) |
|
[vector: any] [list] |
တစ်ခုတည်းသော layer အဖြစ် ပေါင်းစပ်ရမည့် layerများ ။ Layer များတွင် တူညီသော ဂျီဩမေတြီအမျိုးအစား ရှိရမည်။ |
Destination CRS (ဦးတည်အသုံးပြုမည့် CRS) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[crs] |
Output layer အတွက် CRS ကိုရွေးချယ်ပါ။ မသတ်မှတ်ထားလျှင် ပထမဆုံး input layer ၏ CRS ကိုအသုံးပြုမည်။ |
Merged (ပေါင်းစပ်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကို သတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Merged (ပေါင်းစပ်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Input layer များမှ feature များအားလုံးနှင့် attribute များအားလုံး ပါဝင်သော output vector layer |
Python code
Algorithm ID: native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.23. Expression ဖြင့်အထက်အောက်ုစီခြင်း (Order by expression)
Expression တစ်ခုအပေါ် အခြေခံ၍ vector layer တစ်ခုကို sort (စဉ်) လုပ်ပေးပါသည်- expression တစ်ခုပေါ် အခြေခံ၍ feature index ကိုပြောင်းလဲပေးမည်ဖြစ်သည်။
သတိပြုရမည်မှာ ၎င်းသည် အချို့ provider များနှင့် မျှော်လင့်ထားသလို အလုပ်ဖြစ်နိုင်မည်မဟုတ်ဘဲ order (အစီအစဉ်) သည်လည်းအချိန်တိုင်း တသမတ်တည်း ရှိနေမည်မဟုတ်ပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
Sort (စဉ်) လုပ်ရမည့် ထည့်သွင်းအသုံးပြုသော vector layer |
Expression (စေခိုင်းချက်) |
|
[expression] |
Sorting အတွက် အသုံးပြုရမည့် Expression |
Sort ascending (ငယ်စဉ်ကြီးလိုက်စဉ်ခြင်း) |
|
[boolean] Default: True |
အကယ်၍ အမှန်ခြစ်ပေးထားပါက vector layer တန်ဖိုးများကို ငယ်ရာမှ ကြီးရာသို့ စဉ်ပေးမည်ဖြစ်သည်။ |
Sort nulls first (Null တန်ဖိုးများကို ဦးစွာစဉ်ခြင်း) |
|
[boolean] Default: False |
အကယ်၍ အမှန်ခြစ်ပေးထားပါက Null တန်ဖိုးများကို ဦးစွာ စဉ်ပေးမည်ဖြစ်သည်။ |
Ordered (စီစဉ်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Ordered (စီစဉ်ထားပြီးသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Output (စဉ်ထားသော) vector layer |
Python code
Algorithm ID: native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.24. Shapefile အပျက်အား ပြန်လည်ပြုပြင်ခြင်း (Repair Shapefile)
SHX file အား (ပြန်လည်) ဖန်တီးခြင်းဖြင့် ပျက်စီးနေသော ESRI Shapefile dataset တစ်ခုအား ပြန်လည်ပြုပြင်ပေးပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Shapefile (ထည့်သွင်းအသုံးပြုသော Shapefile) |
|
[file] |
ပျောက်ဆုံးနေသော သို့မဟုတ် ပျက်စီးနေသော SHX file တစ်ခုရှိသည့် ESRI Shapefile dataset ရှိရာ ဖိုင်လမ်းကြောင်း အပြည့်အစုံ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Repaired layer (ပြန်လည်ပြုပြင်ထားသော layer) |
|
[vector: any] |
ပြန်လည်ပြုပြင်ထားသော SHX file ပါဝင်သည့် input vector layer |
Python code
Algorithm ID: native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.25. Layer ကို projection ပြောင်းခြင်း (Reproject layer)
Vector layer တစ်ခုကို အခြားမတူညီသော CRS (Coordinate Reference System) သို့ projection ပြောင်းလဲပေးပါသည်။ Reprojection လုပ်ထားသော layer တွင် input layer ကဲ့သို့ပင် တူညီသော feature များနှင့် attribute များရှိပါလိမ့်မည်။
တွင်အမှတ်ခြစ်ပေးထားခြင်းဖြင့် point ၊ line နှင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း) ရွေးချယ်ခွင့်ကိုအသုံးပြုနိုင်သည်။
See also
မြေပုံအရိပ်ချစနစ် သတ်မှတ်ခြင်း (Assign projection) ၊ Shapefile ၏ projection သတ်မှတ်ခြင်း (Define Shapefile projection) ၊ Projection ရှာဖွေခြင်း (Find projection)
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
Reproject ပြုလုပ်မည့် input vector layer |
Target CRS (ဦးတည်အသုံးပြုမည့် CRS) |
|
[crs] Default: |
ဦးတည်အသုံးပြုမည့် ရည်ညွှန်းကိုဩဒိနိတ်စနစ် |
Convert curved geometries to straight segments (မျဉ်းကွေးဂျီဩမေတြီများအား မျဉ်းပိုင်းအဖြောင့်များအဖြစ်ပြောင်းလဲခြင်း)
Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[boolean] Default: False |
အမှန်ခြစ်ထားပါက မျဉ်းကွေးဂျီဩမေတြီများသည် လုပ်ငန်းစဉ်အတွင်းတွင် မျဉ်းပိုင်းအဖြောင့်များအဖြစ်ပြောင်းလဲသွားမည်ဖြစ်ပြီး ဖြစ်နိုင်ချေရှိသော ပုံပျက်တွန့်လိမ်သွားသည့် ပြဿနာများကို ရှောင်ရှားနိုင်မည်ဖြစ်သည်။ |
Reprojected (Projection ပြောင်းထားသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Coordinate Operation (ကိုသြဒိနိတ် လုပ်ဆောင်မှု) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
လက်ရှိ project ၏ အသွင်ပြောင်းလဲခြင်း (transformation) setting များကို အမြဲတမ်းအသုံးပြုနေမည့်အစား သီးသန့် reprojection လုပ်ငန်းစဉ်တစ်ခုအတွက် အသုံးပြုမည့် သီးသန့်လုပ်ဆောင်မှု။ ၎င်းသည် သီးခြား layer တစ်ခုကို reprojection ပြုလုပ်ပြီး ထိုပြောင်းလဲခြင်းအပေါ်တွင် အသေးစိတ် ချိန်ညှိထိန်းချုပ်ရန်လိုအပ်ပါက အသုံးဝင်ပါသည်။ proj version >= 6 (6နှင့်အထက်) ဖြစ်ရန်လိုအပ်သည်။ ပိုမိုသိရှိလိုပါက ရည်ညွှန်းမျက်နှာပြင် ပြောင်းခြင်း (Datum Transformations) တွင်ဖတ်ရှုပါ။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Reprojected (Projection ပြောင်းထားသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Output (Projection ပြောင်းထားသော) vector layer |
Python code
Algorithm ID: native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.26. Vector feature များကို File အဖြစ်သိမ်းဆည်းခြင်း (Save vector features to file)
Vector feature များကို သတ်မှတ်ထားသော file dataset ထဲတွင် သိမ်းဆည်းပေးပါသည်။
Dataset format များကို အသုံးပြုနိုင်သည့် layer များအတွက် layer အမည်အတွက် parameter တစ်ခုကိုအသုံးပြုခြင်းဖြင့် စိတ်ကြိုက်စာသားတစ်ခုကိုသတ်မှတ်နိုင်သည်။ GDAL မှသတ်မှတ်ထားသော dataset များနှင့် layer ရွေးချယ်စရာများကိုလည်း သတ်မှတ်ပေးနိုင်ပါသည်။ ပိုမိုသိရှိလိုသည့်အချက်အလက်များအတွက် အွန်လိုင်းမှ GDAL documentation တွင်ဖတ်ရှုနိုင်ပါသည်။
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Vector features (Vector feature များ) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Saved features (သိမ်းဆည်းထားသော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Feature များကိုသိမ်းဆည်းမည့် file ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Layer name (Layer အမည်) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Output layer အတွက် အသုံးပြုမည့် အမည် |
GDAL dataset options Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Output format ၏ GDAL dataset ဖန်တီးခြင်း ရွေးချယ်စရာများ။ Semicolon (;) များဖြင့် ရွေးချယ်စရာတစ်ခုချင်းစီအား ခွဲခြားထားပါသည်။ |
GDAL layer options Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[string] |
Output format ၏ GDAL layer ဖန်တီးခြင်း ရွေးချယ်စရာများ။ Semicolon (;) များဖြင့် ရွေးချယ်စရာတစ်ခုချင်းစီအား ခွဲခြားထားပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Saved features (သိမ်းဆည်းထားသော feature များ) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
သိမ်းဆည်းထားသော feature များပါရှိသည့် vector layer |
File name and path (File အမည် နှင့် လမ်းကြောင်း) |
|
[string] |
Output file အမည်နှင့်လမ်းကြောင်း |
Layer name (Layer အမည်) |
|
[string] |
Layer ၏အမည် |
Python code
Algorithm ID: native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.27. Layer encoding ကိုသတ်မှတ်ခြင်း (Set layer encoding)
Layer တစ်ခု၏ attribute များကို ဖတ်ရှုရန်အတွက် အသုံးပြုမည့် encoding ကို သတ်မှတ်ပေးပါသည်။ Layer အား အပြီးတိုင်ပြောင်းလဲခြင်းမဟုတ်ဘဲ လက်ရှိ session အတွင်းတွင် layer ကိုမည်သို့ ဖတ်ရှုမည် ဆိုသည်ကိုသာ အကျိုးသက်ရောက်စေမည်ဖြစ်သည်။
Note
Encoding ပြောင်းလဲခြင်းကို အချို့ vector layer data ရင်းမြစ်များတွင်သာ အသုံးပြုနိုင်မည်ဖြစ်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Saved features (သိမ်းဆည်းထားသော feature များ) |
|
[vector: any] |
Encoding အားသတ်မှတ်မည့် vector layer |
Encoding |
|
[string] |
လက်ရှိ QGIS session ထဲ၌ layer တွင် သတ်မှတ်ပေးမည့် စာသား encoding |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Output layer |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
သတ်မှတ်ထားသော encoding ပါဝင်သည့် input vector layer |
Python code
Algorithm ID: native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.28. သတ်မှတ်စာလုံးတစ်ခုဖြင့် feature များကို ပိုင်းခြားခြင်း (Split features by character)
သတ်မှတ်ထားသော စာလုံးသင်္ကေတတစ်ခုတွင် field တစ်ခု၏တန်ဖိုးကို ပိုင်းခြားခြင်းဖြင့် Feature များကို output feature များစွာအဖြစ်သို့ ပိုင်းခြားပေးမည်ဖြစ်သည်။ ဥပမာအားဖြင့် layer တစ်ခုတွင် feature များပါရှိပြီး ၎င်း feature များသည် field တစ်ခုထဲ၌ comma ဖြင့်ခွဲခြားထားသော တန်ဖိုးများစွာပါဝင်နေလျှင် ဤ algorithm အားအသုံးပြု၍ ၎င်းတန်ဖိုးများအား များစွာသော output feature များအဖြစ် ပိုင်းခြားနိုင်သည်။ Output ထဲတွင် ဂျီဩမေတြီများနှင့် အခြား attribute များသည်မပြောင်းလဲပဲ ကျန်ရှိနေမည်ဖြစ်သည်။ နောက်ထပ်ရွေးချယ်စရာအနေနှင့် Feature များကိုခွဲရာတွင် ပြောင်းလွယ်ပြင်လွယ်ဖြစ်စေရန်အတွက် separator string သည် ပုံမှန် expression တစ်ခုဖြစ်နိုင်ပါသည်။
တွင်အမှန်ခြစ်ပေးခြင်းဖြင့် point ၊ line နှင့် polygon feature များအတွက် features in-place modification (နေရာတွင် feature များကို မွမ်းမံပြင်ဆင်ခြင်း ကိုရွေးချယ်နိုင်သည်။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Split using values in the field (Field ထဲရှိ တန်ဖိုးများကိုအသုံးပြု၍ ပိုင်းခြားခြင်း) |
|
[tablefield: any] |
ပိုင်းခြားခြင်းအတွက် အသုံးပြုမည့် Field |
Split value using character (စာလုံးသင်္ကေတများအသုံးပြု၍ တန်ဖိုးများကို ပိုင်းခြားခြင်း) |
|
[string] |
ပိုင်းခြားခြင်းအတွက် အသုံးပြုမည့် စာလုံးသင်္ကေတများ |
Use regular expression separator (Regular expression separator အားအသုံးပြုခြင်း) |
|
[boolean] Default: False |
|
Split (ပိုင်းခြားထားသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] Default: |
Output vector layer ကိုသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
File encoding ကိုလည်းဤနေရာတွင်ပြောင်းလဲနိုင်ပါသည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Split (ပိုင်းခြားထားသော) |
|
[input နှင့်အတူတူဖြစ်ပါသည်] |
Output vector layer |
Python code
Algorithm ID: native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.29. Vector layer တွင် ပိုင်းခြားခြင်း (Split vector layer)
Input layer တစ်ခုနှင့် attribute တစ်ခုပေါ်တွင်အခြေခံ၍ vector များအစုအဝေးတစ်ခုကို output folder ထဲတွင်ဖန်တီးပေးပါသည်။ အလိုရှိသော field ထဲရှိ unique တန်ဖိုးများ တွေ့ရှိရသလောက်အရေအတွက်အတိုင်း output folder ထဲတွင် layer များပါဝင်ပါလိမ့်မည်။
ထွက်ရှိလာသော file များ၏အရေအတွက်သည် သတ်မှတ်ထားသော attribute အတွက် ကွဲပြားသော တန်ဖိုးများ၏အရေအတွက်နှင့် တူညီမည်ဖြစ်သည်။
၎င်းသည် merging လုပ်ငန်းစဉ်နှင့် ဆန့်ကျင်ဘက်ဖြစ်သည်။
Default menu-
သတ်မှတ်ချက်များ (Parameters)
အခြေခံ သတ်မှတ်ချက်များ (Basic parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
Unique ID field |
|
[tablefield: any] |
ပိုင်းခြားခြင်းအတွက် အသုံးပြုမည့် Field |
Output directory (ရလာဒ်များ သိမ်းဆည်းရာ ဖိုင်လမ်းကြောင်း) |
|
[folder] Default: |
Output layer များအတွက် ဖိုင်လမ်းကြောင်းသတ်မှတ်ပါ။ အောက်ပါတို့ထဲမှ တစ်ခုဖြစ်ပါသည်-
|
အဆင့်မြင့် သတ်မှတ်ချက်များ (Advanced parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Output file type (ရလာဒ်ဖိုင်အမျိုးအစား) Optional (မဖြစ်မနေလုပ်ဆောင်ရန်မလိုပါ) |
|
[enumeration] Default: Dialog window ထဲရှိ |
Output file များ၏ extension ကို ရွေးချယ်ပါ။ အကယ်၍ မရွေးချယ်ထားလျှင် သို့မဟုတ် ကိုက်ညီမှုမရှိလျှင် output file များအား “Default output vector layer extension” Processing setting ထဲတွင်သတ်မှတ်ထားသော format အတိုင်း အသုံးပြုမည်ဖြစ်သည်။ |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Output directory (ရလာဒ်များ သိမ်းဆည်းရာ ဖိုင်လမ်းကြောင်း) |
|
[folder] |
Output layer များအတွက် ဖိုင်လမ်းကြောင်း |
Output layers |
|
[input နှင့်အတူတူဖြစ်ပါသည်] [list] |
ပိုင်းခြားခြင်းမှရရှိလာသော output vector layer များ |
Python code
Algorithm ID: native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။
29.1.17.30. အလွှာတစ်ခုကိုရှင်းလင်းခြင်း (Truncate table)
Layer တစ်ခုအား ၎င်းအတွင်းရှိ feature အားလုံးကိုဖျက်ခြင်းဖြင့် ရှင်းလင်းပေးပါသည်။
Warning
ဤ algorithm အသုံးပြုပါက layer အား ၎င်းနေရာတွင်ပင် ပြင်ဆင်ပြောင်းလဲလိုက်မည်ဖြစ်ပြီး ဖျက်လိုက်သော feature များကို ပြန်လည်ရယူနိုင်မည်မဟုတ်ပါ။
သတ်မှတ်ချက်များ (Parameters)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Input Layer (ထည့်သွင်းအသုံးပြုသော Layer) |
|
[vector: any] |
ထည့်သွင်းအသုံးပြုသော vector layer |
ရလာဒ်များ (Outputs)
အညွှန်း |
အမည် |
အမျိုးအစား |
ရှင်းလင်းဖော်ပြချက် |
|---|---|---|---|
Truncated layer (ရှင်းလင်းထားသော layer) |
|
[folder] |
ရှင်းလင်းထားသော (ဗလာဖြစ်နေသည့်) layer |
Python code
Algorithm ID: native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
Processing Toolbox ထဲရှိ algorithm ပေါ်တွင် mouse ကိုတင်ထားလျှင် algorithm id ကိုပြသပေးပါသည်။ parameter dictionary သည် parameter နာမည်များနှင့် တန်ဖိုးများကို ပေးပါသည်။ Python console မှ algorithm များကို မည်သို့လုပ်ဆောင်ရမည် ဆိုသည့် အသေးစိတ်ကို သိရှိလိုလျှင် Console တွင် processing algorithm များကို အသုံးပြုခြင်း တွင်ကြည့်ပါ။